This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
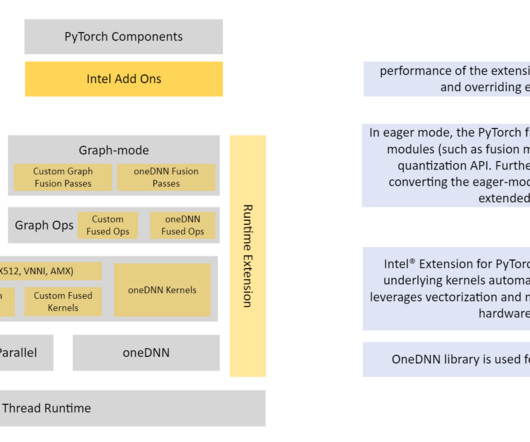
Refer to the appendix for instance details and benchmark data. Import intel extensions for PyTorch to help with quantization and optimization and import torch for array manipulations: import intel_extension_for_pytorch as ipex import torch Apply model calibration for 100 iterations. About the Authors Rohit Chowdhary is a Sr.
In this post, we explore the latest features introduced in this release, examine performance benchmarks, and provide a detailed guide on deploying new LLMs with LMI DLCs at high performance. Be mindful that LLM token probabilities are generally overconfident without calibration. For more details, refer to the GitHub repo.
Based on 10 years of historical data, hundreds of thousands of face-offs were used to engineer over 70 features fed into the model to provide real-time probabilities. By continuously listening to NHL’s expertise and testing hypotheses, AWS’s scientists engineered over 100 features that correlate to the face-off event.
Going from 50% first time resolution to 100% first time resolution might sound like a great target, but getting to 60% is already a 20% improvement over the benchmark. The routing engine delivering the contacts must be optimized in such a way that your customer’s experience is both brief and successful. Scott Nazareth.
Solution overview With the onset of large language models, the field has seen tremendous progress on various natural language processing (NLP) benchmarks. Experimental results corroborate that human feedback on reasoning errors can improve performance and calibration on challenging multi-hop questions.
This is especially significant when utilising third-party engineers, for example, as we can see the real feedback from these interactions and be confident in the people we work with. It’s a cycle of continuous improvement, but it’s one we’re seeing real value in. We’re confident that we can keep building on the success we’ve seen so far.”
Response times across digital channels require different benchmarks: Live chat : 30 seconds or less Email : Under 4 hours Social media : Within 60 minutes Agent performance metrics should balance efficiency with quality. Scorecards combining AHT, FCR, and customer satisfaction create well-rounded performance measurement.
This is especially significant when utilising third-party engineers, for example, as we can see the real feedback from these interactions and be confident in the people we work with. It’s a cycle of continuous improvement, but it’s one we’re seeing real value in. We’re confident that we can keep building on the success we’ve seen so far.”
The NLP engine processes the resulting structured, unstructured, or semi-structured data to derive meaning from it. So, start by setting the benchmarks so that you can monitor any variations. Fortunately, regulatory intelligence software solutions are well-calibrated to do this task without breaking out in a sweat!
Each trained model needs to be benchmarked against many tasks not only to assess its performances but also to compare it with other existing models, to identify areas that needs improvements and finally, to keep track of advancements in the field. Evaluating these models allows continuous model improvement, calibration and debugging.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content