This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At the heart of most technological optimizations implemented within a successful call center are fine-tuned metrics. Keeping tabs on the right metrics can make consistent improvement notably simpler over the long term. However, not all metrics make sense for a growing call center to monitor. Peak Hour Traffic.
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics? Each provisioned node was r7g.4xlarge,
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
All text-to-image benchmarks are evaluated using Recall@5 ; text-to-text benchmarks are evaluated using NDCG@10. Text-to-text benchmark accuracy is based on BEIR, a dataset focused on out-of-domain retrievals (14 datasets). Generic text-to-image benchmark accuracy is based on Flickr and CoCo. jpg") or doc.endswith(".png"))
What does it take to engage agents in this customer-centric era? Download our study of 1,000 contact center agents in the US and UK to find out what major challenges are facing contact center agents today – and what your company can do about it.
This approach allows organizations to assess their AI models effectiveness using pre-defined metrics, making sure that the technology aligns with their specific needs and objectives. referenceResponse (used for specific metrics with ground truth) : This key contains the ground truth or correct response.
Current RAG pipelines frequently employ similarity-based metrics such as ROUGE , BLEU , and BERTScore to assess the quality of the generated responses, which is essential for refining and enhancing the models capabilities. More sophisticated metrics are needed to evaluate factual alignment and accuracy.
Besides the efficiency in system design, the compound AI system also enables you to optimize complex generative AI systems, using a comprehensive evaluation module based on multiple metrics, benchmarking data, and even judgements from other LLMs. The DSPy lifecycle is presented in the following diagram in seven steps.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. These metrics provide high precision but are limited to specific use cases due to limited ground truth data.
A survey of 1,000 contact center professionals reveals what it takes to improve agent well-being in a customer-centric era. This report is a must-read for contact center leaders preparing to engage agents and improve customer experience in 2019.
To help determine whether a serverless endpoint is the right deployment option from a cost and performance perspective, we have developed the SageMaker Serverless Inference Benchmarking Toolkit , which tests different endpoint configurations and compares the most optimal one against a comparable real-time hosting instance.
To effectively optimize AI applications for responsiveness, we need to understand the key metrics that define latency and how they impact user experience. These metrics differ between streaming and nonstreaming modes and understanding them is crucial for building responsive AI applications.
The best strategy is to use a combination of data reports and benchmarking to ensure your findings reflect “the big picture” Creating a Customer Service Strategy That Drives Business Growth. NPS is one of the strongest customer service metrics available to a call center. How to Establish a Net Promoter Score Benchmark.
The challenge: Resolving application problems before they impact customers New Relic’s 2024 Observability Forecast highlights three key operational challenges: Tool and context switching – Engineers use multiple monitoring tools, support desks, and documentation systems. New Relic AI conducts a comprehensive analysis of the checkout service.
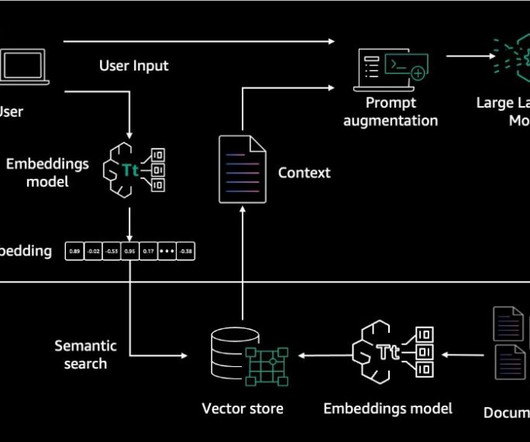
As new embedding models are released with incremental quality improvements, organizations must weigh the potential benefits against the associated costs of upgrading, considering factors like computational resources, data reprocessing, integration efforts, and projected performance gains impacting business metrics.
And that time is quickly fading away, along with once-common practices like writing checks to pay monthly bills and physically signing mortgage application documents. It's easier to sell a metric to leadership if other high-performing institutions are using it. A metric that everyone understands is a metric that everyone can act on.
In addition, RAG architecture can lead to potential issues like retrieval collapse , where the retrieval component learns to retrieve the same documents regardless of the input. This makes it difficult to apply standard evaluation metrics like BERTScore ( Zhang et al.
