This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We did some work with a construction equipment manufacturer. They were dealing with construction people. If you want to benchmark your organization’s performance in the new world of behavioral economics against other companies, take our short questionnaire. That said, the human emotion of feeling “cared for” is universal.
All text-to-image benchmarks are evaluated using Recall@5 ; text-to-text benchmarks are evaluated using NDCG@10. Text-to-text benchmark accuracy is based on BEIR, a dataset focused on out-of-domain retrievals (14 datasets). Generic text-to-image benchmark accuracy is based on Flickr and CoCo.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
Choice architecture describes how to construct choice sets that still give people the freedom to choose, but points in some direction, or makes it easier for them. If you want to benchmark your organization’s performance in the new world of behavioral economics against other companies, take our short questionnaire.
Performance metrics analysis: This involves tracking and benchmarking key performance indicators (KPIs) such as customer satisfaction, average handle time, first-call resolution, and call compliance adherence as indicated on QA scorecards and dashboards. This is coupled with ongoing training and coaching sessions for sustainable improvements.
Net Promoter Scores are always an interesting topic of conversation, and industry NPS benchmarks even more so. This blog post will discuss NPS benchmarks and look at why NPS is so essential to overall customer success. This is why benchmarking is so important, which we will discuss later. and IT services is 42.
But how does one begin constructing a business case applying this fact? Improving customer experience increases customer lifetime value. In fact, it dramatically increases it, as research indicates that satisfied customers spend more than twice as much as unsatisfied customers.
Call Center Industry Turnover Rate Benchmarks Call center turnover rates are notoriously high compared to other industries. Depending on the type of work performed, typical benchmarks range from as low as 15% to 45%, or even higher. And employee churn among new hires can be especially high. Contact center industry averages vary.
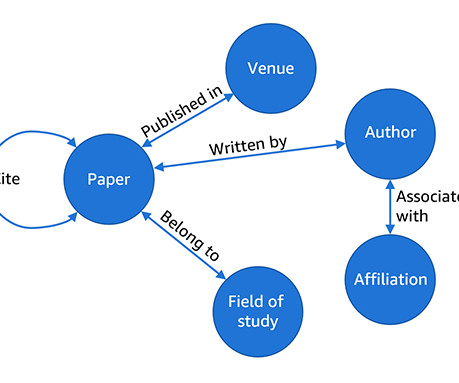
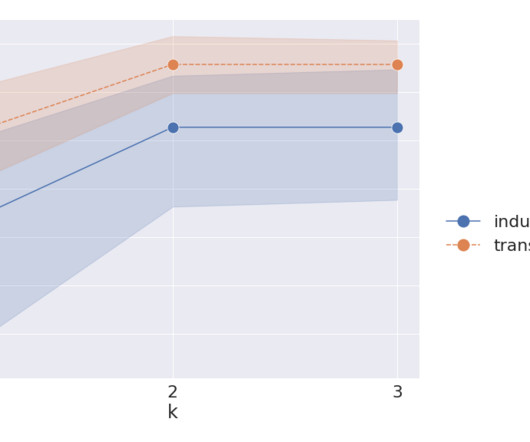
we released a LM+GNN benchmark using the large graph dataset, Microsoft Academic Graph (MAG), on two standard graph ML tasks: node classification and link prediction. The following table shows the model performance of the two methods and the overall computation time of the whole pipeline starting from data processing and graph construction.
Call center QA, or contact center QA, is a strategic, data-driven process that evaluates every facet and channel of customer interactionsfrom voice calls and live chats to emails and social media engagementsagainst established performance benchmarks. A recent Calabrio study found just 22% of agents get one-on-one feedback on a weekly basis.
Over the four years the program has been in place, all key program metrics have shown progressive, benchmark-exceeding improvement. Check out some data from our recent research: In our Q3 2018 Consumer Benchmark Study, we found that 40% of full time U.S. I mean, really listen and act on what they say. Don’t forget the basics.
Extensive benchmarking experiments on three publicly available datasets with various settings are conducted to validate its performance. Each instance constructs its local histogram, and all histograms are merged, then a split is performed using a reduce scatter algorithm. They’re available through the SageMaker Python SDK. 0.942 65.5
Jina Embeddings v2 is the preferred choice for experienced ML scientists for the following reasons: State-of-the-art performance – We have shown on various text embedding benchmarks that Jina Embeddings v2 models excel on tasks such as classification, reranking, summarization, and retrieval.
The pre-trained GNN embeddings show a 24% improvement on a shopper activity prediction task over a state-of-the-art BERT- based baseline; it also exceeds benchmark performance in other ads applications.” TB RAM) to construct the OAG graph. on the test set of the constructed graph. 48xlarge instances (192 vCPU and 1.5
has 92% accuracy on the HumanEval code benchmark. Constructing a multimodal retriever requires having an embedding strategy that can handle this multimodality. In other cases, we can’t reliably use an LLM to analyze tabular data, even when provided as structured format in the prompt. or “Show me items with a similar pattern.”
