This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we share comprehensive bestpractices and scientific insights for fine-tuning Meta Llama 3.2 Our recommendations are based on extensive experiments using public benchmark datasets across various vision-language tasks, including visual question answering, image captioning, and chart interpretation and understanding.
Curated judge models : Amazon Bedrock provides pre-selected, high-quality evaluation models with optimized prompt engineering for accurate assessments. Expert analysis : Data scientists or machine learning engineers analyze the generated reports to derive actionable insights and make informed decisions. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
The challenge: Resolving application problems before they impact customers New Relic’s 2024 Observability Forecast highlights three key operational challenges: Tool and context switching – Engineers use multiple monitoring tools, support desks, and documentation systems. The following diagram illustrates the workflow.
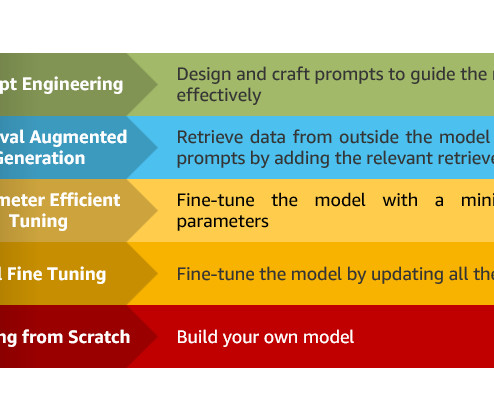
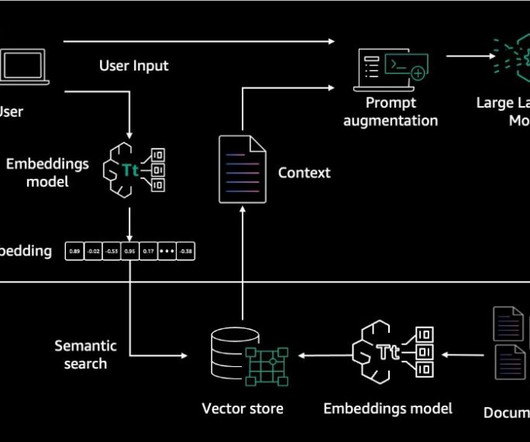
We provide an overview of key generative AI approaches, including prompt engineering, Retrieval Augmented Generation (RAG), and model customization. Building large language models (LLMs) from scratch or customizing pre-trained models requires substantial compute resources, expert data scientists, and months of engineering work.
All text-to-image benchmarks are evaluated using Recall@5 ; text-to-text benchmarks are evaluated using NDCG@10. Text-to-text benchmark accuracy is based on BEIR, a dataset focused on out-of-domain retrievals (14 datasets). Generic text-to-image benchmark accuracy is based on Flickr and CoCo. This example uses ml.g5.xlarge,
In this post, we outline the key benefits and pain points addressed by SageMaker Training Managed Warm Pools, as well as benchmarks and bestpractices. Benchmarks. We performed benchmarking tests to measure job startup latency using a 1.34 Bestpractices for using warm pools. Data Input Mode.
This article outlines 10 CPQ bestpractices to help optimize your performance, eliminate inefficiencies, and maximize ROI. Automate Price Calculations and Adjustments Utilize real-time pricing engines within CPQ to dynamically calculate prices based on market trends, cost fluctuations, and competitor benchmarks.
However, when transitioning between different foundation models, the prompts created for your original model might not be as performant for Amazon Nova models without prompt engineering and optimization. We also discuss the lessons learned and bestpractices for you to implement the solution for your real-world use cases.
In this post, we explore the bestpractices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock. Fine-tuning Anthropic’s Claude 3 Haiku has demonstrated superior performance compared to few-shot prompt engineering on base Anthropic’s Claude 3 Haiku, Anthropic’s Claude 3 Sonnet, and Anthropic’s Claude 3.5
We used the same KPIs as in the previous setup to measure efficiency and performance under these optimized conditions, making sure that cost reduction aligned with our service quality benchmarks. Oleg Yurchenko is the DevOps Director at Automat-it, where he spearheads the companys expertise in DevOps bestpractices and solutions.