This post describes how to get started with the software development agent, gives an overview of how the agent works, and discusses its performance on public benchmarks. This is an important metric because our customers want to use the agent to solve real-world problems and we are proud to report a state-of-the-art pass rate.
They are an easy way to track metrics and discover trends within your agents. They fall into the same bucket as quality, call control, customer satisfaction, absenteeism and other metrics. They engage in performance management, they set targets, they may even terminate employees for these metrics.” This is short-sighted.
This post focuses on evaluating and interpreting metrics using FMEval for question answering in a generative AI application. FMEval is a comprehensive evaluation suite from Amazon SageMaker Clarify , providing standardized implementations of metrics to assess quality and responsibility. Question Answer Fact Who is Andrew R.
Logging and monitoring You can monitor SageMaker AI using Amazon CloudWatch , which collects and processes raw data into readable, near real-time metrics. These metrics are retained for 15 months, allowing you to analyze historical trends and gain deeper insights into your applications performance and health. 2xlarge , and ml.g6e.12xlarge
Government agencies summarize lengthy policy documents and reports to help policymakers strategize and prioritize goals. By creating condensed versions of long, complex documents, summarization technology enables users to focus on the most salient content. This leads to better comprehension and retention of critical information.
The best strategy is to use a combination of data reports and benchmarking to ensure your findings reflect “the big picture” Creating a Customer Service Strategy That Drives Business Growth. NPS is one of the strongest customer service metrics available to a call center. How to Establish a Net Promoter Score Benchmark.
Customer benchmarking — the practice of identifying where a customer can improve or is already doing well by comparing to other customers – helps Customer Success Managers to deliver unique value to their customers. I’ve found that SaaS vendors use seven distinct strategies to empower CSMs with customer benchmarking.
When a customer has a production-ready intelligent document processing (IDP) workload, we often receive requests for a Well-Architected review. To follow along with this post, you should be familiar with the previous posts in this series ( Part 1 and Part 2 ) and the guidelines in Guidance for Intelligent Document Processing on AWS.
At Interaction Metrics, we take a smarter approach. Thats where Interaction Metrics comes in! We also benchmark your NPS against industry standards, providing critical insights that show where you stand compared to competitors. Dig Deeper into Your Scores Your NPS is an outcome, not an isolated metric. The result?
Through comparative benchmarking tests, we illustrate how deploying FMs in Local Zones closer to end users can significantly reduce latencya critical factor for real-time applications such as conversational AI assistants. Detailed instructions for installing LLMPerf and executing the load testing are available in the projects documentation.
For more details about how to run graph multi-task learning with GraphStorm, refer to Multi-task Learning in GraphStorm in our documentation. we released a LM+GNN benchmark using the large graph dataset, Microsoft Academic Graph (MAG), on two standard graph ML tasks: node classification and link prediction. Dataset Num. of nodes Num.
Setting survey response rate benchmarks can help you assess the performance and overall growth of your customer experience management (CEM) system. While benchmarking is a common process in many companies, the exact steps and data collected need to be adjusted to each organization’s requirements.
Amazon Comprehend is a natural-language processing (NLP) service you can use to automatically extract entities, key phrases, language, sentiments, and other insights from documents. All you need to do is load your dataset of documents and annotations, and use the Amazon Comprehend console, AWS CLI, or APIs to create the model.
This data allows them to bolster those areas to meet or even surpass industry standard call center KPI benchmarks, which is essential for your brand’s reputation. Improving your companies performance requires that you take a proactive approach with these metrics. Customers do not want to explain their issues over and over again.
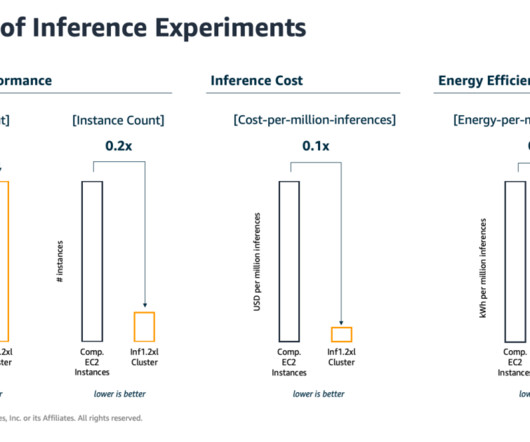
The Carbontracker study estimates that training GPT-3 from scratch may emit up to 85 metric tons of CO2 equivalent, using clusters of specialized hardware accelerators. Therefore, we used common customer-inspired ML use cases for benchmarking and testing. The results are reported in the following sections.
