This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. The Anthropic Claude 3 Haiku model then processes the documents and returns the desired information, streamlining the entire workflow.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
All text-to-image benchmarks are evaluated using Recall@5 ; text-to-text benchmarks are evaluated using NDCG@10. Text-to-text benchmark accuracy is based on BEIR, a dataset focused on out-of-domain retrievals (14 datasets). Generic text-to-image benchmark accuracy is based on Flickr and CoCo. jpg") or doc.endswith(".png"))
What does it take to engage agents in this customer-centric era? Download our study of 1,000 contact center agents in the US and UK to find out what major challenges are facing contact center agents today – and what your company can do about it.
Average Handle Time (AHT) gives an accurate, real-time measurement of the usual amount of time it takes to handle an interaction from start to finish, from the initiation of the call to the time your organization’s call center agents are spending on the phone with individual callers and handling any follow-up tasks, such as documentation.
As a result, agents can spend less time documenting interaction details and get back to helping the next customer faster. These solutions are setting new benchmarks for customer satisfaction by empowering organizations to solve more issues faster at a lower cost.
To help determine whether a serverless endpoint is the right deployment option from a cost and performance perspective, we have developed the SageMaker Serverless Inference Benchmarking Toolkit , which tests different endpoint configurations and compares the most optimal one against a comparable real-time hosting instance.
The best strategy is to use a combination of data reports and benchmarking to ensure your findings reflect “the big picture” Creating a Customer Service Strategy That Drives Business Growth. How to Establish a Net Promoter Score Benchmark. Benchmarking isn’t just about improving your personal best.
A survey of 1,000 contact center professionals reveals what it takes to improve agent well-being in a customer-centric era. This report is a must-read for contact center leaders preparing to engage agents and improve customer experience in 2019.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
Besides the efficiency in system design, the compound AI system also enables you to optimize complex generative AI systems, using a comprehensive evaluation module based on multiple metrics, benchmarking data, and even judgements from other LLMs. Additionally, the question-answer pairs are used as training samples for the model fine-tuning.
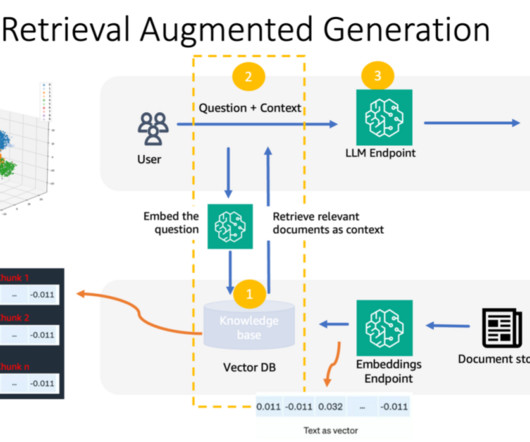
Optimized for search and retrieval, it streamlines querying LLMs and retrieving documents. Build sample RAG Documents are segmented into chunks and stored in an Amazon Bedrock Knowledge Bases (Steps 24). For this purpose, LangChain provides a WebBaseLoader object to load text from HTML webpages into a document format.
In September of 2023, we announced the launch of Amazon Titan Text Embeddings V1, a multilingual text embeddings model that converts text inputs like single words, phrases, or large documents into high-dimensional numerical vector representations. In this benchmark, 33 different text embedding models were evaluated on the MTEB tasks.
By using the same evaluator model across all comparisons, youll get consistent benchmarking results to help identify the optimal model for your use case. The following best practices will help you establish standardized benchmarking when comparing different foundation models. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
Your task is to understand a system that takes in a list of documents, and based on that, answers a question by providing citations for the documents that it referred the answer from. Our dataset includes Q&A pairs with reference documents regarding AWS services. The following table shows an example.
The challenge: Resolving application problems before they impact customers New Relic’s 2024 Observability Forecast highlights three key operational challenges: Tool and context switching – Engineers use multiple monitoring tools, support desks, and documentation systems.
