This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For this post, we use a dataset called sql-create-context , which contains samples of natural language instructions, schema definitions and the corresponding SQL query. We also included a data exploration script to analyze the length of input and output tokens. We encourage you to read this post while running the code in the notebook.
The prospect of fine-tuning open source multimodal models like LLaVA are highly appealing because of their cost effectiveness, scalability, and impressive performance on multimodal benchmarks. It sets up a SageMaker training job to run the custom training script from LLaVA. For full parameter fine-tuning, ml.p4d.24xlarge
In such cases, standards provide a useful benchmark, especially for new employees learning how to do the job. But service standards can also be too rigid, or too scripted, and inadvertently degrade a service experience or cause damage to a service brand. Standards can also support your brand.
This is one situation in which the company should have definitely folded. Read Email Response Times: Benchmarks and Tips for Support for practical advice. This one was a robot, but there are plenty of real humans who aren’t able to break from the script even when the play suddenly has a new act. Allow for human judgement.
The code to invoke the pipeline script is available in the Studio notebooks, and we can change the hyperparameters and input/output when invoking the pipeline. This is quite different from our earlier method where we had all the parameters hard coded within the scripts and all the processes were inextricably linked.
This was the perfect place to start for our prototype—not only would Axfood gain a new AI/ML platform, but we would also get a chance to benchmark our ML capabilities and learn from leading AWS experts. If discrepancies arise, a business logic within the postprocessing script assesses whether retraining the model is necessary.
These include metrics such as ROUGE or cosine similarity for text similarity, and specific benchmarks for assessing toxicity (Detoxify), prompt stereotyping (cross-entropy loss), or factual knowledge (HELM, LAMA). When you evaluate a case, evaluate the definitions in order and label the case with the first definition that fits.
The best data to train your bot comes from the resources you’ve already built, including chat scripts, your knowledge base, and FAQs. A good benchmark is 5-10 examples for each intent to start. You should also think about how you’ll train your chatbot. Building your bot. The first step to building your bot is adding intents.
Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training. Performance benchmark results. You can build logic in your training script to assign the instance groups to certain training and data processing tasks.
The former question addresses model selection across model architectures, while the latter question concerns benchmarking trained models against a test dataset. This post provides details on how to implement large-scale Amazon SageMaker benchmarking and model selection tasks. swin-large-patch4-window7-224 195.4M efficientnet-b5 29.0M
Research from Benchmark Portal found that, on average, 15% of customer inquiries are handled through self-service. The post Self-Service for Contact Center: The Definitive Guide appeared first on NobelBiz. You guessed it; it’s money. Here’s the simple math. Get in touch with one of our experts here !
AWS Batch Job Definitions. The deployments are done using bash scripts, and in this case we use the following command: bash malware_detection_deployment_scripts/deploy.sh -s ' ' -b 'malware- detection- -artifacts' -p -r " " -a. script: bash malware_detection_deployment_scripts/destroy.sh -s -p -r. Public and Private Subnets.
In this post, we outline the key benefits and pain points addressed by SageMaker Training Managed Warm Pools, as well as benchmarks and best practices. Benchmarks. We performed benchmarking tests to measure job startup latency using a 1.34 Overview of SageMaker Training Managed Warm Pools. When should you use warm pools?
Laying the groundwork: Collecting ground truth data The foundation of any successful agent is high-quality ground truth data—the accurate, real-world observations used as reference for benchmarks and evaluating the performance of a model, algorithm, or system. The same advice is valid when defining the functions of your action groups.
The trtexec tool has three main purposes: Benchmarking networks on random or user-provided input data. script from the following cell. While waiting for the command to finish running, you can check the scripts used in this step. While waiting for the command to finish running, you can check the scripts used in this step.
Here are the definitions to the top seven bot-specific terms you need to know: Intents: An intent is the intention of a visitor. Decision Tree: An “If this… then that” framework that guides the customer to choose from a list of pre-defined scripts and options. This framework can be presented either through keywords or buttons.