We demonstrate this using an Amazon Comprehend custom classification to build a multi-label custom classification model, and provide guidelines on how to prepare the training dataset and tune the model to meet performance metrics such as accuracy, precision, recall, and F1 score. For Input format , choose One document per line.
Reducing customer churn is impossible if you don’t have access to the right insights to analyze and use as a benchmark. Calculating the metrics is simple. Training Documentation. For this, you can start with employee training documentation. That way you can create documentation for commonly searched terms too.
These include the ability to analyze massive amounts of data, identify patterns, summarize documents, perform translations, correct errors, or answer questions. This involves documenting data lineage, data versioning, automating data processing, and monitoring data management costs.
Live Chat Benchmark Report 2022. Download our annual Live Chat Benchmark Report for free access to the latest live chat data alongside best practices and optimization. Here are some things to look for with this metric: How many chats are agents accepting as opposed to rejecting or passing off to other agents? Click here.
Review Your Metrics. Take a look at the metrics you’re currently tracking. If you’re struggling to decide on which metrics to use, we’ve suggested some options here. Geckoboard suggests growing teams must track these five customer support metrics : First Reply Time. Are you happy with your CSAT results
What is Mixtral 8x22B Mixtral 8x22B is Mistral AI’s latest open-weights model and sets a new standard for performance and efficiency of available foundation models , as measured by Mistral AI across standard industry benchmarks. making the model available for exploring, testing, and deploying.
Its not just about tracking basic metrics anymoreits about gaining comprehensive insights that drive strategic decisions. Key Metrics for Measuring Success Tracking the right performance indicators separates thriving call centers from struggling operations. This metric transforms support from cost center to growth driver.
As a next step, you can explore fine-tuning your own LLM with Medusa heads on your own dataset and benchmark the results for your specific use case, using the provided GitHub repository. However, for better results, its generally recommended to set the number of epochs to at least 2 or 3.
Back in college, I took a summer job that made me use Slack, email, a call center platform, and an internal documentation system simultaneously. Document and define your communication standards and culture in a place where all new and current employees can easily access them. Set Up New Hires on All Technology.
The Executive Guide to Improving 6 Contact Center Metrics. TIP: Call center scripts should be considered living documents, as they’ll need to be regularly updated to align with new industry trends, department goals, and both agent and customer feedback. Improve the Customer Journey. Involve Your Agents in Strategic Planning.
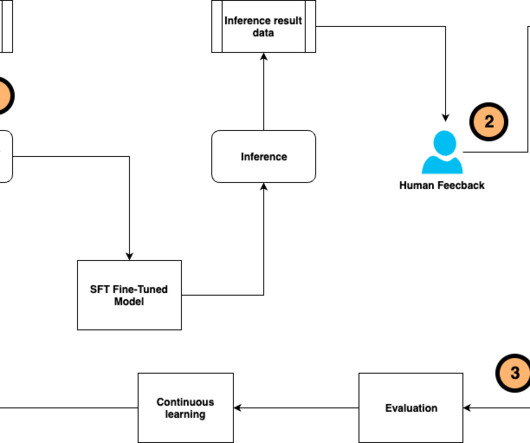
Laying the groundwork: Collecting ground truth data The foundation of any successful agent is high-quality ground truth data—the accurate, real-world observations used as reference for benchmarks and evaluating the performance of a model, algorithm, or system. Implement citation mechanisms to reference source documents in responses.
We estimated these numbers by running benchmark tests on different dataset sizes from 0.5 The configuration tests include objective metrics such as F1 scores and Precision, and tune algorithm hyperparameters to produce optimal scores for these metrics. MB to 100 MB in size.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content