This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
Average Handle Time (AHT) gives an accurate, real-time measurement of the usual amount of time it takes to handle an interaction from start to finish, from the initiation of the call to the time your organization’s call center agents are spending on the phone with individual callers and handling any follow-up tasks, such as documentation.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
Encourage agents to cheer up callers with more flexible scripting. “A 2014 survey suggested that 69% of customers feel that their call center experience improves when the customer service agent doesn’t sound as though they are reading from a script. Minimise language barriers with better hires.
Training documentation needs to be updated regularly, and on-going training is important for improving efficiency. Bill Dettering is the CEO and Founder of Zingtree , a SaaS solution for building interactive decision trees and agent scripts for contact centers (and many other industries). Bill Dettering. Jeff Greenfield.
Your task is to understand a system that takes in a list of documents, and based on that, answers a question by providing citations for the documents that it referred the answer from. Our dataset includes Q&A pairs with reference documents regarding AWS services. The following table shows an example.
The documents provided show that the development of these systems had a profound effect on the way people and goods were able to move around the world. The documents show that the development of railroads and steamships made it possible for goods to be transported more quickly and efficiently than ever before.
We also included a data exploration script to analyze the length of input and output tokens. For demonstration purposes, we select 3,000 samples and split them into train, validation, and test sets. You need to run the Load and prepare the dataset section of the medusa_1_train.ipynb to prepare the dataset for fine-tuning.
Keep them up to date on new policies, best customer support practices, adjustments to the call center script, and more. TIP: Call center scripts should be considered living documents, as they’ll need to be regularly updated to align with new industry trends, department goals, and both agent and customer feedback.
Refer to the appendix for instance details and benchmark data. Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions. To access the code and documentation, refer to the GitHub repo.
Flip the script With testingRTC, you only need to write scripts once, you can then run them multiple times and scale them up or down as you see fit. testingRTC simulates any user behavior using our powerful Nightwatch scripting, you can manage these scripts via our handy git integration.
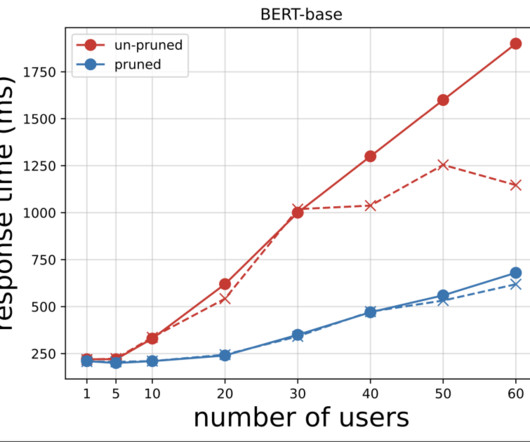
The team’s early benchmarking results show 7.3 The baseline model used in these benchmarking is a multi-layer perceptron neural network with seven dense fully connected layers and over 200 parameters. The following table summarizes the benchmarking result on ml.p3.16xlarge SageMaker training instances. Number of Instances.
Note that your model artifacts also include an inference script for preprocessing and postprocessing. If you don’t provide an inference script, the default inference handlers for the container you have chosen will be implemented. For these two frameworks, provide the model artifacts in the format the container expects.
SaaS success outcomes can be defined in terms of measurable digital benchmarks. Laying out a customer journey map allows CS teams to set measurable goals for each customer experience stage, set benchmarks, and implement automated strategies corresponding to mapped stages. Here are five keys to doing it right.
For more information on the TPC-H data, its database entities, relationships, and characteristics, refer to TPC Benchmark H. We use a preprocessing script to connect and query data from a PrestoDB instance using the user-specified SQL query in the config file. For more information on processing jobs, see Process data.
Read Email Response Times: Benchmarks and Tips for Support for practical advice. Tarek Khalil took to Twitter to document his quest to cancel his Baremetrics account. This one was a robot, but there are plenty of real humans who aren’t able to break from the script even when the play suddenly has a new act. How Bare you?
Amazon Comprehend is a natural-language processing (NLP) service you can use to automatically extract entities, key phrases, language, sentiments, and other insights from documents. All you need to do is load your dataset of documents and annotations, and use the Amazon Comprehend console, AWS CLI, or APIs to create the model.