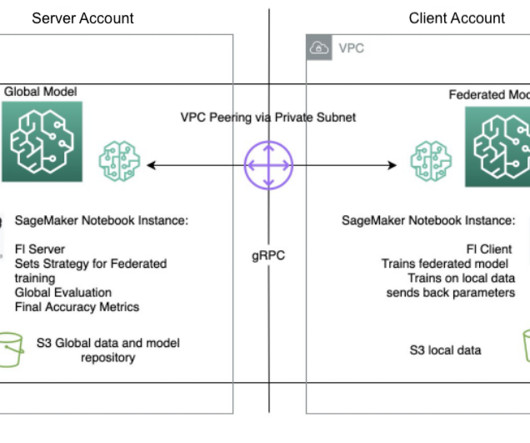
The notebook instance client starts a SageMaker training job that runs a custom script to trigger the instantiation of the Flower client, which deserializes and reads the server configuration, triggers the training job, and sends the parameters response. script and a utils.py The client.py We use utility functions in the utils.py
However, there's an industry benchmark based on which you can assess your performance. According to industry benchmark research, the average sales cycle length for B2B companies is 102 days ( source ). How does your win rate fare against the industry benchmark? A low win rate is definitely not a good sign.
Naturally, this is setting a new benchmark for E-commerce stores, since customers are choosing to shop at only the best websites in the competitive space. This is essentially a software program that uses scripted rules and AI to provide human customers with relevant guidance. Incorporate a digital sales agent.
Call recordings are analyzed for important moments that indicate whether reps are following or deviating from their call plan/script. You can compare your reps’ performance with industry benchmarks across industries and roles. Analytics and Benchmarking. There’s no definite pricing for conversation intelligence software.
Generally, on the 10-point scale, there are three categories of customers: Anyone who answers between a 0 or a 1 (definitely would not recommend) and a 6 (might or might not recommend) is considered a Detractor. After providing a score in each benchmark category based on a defined rubric, the call is then given an overall quality score.
Although we’ll do the majority of training outside of the classroom, this kind of formalized learning environment definitely has its place. On top of that, each new employee should have a benchmark assessment during a one-on-one session (we’d suggest on live calls) to highlight areas where they need to improve from the start.
Let’s start with the first call resolution definition. A good first call resolution rate varies by industry, but a generally accepted benchmark is around 70-80%. In this article, we will cover everything to know about first call resolution and how to improve the first call resolution rate. What Is First Call Resolution?
According to our 2018 Live Chat Benchmark Report , Comm100’s Chatbot takes care of about 20% of all incoming live chat inquiries alone. Current Chatbot clients demonstrate that they are trailblazing with early-stage technology that is only improving, and that will definitely be a cornerstone of customer contact in years to come.
Before you implement quality assurance, you should set a proper definition of the expected outcome. Look into benchmarking. It might seem that the benchmarking process, on top of assessing interior quality, is very tough. Set clear goals. Do you want the impact of the customer success to retain more customers?
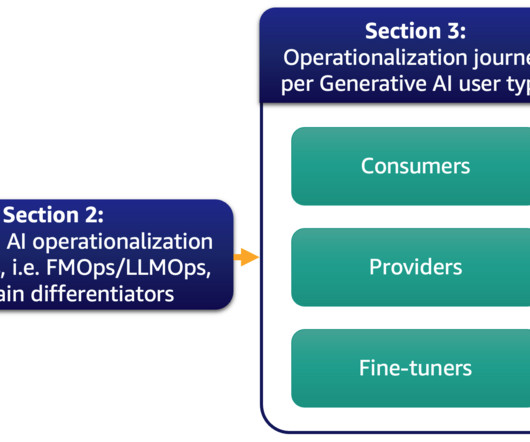
Generative AI definitions and differences to MLOps In classic ML, the preceding combination of people, processes, and technology can help you productize your ML use cases. Some models may be trained on diverse text datasets like internet data, coding scripts, instructions, or human feedback.
29% of live chat users hate scripted responses. According to Comm100’s 2020 Live Chat Benchmark Report , the average wait time between a customer initiating a live chat request being connected with a rep was 46 seconds. The stats below show it most definitely is, and is only getting bigger from here. million by 2023.
29% of live chat users hate scripted responses. According to Comm100’s 2020 Live Chat Benchmark Report , the average wait time between a customer initiating a live chat request being connected with a rep was 46 seconds. The stats below show it most definitely is, and is only getting bigger from here. million by 2023.
Call Recording and Analytics Software Call recordings are analyzed for important moments that indicate whether reps are following or deviating from their call plan/script. Dialogue Scripting for a Seamless User Experience and Empathy Good conversations require so much more than just a simple response.
