This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This results in an imbalanced class distribution for training and test datasets.
Learning must be ongoing and fast As ChatGPTs FAQ notes , it was trained on vast amounts of data with extensive human oversight and supervision along the way. Unclear ROI ChatGPT is currently not accessible via API and the cost of a (hypythetical) API call are unclear.
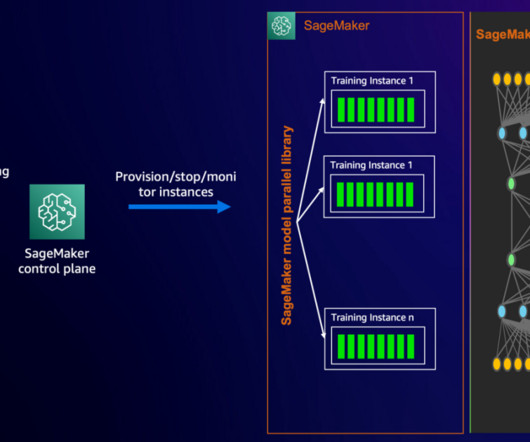
Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. This approach reduces memory pressure and enables efficient training of large models.
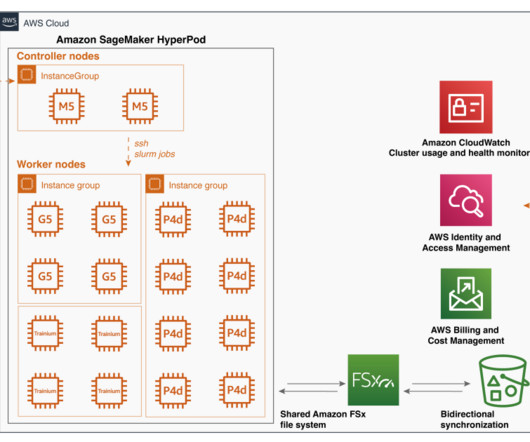
You need trained people and specialized equipment, and you often must shut things down during inspection. Each drone follows predefined routes, with flight waypoints, altitude, and speed configured through an AWS API, using coordinates stored in Amazon DynamoDB. The following diagram outlines how different components interact.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. Incoming requests to the gateway go through this point.
For their AI training and inference workloads, Adobe uses NVIDIA GPU-accelerated Amazon Elastic Compute Cloud (Amazon EC2) P5en (NVIDIA H200 GPUs), P5 (NVIDIA H100 GPUs), P4de (NVIDIA A100 GPUs), and G5 (NVIDIA A10G GPUs) instances. To train generative AI models at enterprise scale, ServiceNow uses NVIDIA DGX Cloud on AWS.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
GraphStorm is a low-code enterprise graph machine learning (GML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. allows you to define multiple training targets on different nodes and edges within a single training loop. Specifically, GraphStorm 0.3
To enable the video insights solution, the architecture uses a combination of AWS services, including the following: Amazon API Gateway is a fully managed service that makes it straightforward for developers to create, publish, maintain, monitor, and secure APIs at scale.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
By utilizing sparse expert subnetworks that process different subsets of tokens, MoE models can effectively increase the number of parameters while requiring less computation per token during training and inference. This enables more cost-effective training of larger models within fixed compute budgets compared to dense architectures.
Demystifying RAG and model customization RAG is a technique to enhance the capability of pre-trained models by allowing the model access to external domain-specific data sources. Unlike fine-tuning, in RAG, the model doesnt undergo any training and the model weights arent updated to learn the domain knowledge.
Amazon SageMaker JumpStart is a machine learning (ML) hub that provides pre-trained models, solution templates, and algorithms to help developers quickly get started with machine learning. For a list of available models, refer to Built-in Algorithms with pre-trained Model Table. No model artifacts need to be managed by the customer.
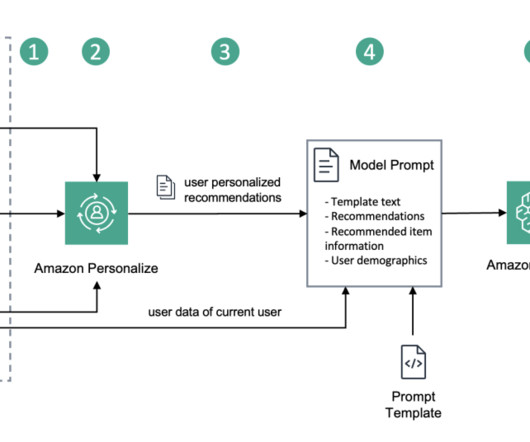
You can get started without any prior machine learning (ML) experience, and Amazon Personalize allows you to use APIs to build sophisticated personalization capabilities. Train an Amazon Personalize Top picks for you recommender. You start by creating your dataset group, loading your data, and then training a recommender.