To achieve this multi-user environment, you can take advantage of Linux’s user and group mechanism and statically create multiple users on each instance through lifecycle scripts. Create a HyperPod cluster with an SSSD-enabled lifecycle script Next, you create a HyperPod cluster with LDAPS/Active Directory integration.
SageMaker starts and manages all of the necessary Amazon Elastic Compute Cloud (Amazon EC2) instances for us, supplies the appropriate Hugging Face container, uploads the specified scripts, and downloads data from our S3 bucket to the container to /opt/ml/input/data. You can follow the steps in the documentation to enable model access.
To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script. In this section, we only call out a few main steps with code snippets from the ready-to-use training script train_gpt_simple.py. The notebook uses the script data_prep_512.py Benchmarking performance. return loss.
These images contain the Neuron SDK (excluding the Neuron driver, which runs directly on the Trn1 instances), PyTorch training script, and required dependencies. Create a training container image Next, we need to create a training container image that includes the PyTorch training script along with any dependencies.
The method is trained on a dataset of video clips and achieves state-of-the-art results on fashion video and human dance synthesis benchmarks, demonstrating its ability to animate arbitrary characters while maintaining appearance consistency and temporal stability. The implementation of AnimateAnyone can be found in this repository.
. * The `if __name__ == "__main__"` block checks if the script is being run directly or imported. To run the script, you can use the following command: ``` python hello.py ``` * The output will be printed in the console: ``` Hello, world! Evaluate model on test set, compare to benchmarks, analyze errors and biases.
We first benchmark the performance of our model on a single instance to identify the TPS it can handle per our acceptable latency requirements. Note that the model container also includes any custom inference code or scripts that you have passed for inference. Any issues related to end-to-end latency can then be isolated separately.
Briefly, this is made possible by an installation script specified by CustomActions in the YAML file used for creating the ParallelCluster (see Create ParallelCluster ). You can invoke neuron-top during the training script run to inspect NeuronCore utilization at each node. Complete instructions can be found on GitHub.
Finally, we’ll benchmark performance of 13B, 50B, and 100B parameter auto-regressive models and wrap up with future work. A ready-to-use training script for GPT-2 model can be found at train_gpt_simple.py. For training a different model type, you can follow the API document to learn about how to apply SMP APIs.
AlexaTM 20B has shown competitive performance on common natural language processing (NLP) benchmarks and tasks, such as machine translation, data generation and summarization. To use a large language model in SageMaker, you need an inferencing script specific for the model, which includes steps like model loading, parallelization and more.
To help you get a better understanding of how much customers appreciate access to live chat, consider the eDigital Customer Service Benchmark survey of 2000 consumers that found that live chat had the highest customer satisfaction levels at 73%, as compared to 61% for email support and only 44% for traditional phone support.
To demonstrate the practical aspect of your customer profiles, write up role-play scripts for each profile and have staff act them out. Because this will be a living document, it’s important to keep track of where this document lives to minimize the chances of your employees using outdated information. Act it out.
Another example might be a healthcare provider who uses PLM inference endpoints for clinical document classification, named entity recognition from medical reports, medical chatbots, and patient risk stratification. We use the Recognizing Textual Entailment dataset from the GLUE benchmarking suite. training.py ).
DL scripts often require boilerplate code, notably the aforementioned double for loop structure that splits the dataset into minibatches and the training into epochs. At the time of this writing, it supports PyTorch and includes 25 techniques—called methods in the MosaicML world—along with standard models, datasets, and benchmarks.
Laying the groundwork: Collecting ground truth data The foundation of any successful agent is high-quality ground truth data—the accurate, real-world observations used as reference for benchmarks and evaluating the performance of a model, algorithm, or system. Implement citation mechanisms to reference source documents in responses.
Strategies to Improve Customer Satisfaction KPIs: Clearly define each metric and establish benchmarks. Benchmark: Many organizations aim for an AHT of 480 seconds (8 minutes), depending on industry standards. Industry Standard: The 80/20 rule (80% of calls answered within 20 seconds) is a common benchmark.