Graph neural networks (GNNs) have shown great promise in tackling fraud detection problems, outperforming popular supervised learning methods like gradient-boosted decision trees or fully connected feed-forward networks on benchmarking datasets. Graph construction We use the TransactionID column to generate target nodes.
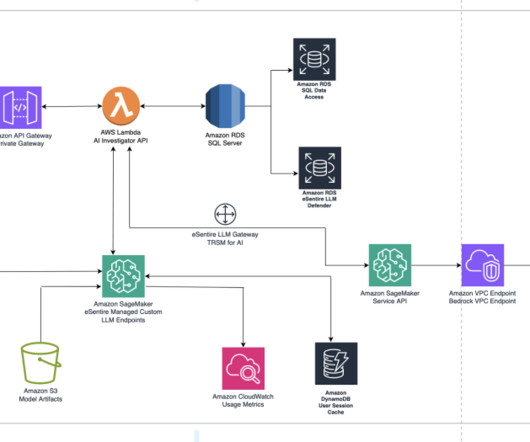
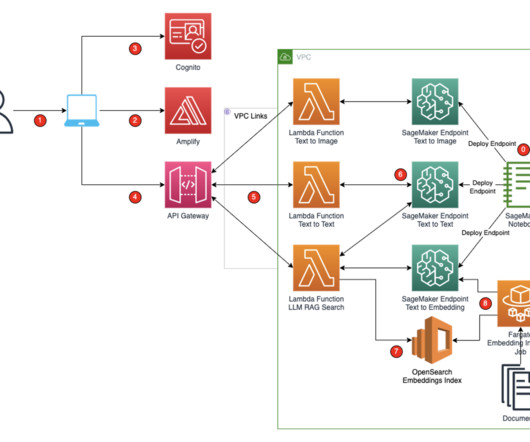
When a SageMaker endpoint is constructed, an S3 URI to the bucket containing the model artifact and Docker image is shared using Amazon ECR. Amazon Bedrock offers a practical environment for benchmarking and a cost-effective solution for managing workloads due to its serverless operation.
Take advantage of this phenomenon by constructing your scripts to promote positive responses.” “The International Contact Center Benchmarking Consortium (ICCBC.org) provides thorough data and trends analysis. ” – Effective Call Center Scripts , Salesforce; Twitter: @SalesforceGov.
They let each customer physically see their burger being constructed at the assembly bar, giving them the opportunity to select each topping right on the spot. Understanding Industry Benchmarks. This is especially true when we think we’re getting personalized service, tailored to our unique needs and wants. Plus So Much More!
Recommended instances and benchmarks The following table lists all the Meta SAM 2.1 This is one of many examples of how the image predictor can act as a bridge between 2D and 3D construction across many different tasks. The following examples for each of the tasks reference these operations without repeating them.
It is essential to keep principles of survey design in mind when constructing questionnaires or polls. This means that before you even begin constructing your survey, you should take some time to think through and clearly define what result you want to achieve with this survey. Start with the end goal in mind.
By reviewing your website’s visit count before hiring, you can begin to construct your estimate of how many live chat agents you will need. The industry benchmark is 2 live chats per agent at a time, but experienced agents can take on up to 3. Live Chat Benchmark Report 2022. How Many Hours is your Live Chat Available per Day?
Alternative LLMs can be deployed based on the use case and model performance benchmarks. Lambda functions also construct the prompts from the sanitized user input in the respective format expected by the LLM. For more information about foundation models, see Getting started with Amazon SageMaker JumpStart.
It’s become a benchmark in the contact center industry, though its origins are not at all scientific nor grounded in research. If you’re keen on ensuring low call abandonment rates, then you should construct your service levels to help attain that as a goal.
For SaaS B2B clients, QBR meetings tend to focus on assessing value as measured by KPI performance benchmarks. Generate a report summarizing KPIs benchmarks from the last QBR and progress toward them. Use Benchmarking Data. It places challenges in a more positive context, promoting a more constructive discussion.
The overall goal of this post is to demystify summarization evaluation to help teams better benchmark performance on this critical capability as they seek to maximize value. Use it as a baseline or benchmark for summary quality related to content selection. ROUGE would not identify these issues. and expects a response from the model.
