This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Understanding how to make a profit on the double bottom line (DBL) involves employing a broad range of KPIs and key metrics to ensure a contact centre meets every need that a business may have in supporting their customers. of the 380 contact centre professionals they asked thought customer satisfaction was one of the most important metrics.
Call auditing helps ensure that customer interactions meet established quality benchmarks while identifying areas for improvement. Conduct Calibration Sessions for Accuracy Calibration sessions ensure consistency across QA teams. Q5: What metrics are essential for call auditing?
Metrics, Measure, and Monitor – Make sure your metrics and associated goals are clear and concise while aligning with efficiency and effectiveness. Make each metric public and ensure everyone knows why that metric is measured. Jeff Greenfield is the co-founder and chief operating officer of C3 Metrics.
Fortuna provides calibration methods, such as conformal prediction, that can be applied to any trained neural network to obtain calibrated uncertainty estimates. This concept is known as calibration [Guo C. Fortuna: A library for uncertainty quantification. 2020] , temperature scaling [Guo C. 2022] methods.
The SageMaker approval pipeline evaluates the artifacts against predefined benchmarks to determine if they meet the approval criteria. You can either have a manual approver or set up an automated approval workflow based on metrics checks in the aforementioned reports. Bias with Bias Benchmark for Question Answering (BBQ).
In this post, we explore leading approaches for evaluating summarization accuracy objectively, including ROUGE metrics, METEOR, and BERTScore. The overall goal of this post is to demystify summarization evaluation to help teams better benchmark performance on this critical capability as they seek to maximize value.
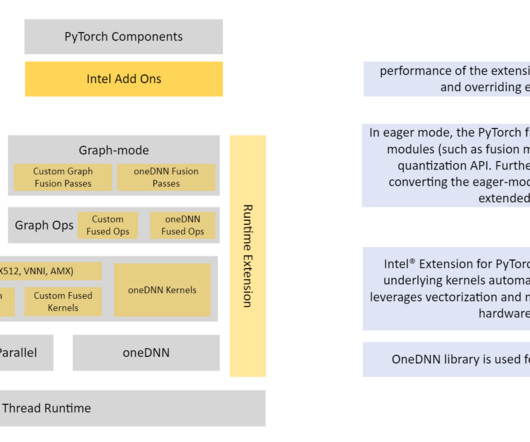
Refer to the appendix for instance details and benchmark data. Import intel extensions for PyTorch to help with quantization and optimization and import torch for array manipulations: import intel_extension_for_pytorch as ipex import torch Apply model calibration for 100 iterations. Refer to invoke-INT8.py py and invoke-FP32.py
Before using Klaus: CSAT was 95% – above 2022’s benchmark of 89%. IQS measured 86% – slightly below 2022’s benchmark of 89%. These metrics are very commendable, but Pipedrive wanted to raise the bar even higher. Maintaining fair and consistent grading with regular calibration sessions. With Klaus, they: 1.
Measure three quality metrics vs. one overall quality score. Measure Three Quality Metrics vs. One Overall Score. But when we segmented the overall score into the three metrics mentioned above, the results told a different story. Sampling approaches, calibration, and overall program design also play critical roles.
Its not just about tracking basic metrics anymoreits about gaining comprehensive insights that drive strategic decisions. Key Metrics for Measuring Success Tracking the right performance indicators separates thriving call centers from struggling operations. This metric transforms support from cost center to growth driver.
The decision tree provided the cut-offs for each metric, which we included as rules-based logic in the streaming application. At the end, we found that the LightGBM model worked best with well-calibrated accuracy metrics. To evaluate the performance of the models, we used multiple techniques.
The innovative technology aligns quality results with the customer experience and key business metrics. RevealCX enables quality management best practices in all areas such as calibration, closed-loop feedback, action planning and robust analytics to drive performance improvement efforts. About COPC Inc.
In this post, we explore the latest features introduced in this release, examine performance benchmarks, and provide a detailed guide on deploying new LLMs with LMI DLCs at high performance. Be mindful that LLM token probabilities are generally overconfident without calibration.
Managers can also participate in gaming the scores by selecting incorrect metrics to be evaluated on, by opening the range of “satisfied” scores, and even by creating corrections to the summaries for events like outages, recalls, sample size, or any other excuse that should generate a footnote but generally does not.
As we will see, this can include strategies like automation, data analytics, digital transformation initiatives, and continuous improvement programs aimed at achieving measurable performance improvements beyond traditional metrics. These metrics should be data-driven, allowing you to identify areas of improvement and track progress over time.
Gunjan : The ultimate metric of success for any SaaS organization is net retention. This is a prerequisite to be able to calibrate strategy and iterate appropriately. Measuring success involves a benchmark, and it is often difficult to even gather that benchmark.
You’ll improve customer experience metrics like average handle time and first call resolution. Performance Management for setting personal targets, benchmarks and achievements for each agent to deliver positive customer interactions. Calibrate regularly. Metrics Focused on Customer Experience. Support and Motivate Agents.
You’ll improve customer experience metrics like average handle time and first call resolution. Performance Management for setting personal targets, benchmarks and achievements for each agent to deliver positive customer interactions. Calibrate regularly. Metrics Focused on Customer Experience. The Cloud.
Each trained model needs to be benchmarked against many tasks not only to assess its performances but also to compare it with other existing models, to identify areas that needs improvements and finally, to keep track of advancements in the field. Furthermore, these data and metrics must be collected to comply with upcoming regulations.
Dataset The dataset for this post is manually distilled from the Amazon Science evaluation benchmark dataset called TofuEval. Refer to the evaluation metrics section for accuracy definition) This continues for N(=3 in this notebook) rounds. LLM debates need to be calibrated and aligned with human preference for the task and dataset.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content