Based on our experiments using best-in-class supervised learning algorithms available in AutoGluon , we arrived at a 3,000 sample size for the training dataset for each category to attain an accuracy of 90%. Sonnet prediction accuracy through prompt engineering. The agent mentions Engineering confirmed memory leak in version 5.1.2
In this post, we discuss bestpractices for working with FMEval in ground truth curation and metric interpretation for evaluating question answering applications for factual knowledge and quality. When using LLMs as a judge, make sure to apply prompt safety bestpractices. Question Answer Fact Who is Andrew R.
Leave the session inspired to bring Amazon Q Apps to supercharge your teams’ productivity engines. In this session, learn bestpractices for effectively adopting generative AI in your organization. This session covers bestpractices for a responsible evaluation.
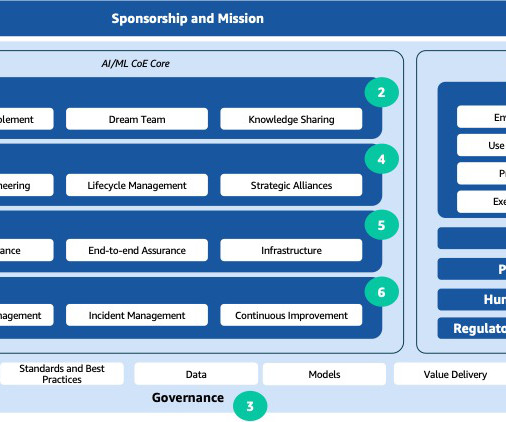
They establish and enforce bestpractices encompassing design, development, processes, and governance operations, thereby mitigating risks and making sure robust business, technical, and governance frameworks are consistently upheld. Platform – A central platform such as Amazon SageMaker for creation, training, and deployment.
The diverse and rich database of models brings unique challenges for choosing the most efficient deployment infrastructure that gives the best latency and performance. For example, for mixed AI workloads, the AI inference is part of the search engine service with real-time latency requirements.
Now, the question is—what are the metrics and figures to benchmark for every industry? The higher its quality, the lower its CPC, and the better its position on search engines. As with previous benchmark reports, the numbers have been consistently high for these industries. Average Cost per Click (CPC). Photo by LOCALiQ.
Customer benchmarking — the practice of identifying where a customer can improve or is already doing well by comparing to other customers – helps Customer Success Managers to deliver unique value to their customers. I’ve found that SaaS vendors use seven distinct strategies to empower CSMs with customer benchmarking.
In particular, we provide practicalbestpractices for different customization scenarios, including training models from scratch, fine-tuning with additional data using full or parameter-efficient techniques, Retrieval Augmented Generation (RAG), and prompt engineering.
Plus, our dedicated AI engineering team has crafted a pre-built, certified question libraryso that you can unlock the immense value of Auto QM starting on day one. 61% of contact center leaders saw an increase in difficult conversations over the past year. Set measurable targets aligned to performance standards and internal benchmarks.
It provides examples of use cases and bestpractices for using generative AI’s potential to accelerate sustainability and ESG initiatives, as well as insights into the main operational challenges of generative AI for sustainability. Throughout this lifecycle, implementing AWS Well-Architected Framework bestpractices is recommended.
Use cases we have worked on include: Technical assistance for field engineers – We built a system that aggregates information about a company’s specific products and field expertise. A chatbot enables field engineers to quickly access relevant information, troubleshoot issues more effectively, and share knowledge across the organization.
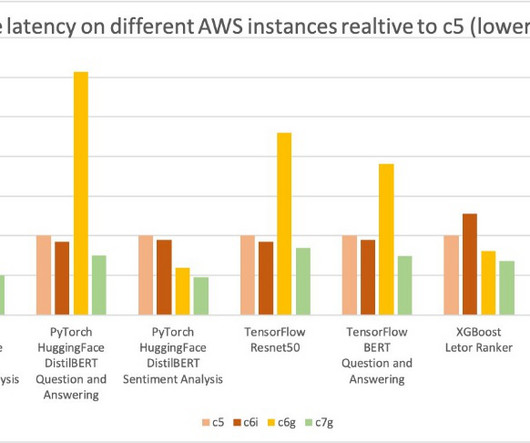
We cover computer vision (CV), natural language processing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking. You can use the sample notebook to run the benchmarks and reproduce the results. Mohan Gandhi is a Senior Software Engineer at AWS.