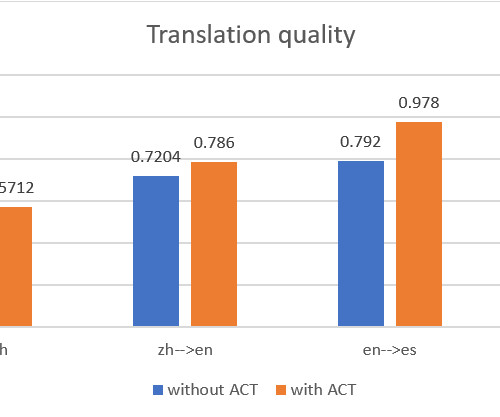
We used the BLEU (BiLingual Evaluation Understudy) score to benchmark the translation quality between the two methods. We used both parallel data input files to construct two parallel data entities in Amazon Translate, then created two batch translation jobs with the same source document.
Strategies to Improve Customer Satisfaction KPIs: Clearly define each metric and establish benchmarks. Benchmark: Many organizations aim for an AHT of 480 seconds (8 minutes), depending on industry standards. Industry Standard: The 80/20 rule (80% of calls answered within 20 seconds) is a common benchmark.
TIP: While call center metrics like AHT and FCR are great benchmarks for performance, they aren’t great motivators. Constructive feedback is also an important part of keeping employees motivated. Agents will be more inclined to act on constructive feedback if they know their efforts are helping them advance their career.
’s global benchmarks. The organization constructed correct governance models, KPI measurement approaches, review methods, improvement actions/methodologies and performance tracking approaches. for expert consulting , training , certification , benchmarking and research solutions. Becoming COPC Inc. Today, COPC Inc.
Assuming the results are positive, the company then proudly presents their board with the survey results compared to industry benchmarks and proceeds with the board meeting. Let’s move on to how many new customers you acquired” is likely the next agenda item. And you can’t stop there. Keep a finger on the pulse of your end-user experience.
With a benchmark on how much your support team usually sees, you can start to identify busy seasons and see the direct impact of pricing changes or implementations with your product. Take the time to get to know your problem and star customers, as well as what kinds of constructive or positive insights they have for your team.
Measuring Employee Net Promoter Score opens the door for honest and constructive dialogue between employees and their managers. Looking for eNPS benchmarking? It’s been said that to win in the marketplace, you must first win in the workplace. Read our post on comparing your score to peers.
On Hugging Face, the Massive Text Embedding Benchmark (MTEB) is provided as a leaderboard for diverse text embedding tasks. It currently provides 129 benchmarking datasets across 8 different tasks on 113 languages. You can use the BGE embedding model to retrieve relevant documents and then use the BGE reranker to obtain final results.
Constructive feedback will also be shared in the game, which is beneficial to all employees. Employees with exceptional knowledge and skills can easily be identified to help benchmark where everyone is at.Utilising Gamification technology provides insights on employees’ motivations and engagement patterns.
Constructive feedback will also be shared in the game, which is beneficial to all employees. Employees with exceptional knowledge and skills can easily be identified to help benchmark where everyone is at.Utilising Gamification technology provides insights on employees’ motivations and engagement patterns.
Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training. Performance benchmark results. You must benchmark with your own model and dataset to produce price performance benefits that match your workload.
We use the Recognizing Textual Entailment dataset from the GLUE benchmarking suite. Phrase 2: A bearded man pulls a rope We load the textual recognizing entailment dataset from the GLUE benchmarking suite via the dataset library from Hugging Face within our training script (./training.py training.py ).
And what’s critical is determining where a brand’ web / mobile sites compare to customer expectations as well as benchmarking against CoIT applications or competitors or even non-competitors who have a great customer experience. In fact, that’s key to where customer expectations come from thus important to capitalize on. In Robert B.
You can read more about the effects of COVID-19 in our Live Chat Benchmark Report 2020: Covid-19 Edition. . Just as negative stories can be amplified by digital channels, positive stories can also be used constructively to shape the narrative around an organization. – Staying Connected .
4) Tell me about a time where you received constructive criticism. It’s always interesting to hear how people handle constructive criticism. Understanding Industry Benchmarks. That they went over and above to make the customer happy, and that their manager was thrilled with the outcome. 5) Where do you see yourself in 5 years?
The directory path for the compiled model is constructed by joining COMPILER_WORKDIR_ROOT with the subdirectory text_encoder : emb = torch.tensor([.]) The emb tensor is used as example input for the torch_neuronx.trace function. This function traces our text encoder and compiles it into a format optimized for Neuron.
Delighted’s benchmark email survey response rate hovers around 15%. . Use urgency in subject lines sparingly and only when it’s constructive: e.g. when a reward for a survey is valuable enough for a recipient to act immediately. Source: SuperOffice. is estimated at 33%.
Then, talk through constructive feedback. But if the goal was 75% (and his peers are meeting it), then set new benchmarks for Mark and talk through actionable ways to improve. “By To foster this kind of recognition-rich culture, kick your performance reviews off with the positives. People retreat when they hear criticism.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content