This centralized system consolidates a wide range of data sources, including detailed reports, FAQs, and technical documents. The system integrates structured data, such as tables containing product properties and specifications, with unstructured text documents that provide in-depth product descriptions and usage guidelines.
Consider benchmarking your user experience to find the best latency for your use case, considering that most humans cant read faster than 225 words per minute and therefore extremely fast response can hinder user experience. In such scenarios, you want to optimize for TTFT. Users prefer accurate responses over quick but less reliable ones.
Customer success plans are proposals that document your clients’ goals and how you will help achieve them. A set of key performance indicators and benchmarks to track and measure client progress towards goals. You could then define four minutes and three minutes as benchmarks along your customer’s path to their goal.
The best strategy is to use a combination of data reports and benchmarking to ensure your findings reflect “the big picture” Creating a Customer Service Strategy That Drives Business Growth. How to Establish a Net Promoter Score Benchmark. Benchmarking isn’t just about improving your personal best.
Jamba-Instruct is built by AI21 Labs, and most notably supports a 256,000-token context window, making it especially useful for processing large documents and complex Retrieval Augmented Generation (RAG) applications. Prompt guidance for Jamba-Instruct can be found in the AI21 model documentation.
Its agent for software development can solve complex tasks that go beyond code suggestions, such as building entire application features, refactoring code, or generating documentation. Attendees will learn practical applications of generative AI for streamlining and automating document-centric workflows. Hear from Availity on how 1.5
Customer benchmarking — the practice of identifying where a customer can improve or is already doing well by comparing to other customers – helps Customer Success Managers to deliver unique value to their customers. I’ve found that SaaS vendors use seven distinct strategies to empower CSMs with customer benchmarking.
You can use the BGE embedding model to retrieve relevant documents and then use the BGE reranker to obtain final results. On Hugging Face, the Massive Text Embedding Benchmark (MTEB) is provided as a leaderboard for diverse text embedding tasks. It currently provides 129 benchmarking datasets across 8 different tasks on 113 languages.
You can use this tutorial as a starting point for a variety of chatbot-based solutions for customer service, internal support, and question answering systems based on internal and private documents. This makes the models especially powerful at tasks such as clustering for long documents like legal text or product documentation.
This post describes how to get started with the software development agent, gives an overview of how the agent works, and discusses its performance on public benchmarks. We are grateful to the team releasing and maintaining this benchmark. We are proud to be able to share our state-of-the-art results on this benchmark.
In addition, RAG architecture can lead to potential issues like retrieval collapse , where the retrieval component learns to retrieve the same documents regardless of the input. Lack of standardized benchmarks – There are no widely accepted and standardized benchmarks yet for holistically evaluating different capabilities of RAG systems.
For more details about how to run graph multi-task learning with GraphStorm, refer to Multi-task Learning in GraphStorm in our documentation. we released a LM+GNN benchmark using the large graph dataset, Microsoft Academic Graph (MAG), on two standard graph ML tasks: node classification and link prediction. Dataset Num. of nodes Num.
This data allows them to bolster those areas to meet or even surpass industry standard call center KPI benchmarks, which is essential for your brand’s reputation. Wait time should be one of your most important call center KPI benchmarks. Proper documentation is key to preserving your brand’s reputation.
When a customer has a production-ready intelligent document processing (IDP) workload, we often receive requests for a Well-Architected review. To follow along with this post, you should be familiar with the previous posts in this series ( Part 1 and Part 2 ) and the guidelines in Guidance for Intelligent Document Processing on AWS.
Outcome success plans focus on capturing mutual objectives, documenting the steps toward achieving them, and sharing information between both clients and your own internal teams—driving interconnectivity and displaying progress through one easily accessed live portal. Document and capture new initiatives as they arise.
Procedures also document guidelines for notifying managers and leaders or creating action plans if performance falls below a certain level.” The corporate strategy has already been defined and is evident in the Mission Statement, Vision and Values documents.
Setting survey response rate benchmarks can help you assess the performance and overall growth of your customer experience management (CEM) system. While benchmarking is a common process in many companies, the exact steps and data collected need to be adjusted to each organization’s requirements.