However, even though the pace of innovation is high, the different teams had developed their own ways of working and were in search of a new MLOps bestpractice. We decided to put in a joint effort to build a prototype on a bestpractice for MLOps.
FCR on social/text needs to be amended to first conversation resolution as customers rarely provide all info needed to resolve a query upfront, but measuring this provides a benchmark you can use against other channels. Reuben Kats is the COO, Web Design Sales Engineer, and Customer Service/ Account Manager at GrabResults,LLC.
Going from 50% first time resolution to 100% first time resolution might sound like a great target, but getting to 60% is already a 20% improvement over the benchmark. The routing engine delivering the contacts must be optimized in such a way that your customer’s experience is both brief and successful. Scott Nazareth. ShoreGroupInc.
Rather than requiring extensive feature engineering and dataset labeling, LLMs can be fine-tuned on small amounts of domain-specific data to quickly adapt to new use cases. This post walks through examples of building information extraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain.
Industry Examples of AI-Enhanced Customer Relations E-commerce Personalization In e-commerce, AI facilitates highly personalized experiences by using recommendation engines to suggest products based on individual preferences. By driving advancements in AI, these leaders establish bestpractices in customer engagement technology.
The backbone of these advancements is ZOE, Zeta’s Optimization Engine. Together, these AI-driven tools and technologies aren’t just reshaping how brands perform marketing tasks; they’re setting new benchmarks for what’s possible in customer engagement. Saurabh Gupta is a Principal Engineer at Zeta Global.
Thats a loyalty engine driven by effective call center management practices and a well-executed call center strategy. As the call center manager, your job isnt just to hit numbers but to inspire your team, optimize processes, and create a workplace culture where agents can perform at their best. But flip that scenario.
Thats a loyalty engine driven by effective call center management practices and a well-executed call center strategy. As the call center manager, your job isnt just to hit numbers but to inspire your team, optimize processes, and create a workplace culture where agents can perform at their best. But flip that scenario.
Additionally, evaluation can identify potential biases, hallucinations, inconsistencies, or factual errors that may arise from the integration of external sources or from sub-optimal prompt engineering. In this case, the model choice needs to be revisited or further prompt engineering needs to be done.
Call Center Management: Challenges, Strategies, Tips, and BestPractices In today’s time, setting up a call or contact center is extremely easy. In such time, the words of noted American business executive, chemical engineer, and writer Jack Welch ring true even after so many years. Why do businesses need call center management?
As an added bonus, we’ll walk you through a Stable Diffusion deep dive, prompt engineeringbestpractices, standing up LangChain, and more. More of a reader than a video consumer? Pretraining a new foundation model Why would you want or need to create a new foundation model?
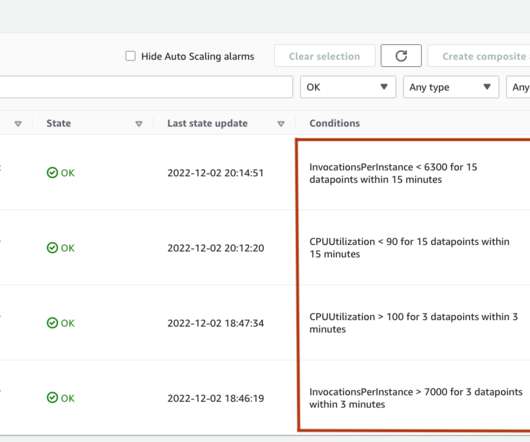
The procedure is further simplified with the use of Inference Recommender , a right-sizing and benchmarking tool built inside SageMaker. However, you can use any other benchmarking tool. Benchmarking To derive the right scaling policy, the first step in the plan is to determine application behavior on the chosen hardware.
To activate continuous batching, DJServing provides the following additional configurations as per serving.properties: engine =MPI – We encourage you to use the MPI engine for continuous batching. In our analysis, we benchmarked the performance to illustrate the benefits of continuous batching over traditional dynamic batching.