And it is unclear what it offers — definitely not something you’d want to waste your time and energy on. It categorizes the prospects based on their availability, lead quality, likelihood of conversion, and other internal benchmarks so your agents know the precise time to make the call.
Here are the definitions to the top seven bot-specific terms you need to know: Intents: An intent is the intention of a visitor. Decision Tree: An “If this… then that” framework that guides the customer to choose from a list of pre-defined scripts and options. This framework can be presented either through keywords or buttons.
Look at the product from the customers’ point of view to better model your contact center scripts. Create Policies, SOPs, and Benchmarks A clear set of instructions and policies is necessary for any machinery or operation to execute flawlessly. You can further categorize the scripts to help with a more extensive training session.
Hint: Your customers definitely want the option to message you. While long features lists seem like an easy way to benchmark vendors, be sure to ask how those features work in the real world. Just like call scripts for agents, messaging templates ensure faster response times and help agents speak with a unified brand voice.
The Number 1 Benefit of Deploying Self-Service as a Contact Center Of all the benefits which we will discuss further in this article, one definitely stands out as the most compelling incentive for contact centers to implement a self-service system. You guessed it, it’s money. Here’s the simple math.
Companies should consider by using benchmarking to determine how their reps’ performance. These external benchmarking is some time with best actions ad QA experts those who can remain impartial and objective. Provide Top-Notch Scripts. The real-time analysis and execution of benchmarking available with their console.
Responding to customer issues quickly through the pre-populated canned responses or scripts can work perfectly well if all you are talking with are robots facing a similar set of issues. There are constant calls, an urge to meet deadlines and a benchmark. Make them share insights via surveys and polls using good online survey software.
Call on experienced managers for guidance in setting up benchmarks. “Experienced call center managers are helpful in setting up the initial performance benchmarks for a new outbound call center program. These benchmarks are, at first, estimated based on the past performance of similar outbound call center projects.
Definition of customer success playbook. In a nutshell, a playbook functions as a script for various scenarios that may arise throughout a customer’s lifecycle and which your CSM should be able to handle. So, let us get started. It can be used for event-based or time-bound scenarios (such as three months before a renewal) (e.g.,
Over the four years the program has been in place, all key program metrics have shown progressive, benchmark-exceeding improvement. Check out some data from our recent research: In our Q3 2018 Consumer Benchmark Study, we found that 40% of full time U.S. I mean, really listen and act on what they say. They teach. They reward.
It depends on an organization’s structure, its products (or services), as well as what’s the definition of a “good” customer experience for the organization. The AHT benchmark for financial services as well as the business and IT sector is four minutes and 45 seconds. The telecom sector has an AHT of eight minutes and 30 seconds.
Yeah, definitely. And we also do a couple benchmarking surveys a year for member companies and also have an online forum, some private meeting groups for members to be able to exchange digitally in that environment. Definitely. So I like that you reminded us all of that. Thank you, because I think sometimes we forget that.
Each trained model needs to be benchmarked against many tasks not only to assess its performances but also to compare it with other existing models, to identify areas that needs improvements and finally, to keep track of advancements in the field. These benchmarks have leaderboards that can be used to compare and contrast evaluated models.
But, before that, let us look at the definition of conversation intelligence. It identifies calls that need immediate attention by finding out things like customer objection, mention of a competitor, compliance gap or script deviation, etc. What is conversation intelligence? Salient features.
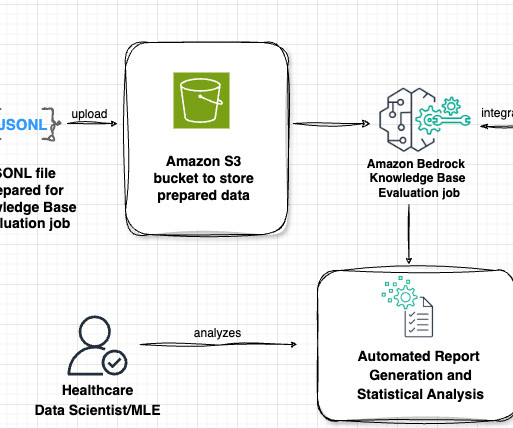
This approach not only establishes new benchmarks for medical RAG evaluation, but also provides practitioners with practical tools to build more reliable and accurate healthcare AI applications that can be trusted in clinical settings. No definite pneumonia. n- Number each impression. n- Order impressions by importance.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content