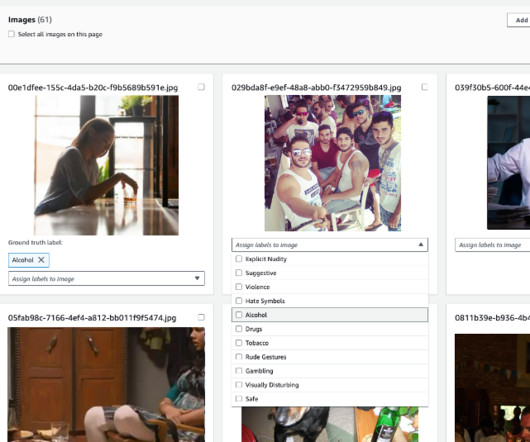
In this post, we discuss how to use the Custom Moderation feature in Amazon Rekognition to enhance the accuracy of your pre-trained content moderation API. You can train a custom adapter with as few as 20 annotated images in less than 1 hour. Create a project A project is a container to store your adapters.
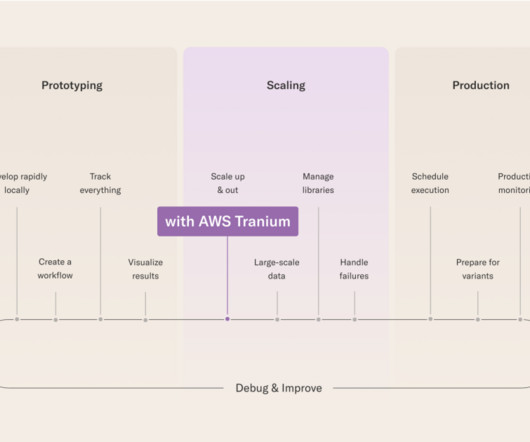
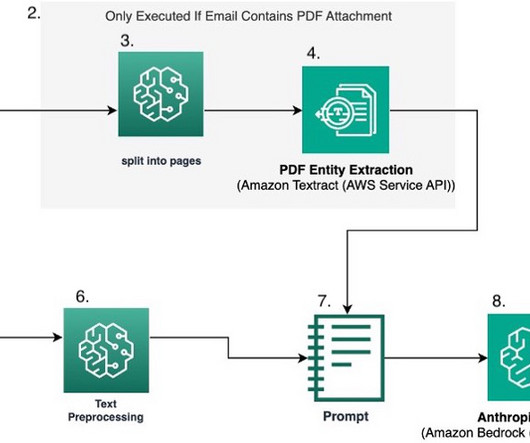
This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models. The following figure illustrates this workflow.
In recent years, large language models (LLMs) have gained attention for their effectiveness, leading various industries to adapt general LLMs to their data for improved results, making efficient training and hardware availability crucial. In this post, we show you how efficient we make our continual pre-training by using Trainium chips.
Similarly, maintaining detailed information about the datasets used for training and evaluation helps identify potential biases and limitations in the models knowledge base. It functions as a standalone HTTP server that provides various REST API endpoints for monitoring, recording, and visualizing experiment runs.
Many use cases involve using pre-trained large language models (LLMs) through approaches like Retrieval Augmented Generation (RAG). Fine-tuning is a supervised training process where labeled prompt and response pairs are used to further train a pre-trained model to improve its performance for a particular use case.
Contrast that with Scope 4/5 applications, where not only do you build and secure the generative AI application yourself, but you are also responsible for fine-tuning and training the underlying large language model (LLM). These steps might involve both the use of an LLM and external data sources and APIs.
Enabling Global Resiliency for an Amazon Lex bot is straightforward using the AWS Management Console , AWS Command Line Interface (AWS CLI), or APIs. Global Resiliency APIs Global Resiliency provides API support to create and manage replicas. To better understand the solution, refer to the following architecture diagram.
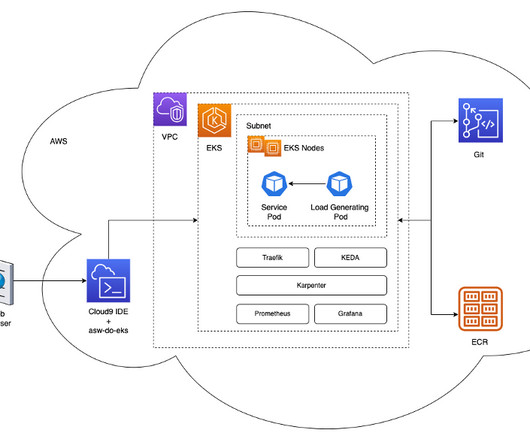
In this post, we focus on how we used Karpenter on Amazon Elastic Kubernetes Service (Amazon EKS) to scale AI training and inference, which are core elements of the Iambic discovery platform. We wanted to build a scalable system to support AI training and inference. per training task 20 minutes average $0.38
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business. config_yaml = f""" SchemaVersion: '1.0'
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
The Amazon Bedrock single API access, regardless of the models you choose, gives you the flexibility to use different FMs and upgrade to the latest model versions with minimal code changes. Amazon Titan FMs provide customers with a breadth of high-performing image, multimodal, and text model choices, through a fully managed API.
