This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Marcia Jenkins, Senior Operations Manager According to the 2021 Membership Marketing Benchmark report, it has been a challenging year for association membership. Scripting: The key to ensuring the long-term effectiveness of your outbound telemarketing script may be to eliminate the “script.” Is it failing?
. * The `if __name__ == "__main__"` block checks if the script is being run directly or imported. To run the script, you can use the following command: ``` python hello.py ``` * The output will be printed in the console: ``` Hello, world! Evaluate model on test set, compare to benchmarks, analyze errors and biases.
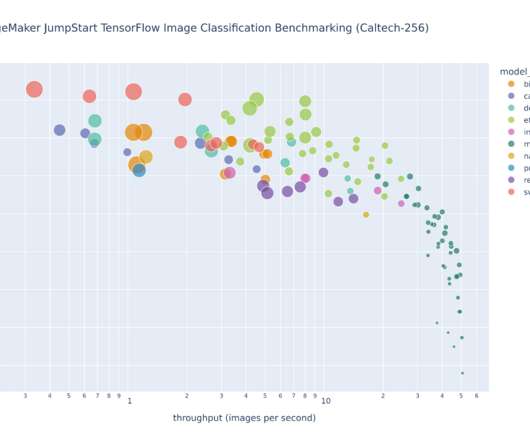
The former question addresses model selection across model architectures, while the latter question concerns benchmarking trained models against a test dataset. This post provides details on how to implement large-scale Amazon SageMaker benchmarking and model selection tasks. swin-large-patch4-window7-224 195.4M efficientnet-b5 29.0M
For almost 40 years, we have worked tirelessly at aiding businesses with actionable reporting, simplified scripting, and customized solutions. Summer Conferences for Medical Professionals and Equipment Providers. Summer HR Conferences. Customer Support and Call Center Conferences 2018. Technique Key to Success.
AlexaTM 20B has shown competitive performance on common natural language processing (NLP) benchmarks and tasks, such as machine translation, data generation and summarization. To use a large language model in SageMaker, you need an inferencing script specific for the model, which includes steps like model loading, parallelization and more.
Starting with our tried and true templates, your account manager will suggest scripts and then cater them to your exact needs. . Summer Conferences for Medical Professionals and Equipment Providers. Summer HR Conferences. Customer Support and Call Center Conferences 2018. Technique Key to Success. Telephone Etiquette.
Welocalize benchmarks the performance of using LLMs and machine translations and recommends using LLMs as a post-editing tool. We use the custom terminology dictionary to compile frequently used terms within video transcription scripts. She holds 30+ patents and has co-authored 100+ journal/conference papers. Here’s an example.
Your team can use Zoom or another video conferencing platform to attend training sessions and conferences online. To demonstrate the practical aspect of your customer profiles, write up role-play scripts for each profile and have staff act them out. But working remotely doesn’t mean you have to stop training. Act it out.
Design surveys, contact center scripts, and the customer experience to encourage feedback and acknowledge client needs. Summer Conferences for Medical Professionals and Equipment Providers. Summer HR Conferences. Customer Support and Call Center Conferences 2018. Technique Key to Success. Telephone Etiquette.
Over the four years the program has been in place, all key program metrics have shown progressive, benchmark-exceeding improvement. Check out some data from our recent research: In our Q3 2018 Consumer Benchmark Study, we found that 40% of full time U.S. Employee and agent feedback should be a two-way street.
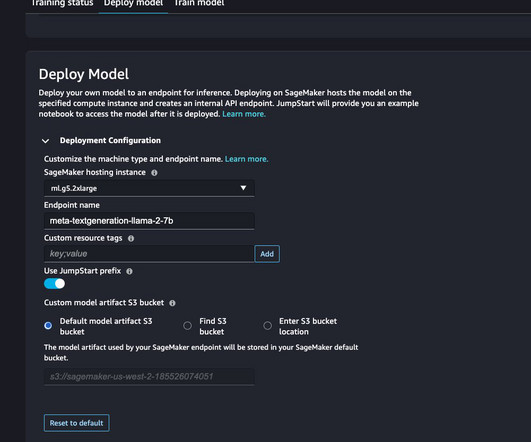
Even if you already have a pre-trained model, it may still be easier to use its corollary in SageMaker and input the hyperparameters you already know rather than port it over and write a training script yourself. The training and inference scripts for the selected model or algorithm. Benchmarking the trained models.