Through comparative benchmarking tests, we illustrate how deploying FMs in Local Zones closer to end users can significantly reduce latencya critical factor for real-time applications such as conversational AI assistants. Detailed instructions for installing LLMPerf and executing the load testing are available in the projects documentation.
Amazon Comprehend is a natural-language processing (NLP) service you can use to automatically extract entities, key phrases, language, sentiments, and other insights from documents. All you need to do is load your dataset of documents and annotations, and use the Amazon Comprehend console, AWS CLI, or APIs to create the model.
The healthcare industry generates and collects a significant amount of unstructured textual data, including clinical documentation such as patient information, medical history, and test results, as well as non-clinical documentation like administrative records. read()) answer = response_body.get("content")[0].get("text")
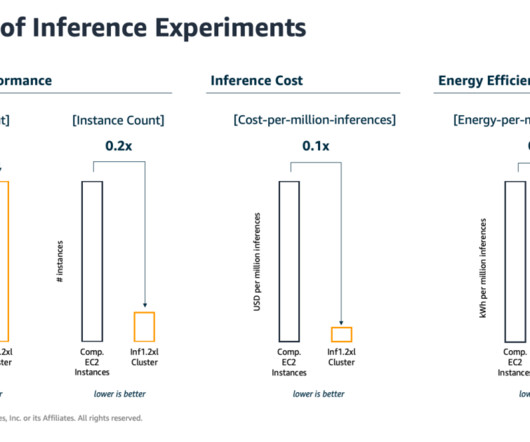
AWS Inferentia and AWS Trainium for sustainable ML To provide you with realistic numbers of the energy savings potential of AWS Inferentia and AWS Trainium in a real-world application, we have conducted several power draw benchmark experiments. Therefore, we used common customer-inspired ML use cases for benchmarking and testing.
Government agencies summarize lengthy policy documents and reports to help policymakers strategize and prioritize goals. By creating condensed versions of long, complex documents, summarization technology enables users to focus on the most salient content. This leads to better comprehension and retention of critical information.
Model choices – SageMaker JumpStart offers a selection of state-of-the-art ML models that consistently rank among the top in industry-recognized HELM benchmarks. For instance, a financial firm might prefer its Q&A bot to source answers from its latest internal documents, ensuring accuracy and compliance with its business rules.
However, I have found a few of the benchmarking models used by technology research companies & marketing professional bodies useful and have produced my own (on basis of 13 years experience in creating & leading such functions).
What is Mixtral 8x22B Mixtral 8x22B is Mistral AI’s latest open-weights model and sets a new standard for performance and efficiency of available foundation models , as measured by Mistral AI across standard industry benchmarks. making the model available for exploring, testing, and deploying.
Tokens We evaluated SageMaker endpoint hosted DeepSeek-R1 distilled variants on performance benchmarks using two sample input token lengths. DeepSeek-R1-Distill-Llama-8B DeepSeek-R1-Distill-Llama-8B was benchmarked across ml.g5.2xlarge , ml.g5.12xlarge , ml.g6e.2xlarge Then we repeated the test with concurrency 10.
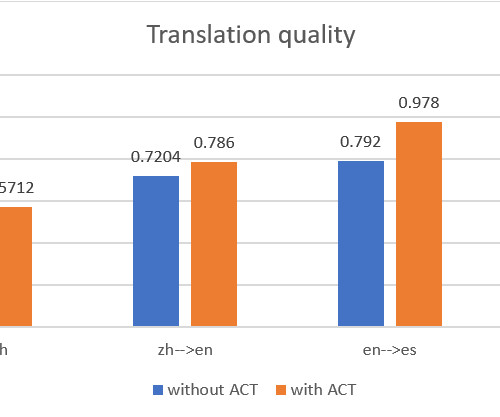
First, we put the source documents, reference documents, and parallel data training set in an S3 bucket. The source_data folder contains the source documents before the translation; the generated documents after the batch translation are put in the output folder.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content