Large language models (LLMs) are generally trained on large publicly available datasets that are domain agnostic. For example, Meta’s Llama models are trained on datasets such as CommonCrawl , C4 , Wikipedia, and ArXiv. The resulting LLM outperforms LLMs trained on non-domain-specific datasets when tested on finance-specific tasks.
Discover how the fully managed infrastructure of SageMaker enables high-performance, low cost ML throughout the ML lifecycle, from building and training to deploying and managing models at scale. AWS Trainium and AWS Inferentia deliver high-performance AI training and inference while reducing your costs by up to 50%.
Agent architecture The following diagram illustrates the serverless agent architecture with standard authorization and real-time interaction, and an LLM agent layer using Amazon Bedrock Agents for multi-knowledge base and backend orchestration using API or Python executors. Domain-scoped agents enable code reuse across multiple agents.
This text-to-video API generates high-quality, realistic videos quickly from text and images. Trained on the Amazon SageMaker HyperPod , Dream Machine excels in creating consistent characters, smooth motion, and dynamic camera movements. Luma AI’s recently launched Dream Machine represents a significant advancement in this field.
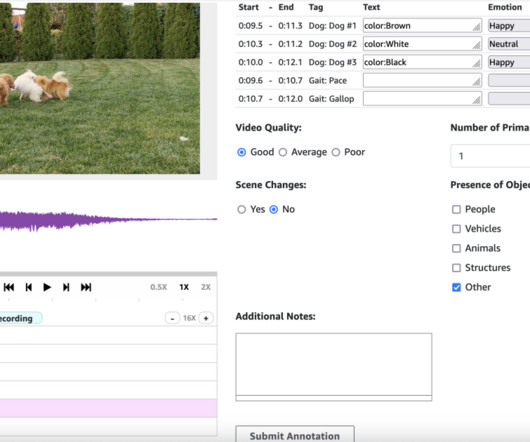
As large language models (LLMs) increasingly integrate more multimedia capabilities, human feedback becomes even more critical in training them to generate rich, multi-modal content that aligns with human quality standards. Programmatic setup Alternatively, you can create your labeling job programmatically using the CreateLabelingJob API.
It provides a collection of pre-trained models that you can deploy quickly, accelerating the development and deployment of ML applications. One of the key components of SageMaker JumpStart is model hubs, which offer a vast catalog of pre-trained models, such as Mistral, for a variety of tasks.
For instance, Pixtral Large is highly effective at spotting irregularities or insightful trends within training loss curves or performance metrics, enhancing the accuracy of data-driven decision-making. By choosing View API , you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDKs.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
The vision encoder was specifically trained to natively handle variable image sizes, enabling Pixtral to accurately interpret high-resolution diagrams, charts, and documents while maintaining fast inference speeds for smaller images such as icons, clipart, and equations. To begin using Pixtral 12B, choose Deploy.
Language Support : Chat GPT can be trained in multiple languages, enabling contact centers to provide support to customers globally without the need for multilingual agents. Training is key and a very important first step as Fred shares. This helps businesses expand their customer base and cater to a diverse range of customers.
Fine-tuning pre-trained language models allows organizations to customize and optimize the models for their specific use cases, providing better performance and more accurate outputs tailored to their unique data and requirements. Model customization in Amazon Bedrock involves the following actions: Create training and validation datasets.
This allowed Intact to transcribe customer calls accurately, train custom language models, simplify the call auditing process, and extract valuable customer insights more efficiently. This efficiency has allowed for more effective use of auditors’ time in devising coaching strategies, improving scripts, and agent training.
Training an LLM to Know and Write Standing up an LLM-powered chatbot requires training, tuning, testing, and validating the LLM’s knowledge and guidance. Like agents, the LLM must have visibility into system outage statuses and training on the latest agent guidance or best practices.
There are several ways to work with Gen AI and LLMs, from SaaS applications with embedded Gen AI to custom-built LLMs to applications that bring in Gen AI and LLM capabilities via API. Few companies have the time or resources to train their own models, and most will instead rely on vendors for Gen AI capabilities like those outlined above.
We provide guidance on building, training, and deploying deep learning networks on Amazon SageMaker. With training and practice, ELA can also learn to identify image scaling, quality, cropping, and resave transformations. We selected a larger instance type to reduce the training time of the model. Set up Amazon SageMaker Studio.
Additionally, the integration of SageMaker features in iFoods infrastructure automates critical processes, such as generating training datasets, training models, deploying models to production, and continuously monitoring their performance. In this post, we show how iFood uses SageMaker to revolutionize its ML operations.
invoke(inputs["query"])) ) return retrieval_chain Option 2: Access the underlying Boto3 API The Boto3 API is able to directly retrieve with a dynamic retrieval_config. For Amazon Bedrock: Use IAM roles and policies to control access to Bedrock resources and APIs.
Increasingly, FMs are completing tasks that were previously solved by supervised learning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset. Although we used a pre-trained FM, the problem was formulated as a text classification task.
Amazon Bedrock is a fully managed service that offers a choice of high-performing Foundation Models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content