As a director in your government agency, what are the most important KPIs you use to measure customer experience benchmarks? A small, intimate conference focusing on productivity and mindset. Another conference I always enjoy, whether it’s in person or online, is Podcast Movement. We have a few. For example?—?be
Computer telephony integration enables video and conference calling, whisper coaching, and file transfers. Take advantage of free trials and benchmark different providers to stay informed. Ask about integrations with helpdesks, CRMs, script builders, survey templates, etc. Focus on success. Ask for training.
On top of that, each new employee should have a benchmark assessment during a one-on-one session (we’d suggest on live calls) to highlight areas where they need to improve from the start. Your team can use Zoom or BlueJeans to attend training sessions and conferences while working remotely. Who doesn’t like a good story?
Mark Zuckerberg opened his keynote address at Facebook’s F8 Developers Conference in 2019 said, “Let’s talk about building a privacy-focused social platform” which made it obvious that he is making an effort to change the negative brand opinion of his brand to a positive tone. Always Empower and Reward Your Employees.
nn For performance benchmarking of different models on the Dolly and Dialogsum dataset, refer to the Performance benchmarking section in the appendix at the end of this post. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Their research indicates that zero-shot CoT, using the same single-prompt template, significantly outperforms zero-shot FM performances on diverse benchmark reasoning tasks. He is a book author (Computer Vision on AWS), regularly publishes blogs and code samples, and has delivered talks at tech conferences such as AWS re:Invent.
Call Recording and Analytics Software Call recordings are analyzed for important moments that indicate whether reps are following or deviating from their call plan/script. Dialogue Scripting for a Seamless User Experience and Empathy Good conversations require so much more than just a simple response.
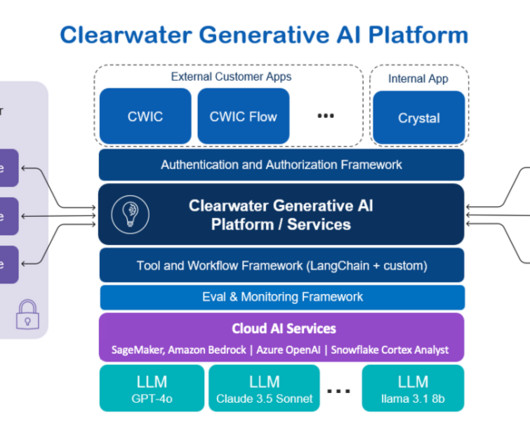
By September of the same year, Clearwater unveiled its generative AI customer offerings at the Clearwater Connect User Conference, marking a significant milestone in their AI-driven transformation. RAG benchmark Compare the fine-tuned models performance against a RAG system using a pre-trained model.
Computer telephony integration enables video and conference calling, whisper coaching, and file transfers. Take advantage of free trials and benchmark different providers to stay informed. Ask about integrations with helpdesks, CRMs, script builders, survey templates, etc. Focus on success. Ask for training.
Using Google Chat, your team can easily collaborate via text, build collaborative chat rooms, conduct web conferences, share documents, and deliver presentations. Web Conferencing: Improve online meetings with high-quality audio and video web conferencing, extensive screen sharing capabilities, and advanced conference call setting.
Provides additional features like calendar management and benchmarking. Global conferencing – Global dial-in so teams from any location can be added to conference calls. Call monitoring and scripting are possible with 8×8. 5 Capterra– 4.1/5 5 TrustRadius– 7.7/10 10 Trustpilot– 3.3/5 Has alerts and ticket escalation.
And we also do a couple benchmarking surveys a year for member companies and also have an online forum, some private meeting groups for members to be able to exchange digitally in that environment. And I do that at my conferences and workshops.
Now, you will need to create a custom script that can be used for testing. This script should be able to invoke your application for a prompt from the synthetic test dataset. We created a Python script, invoke_bedrock_agent.py, with which we invoke the agent for a given prompt. After you create the agent, set up promptfoo.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content