With its intuitive interface and buil-in analytics and reporting engine, it is the go-to solution for contact centers to improve their efficiency, and ensure the accuracy and exactitude f collected data. The following are 10 of the bestpractices to ensure the accuracy and the proper handling of reporting and analytics: 1.
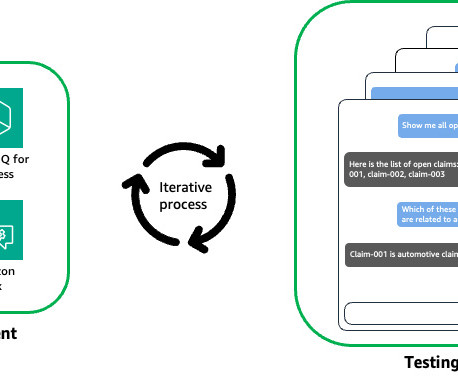
Although existing large language model (LLM) benchmarks like MT-bench evaluate model capabilities, they lack the ability to validate the application layers. To further explore the bestpractices of building and testing conversational AI agent evaluation at scale, get started by trying Agent Evaluation and provide your feedback.
Amazon SageMaker Data Wrangler is a capability of Amazon SageMaker that makes it faster for data scientists and engineers to prepare high-quality features for machine learning (ML) applications via a visual interface. We also cover cost optimization bestpractices to further reduce data preparation costs in Data Wrangler.
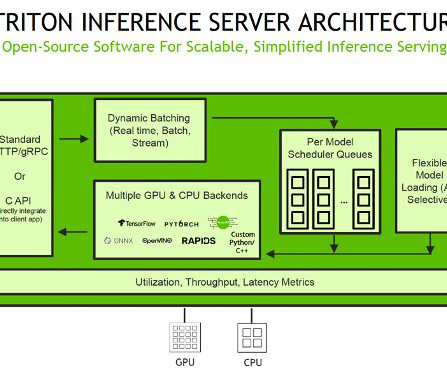
To serve models, Triton supports various backends as engines to support the running and serving of various ML models for inference. With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization. Import the ONNX model into TensorRT and generate the TensorRT engine.
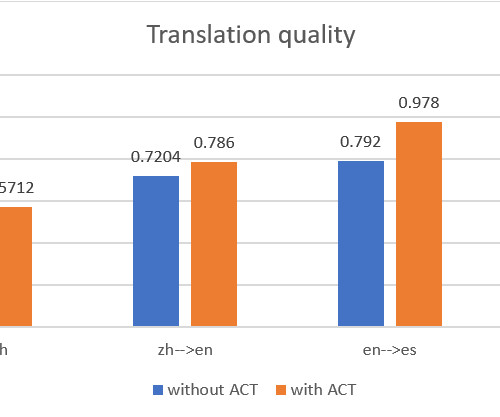
We also recommend bestpractices when using Amazon Translate in this automatic translation pipeline to ensure translation quality and efficiency. We used the BLEU (BiLingual Evaluation Understudy) score to benchmark the translation quality between the two methods. Yunfei has a PhD in Electronic and Electrical Engineering.
For the context of load testing in this post, you can download our sample code from the GitHub repo to reproduce the results or use it as a template to benchmark your own models. Several models of varying sizes and architectures were benchmarked on different type of GPU instances: ml.g4dn.2xlarge,
3 rd tier personnel (often engineers) evaluate the failure, assign priority & remediate as the priority dictates. Here are three examples from the industry; 1) The smartphone applet community is a great example of best-practice; low CES with transparent delivery. Recall all units in the field and remediate immediately!’. .
The AWS Well-Architected Framework provides a systematic way for organizations to learn operational and architectural bestpractices for designing and operating reliable, secure, efficient, cost-effective, and sustainable workloads in the cloud.
Touchpoints may involve any medium you use to interact with customers, including: Search engine marketing. This may occur through encountering your brand or product through a search engine result, a search engine ad, a social media post, a video, a review on a technology website, word-of-mouth or other means. Blog content.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content