This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Call auditing helps ensure that customer interactions meet established quality benchmarks while identifying areas for improvement. Conduct Calibration Sessions for Accuracy Calibration sessions ensure consistency across QA teams. For example: Improve first-call resolution (FCR) by 10% in three months.
Fortuna provides calibration methods, such as conformal prediction, that can be applied to any trained neural network to obtain calibrated uncertainty estimates. Something like this, for example: p = [0.0001, 0.0002, …, 0.9991, 0.0003, …, 0.0001]. This concept is known as calibration [Guo C. 2022] methods.
A common grade of service is 70% in 20 seconds however service level goals should take into account corporate objectives, market position, caller captivity, customer perceptions of the company, benchmarking surveys and what your competitors are doing. The industry benchmark for the first call resolution measurement is between 70% to 75%.
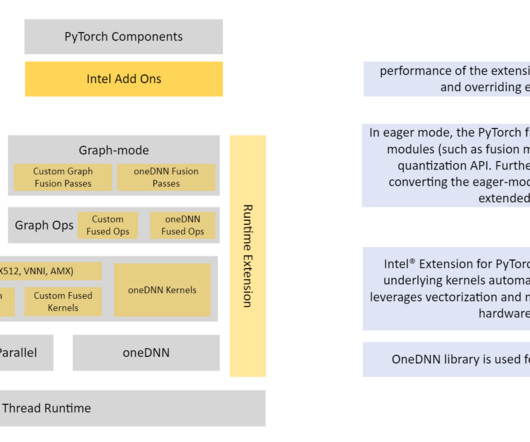
In the following example figure, we show INT8 inference performance in C6i for a BERT-base model. Refer to the appendix for instance details and benchmark data. The following example is a question answering algorithm using a BERT-base model. The code snippets are derived from a SageMaker example.
In our example, the organization is willing to approve a model for deployment if it passes their checks for model quality, bias, and feature importance prior to deployment. For this example, we provide a centralized model. You can create and run the pipeline by following the example provided in the following GitHub repository.
Solution overview With the onset of large language models, the field has seen tremendous progress on various natural language processing (NLP) benchmarks. The final dataset contains feedback for 1,565 samples from StrategyQA and 796 examples for Sports Understanding. The following figure shows the interface we used. Missing Facts 50.4%
Before using Klaus: CSAT was 95% – above 2022’s benchmark of 89%. IQS measured 86% – slightly below 2022’s benchmark of 89%. Overall, they managed to push both their IQS and CSAT into higher realms of excellence – their IQS now beating the benchmark. With Klaus, they: 1. Identify areas of high learning potential .
Example: Campaign A has a high call volume but campaign B has less calls and the agents that are assigned campaign B are not busy. Going from 50% first time resolution to 100% first time resolution might sound like a great target, but getting to 60% is already a 20% improvement over the benchmark. Scott Nazareth.
The overall goal of this post is to demystify summarization evaluation to help teams better benchmark performance on this critical capability as they seek to maximize value. Use it as a baseline or benchmark for summary quality related to content selection. ROUGE would not identify these issues.
Issue resolution and clear communication are two examples of customer critical attributes that significantly impact customer experience. Disclosing sensitive information without the proper identification is an example of a compliance error. Accurately logging calls or attempting to close a sale are two examples. Stay tuned!
We explored nearest neighbors, decision trees, neural networks, and also collaborative filtering in terms of algorithms, while trying different sampling strategies (filtering, random, stratified, and time-based sampling) and evaluated performance on Area Under the Curve (AUC) and calibration distribution along with Brier score loss.
In this post, we explore the latest features introduced in this release, examine performance benchmarks, and provide a detailed guide on deploying new LLMs with LMI DLCs at high performance. Be mindful that LLM token probabilities are generally overconfident without calibration. This is returned with the last streamed sequence chunk.
This is especially significant when utilising third-party engineers, for example, as we can see the real feedback from these interactions and be confident in the people we work with. It’s a cycle of continuous improvement, but it’s one we’re seeing real value in.
This is especially significant when utilising third-party engineers, for example, as we can see the real feedback from these interactions and be confident in the people we work with. It’s a cycle of continuous improvement, but it’s one we’re seeing real value in.
However, the scope of regulatory intelligence software or services is not just limited to the examples above. So, start by setting the benchmarks so that you can monitor any variations. Fortunately, regulatory intelligence software solutions are well-calibrated to do this task without breaking out in a sweat!
Regular reviews ensure that quality benchmarks are being met and provide valuable feedback for continuous improvement in customer interactions. Regular calibration sessions with QA evaluators help ensure consistency and alignment across the team. Solution: Provide specific, actionable feedback tied to concrete examples.
Benchmarking Against Industry Standards Benchmarking against industry standards helps operations managers gauge their team’s performance relative to competitors. Why is benchmarking important? A well-calibrated IVR system is the cornerstone for intelligent contact center automation. Everything you need to know.
Performance Management for setting personal targets, benchmarks and achievements for each agent to deliver positive customer interactions. Calibrate regularly. In fact, simply embracing self-service for the contact center’s financial benefit—to deflect phone calls, for example—can backfire. Gauge your QM process for consistency.
Performance Management for setting personal targets, benchmarks and achievements for each agent to deliver positive customer interactions. Calibrate regularly. In fact, simply embracing self-service for the contact center’s financial benefit—to deflect phone calls, for example—can backfire. Gauge your QM process for consistency.
Additionally, we provide code example in this GitHub repository to enable the users to conduct parallel multi-model evaluation at scale, using examples such as Llama2-7b-f, Falcon-7b, and fine-tuned Llama2-7b models. Evaluating these models allows continuous model improvement, calibration and debugging.
It is possible to choose smaller LLMs depending on the task complexity; For example, if complex common-sense reasoning is not involved, we can choose Claude Haiku over Sonnet. Dataset The dataset for this post is manually distilled from the Amazon Science evaluation benchmark dataset called TofuEval.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content