The following figure shows a performance benchmark of fine-tuning a RoBERTa model on Amazon EC2 p4d.24xlarge inference with AWS Graviton processors for details on AWS Graviton-based instance inference performance benchmarks for PyTorch 2.0. Run your DLC container with a model training script to fine-tune the RoBERTa model.
We encourage you to read carefully through the datasets documentation ( Sophos/Reversing Labs README, PE Malware Machine Learning Dataset ) to safely handle the malware objects. The following parameters are required to run the script successfully: STACK_NAME – The CloudFormation stack name. AWS_ACCOUNT – AWS Account ID.
For almost 40 years, we have worked tirelessly at aiding businesses with actionable reporting, simplified scripting, and customized solutions. Documentation Enhances the Workplace. Customer Service benchmarks show the importance of a great procedure! AI powers innovation and success for your company! Free your Phone!
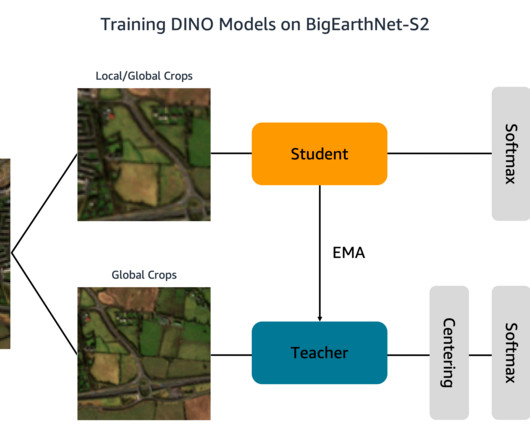
Prepare the BigEarthNet-S2 dataset BigEarthNet-S2 is a benchmark archive that contains 590,325 multispectral images collected by the Sentinel-2 satellite. The images document the land cover, or physical surface features, of ten European countries between June 2017 and May 2018. file: init_distributed_mode function in the util.py
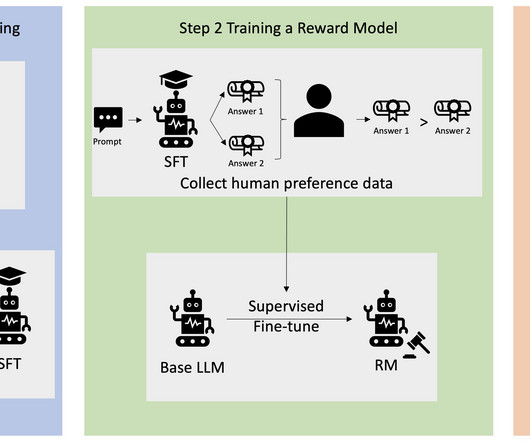
The script initiates the SFT model using its current weights and then optimizes them under the guidance of a reward model, so that the resulting RLHF trained model aligns with human preference. For more information, refer to the AWS Sagemaker Developer Guide’s documentation on “ Clean Up ”. configs/accelerate/zero2-bf16.yaml
Their research indicates that zero-shot CoT, using the same single-prompt template, significantly outperforms zero-shot FM performances on diverse benchmark reasoning tasks. Writing assistance – RAG can suggest relevant content, facts, and talking points to help you write documents such as articles, reports, and emails more efficiently.
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions. To learn more, refer to API documentation.
Each specialist is underpinned by thousands of pages of domain documentation, which feeds into the RAG system and is used to train smaller, specialized models with Amazon SageMaker JumpStart. Document assembly Gather all relevant documents that will be used for training.
The steps are described in the AWS Neuron Documentation. She is also part of the Technical Field Community dedicated to hardware acceleration and helps with testing and benchmarking AWS Inferentia and AWS Trainium workloads. and a C++17 compatible compiler in a Linux environment. customop_ml/ neuron repository example, we have a build.py
Starting with our tried and true templates, your account manager will suggest scripts and then cater them to your exact needs. . Documentation Enhances the Workplace. Customer Service benchmarks show the importance of a great procedure! AI powers innovation and success for your company! Free your Phone!
Decide how much time you’ll dedicate to upfront training, what team members will own agent training, and what kind of documentation you need to support your efforts. You document those processes as a reference point for your team. Document the essentials that your agents and leaders need to know to be successful and meet expectations.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content