This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
A new list of benchmarks is published each year by ACSI, with minor quarterly updates. . Below is the complete list of the newest CSAT benchmarks. Internet Search Engines and Information: 79%. Click here to download the current industry benchmarks. According to the ACSI, the current overall U.S. Airlines: 73%. Banks: 81%.
The challenge: Resolving application problems before they impact customers New Relic’s 2024 Observability Forecast highlights three key operational challenges: Tool and context switching – Engineers use multiple monitoring tools, support desks, and documentation systems.
All text-to-image benchmarks are evaluated using Recall@5 ; text-to-text benchmarks are evaluated using NDCG@10. Text-to-text benchmark accuracy is based on BEIR, a dataset focused on out-of-domain retrievals (14 datasets). Generic text-to-image benchmark accuracy is based on Flickr and CoCo.
Consider benchmarking your user experience to find the best latency for your use case, considering that most humans cant read faster than 225 words per minute and therefore extremely fast response can hinder user experience. In such scenarios, you want to optimize for TTFT. Users prefer accurate responses over quick but less reliable ones.
Curated judge models : Amazon Bedrock provides pre-selected, high-quality evaluation models with optimized prompt engineering for accurate assessments. Expert analysis : Data scientists or machine learning engineers analyze the generated reports to derive actionable insights and make informed decisions. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
Compound AI system and the DSPy framework With the rise of generative AI, scientists and engineers face a much more complex scenario to develop and maintain AI solutions, compared to classic predictive AI. In the next section, we discuss using a compound AI system to implement this framework to achieve high versatility and reusability.
It consists of the following key components: Speech recognition The customers spoken language is captured and converted into text using Amazon Transcribe , which serves as the speech recognition engine. The transcript (text) is then fed into the machine translation engine.
Google Scholar is a search engine dedicated to finding academic research. If you want to benchmark your organization’s performance in the new world of behavioral economics against other companies, take our short questionnaire. We always connect the academic findings to Customer Experience on the podcast (and in our most recent book.)
Model choices – SageMaker JumpStart offers a selection of state-of-the-art ML models that consistently rank among the top in industry-recognized HELM benchmarks. We also use Vector Engine for Amazon OpenSearch Serverless (currently in preview) as the vector data store to store embeddings. An OpenSearch Serverless collection.
This requirement translates into time and effort investment of trained personnel, who could be support engineers or other technical staff, to review tens of thousands of support cases to arrive at an even distribution of 3,000 per category. Sonnet prediction accuracy through prompt engineering. We expect to release version 4.2.2
Now, the question is—what are the metrics and figures to benchmark for every industry? The higher its quality, the lower its CPC, and the better its position on search engines. As with previous benchmark reports, the numbers have been consistently high for these industries. Average Cost per Click (CPC). Photo by LOCALiQ.
ONNX Runtime is the runtime engine used for model inference and training with ONNX. We also demonstrate the resulting speedup through benchmarking. Benchmark setup We used an AWS Graviton3-based c7g.4xl 1014-aws kernel) The ONNX Runtime repo provides inference benchmarking scripts for transformers-based language models.
Current evaluations from Anthropic suggest that the Claude 3 model family outperforms comparable models in math word problem solving (MATH) and multilingual math (MGSM) benchmarks, critical benchmarks used today for LLMs. Media organizations can generate image captions or video scripts automatically.
Customer benchmarking — the practice of identifying where a customer can improve or is already doing well by comparing to other customers – helps Customer Success Managers to deliver unique value to their customers. I’ve found that SaaS vendors use seven distinct strategies to empower CSMs with customer benchmarking.
Continuous education involves more than glancing at release announcements it includes testing beta features, benchmarking real world results, and actively sharing insights. Engineers versed in the OWASP Top 10 address common security weaknesses with minimal fuss. This method can save hours of coding time and avoid technical debt.
A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard. The Massive Text Embedding Benchmark (MTEB) evaluates text embedding models across a wide range of tasks and datasets.
It simplifies data integration from various sources and provides tools for data indexing, engines, agents, and application integrations. You also define a prompt template following Claude prompt engineering guidelines. LlamaIndex is a framework for building LLM applications.
With a focus on responsible innovation and system-level safety, these new models demonstrate state-of-the-art performance on a wide range of industry benchmarks and introduce features that help you build a new generation of AI experiences. Model Name Model ID Default instance type Supported instance types Llama-3.2-1B 32xlarge Llama-3.2-1B-Instruct
We used the same KPIs as in the previous setup to measure efficiency and performance under these optimized conditions, making sure that cost reduction aligned with our service quality benchmarks. Vladyslav Melnyk is a Senior MLOps Engineer at Automat-it. We conducted the tests in three stages, as described in the following sections.
In this post, we dive deep into the new features with the latest release of LMI DLCs, discuss performance benchmarks, and outline the steps required to deploy LLMs with LMI DLCs to maximize performance and reduce costs. To use SmoothQuant, set option.quantize=smoothquan t with engine = DeepSpeed in serving.properties.
For example, for mixed AI workloads, the AI inference is part of the search engine service with real-time latency requirements. First, we had to experiment and benchmark in order to determine that Graviton3 was indeed the right solution for us. Ratnesh Jamidar is a AVP Engineering at Sprinklr with 8 years of experience.
Use cases we have worked on include: Technical assistance for field engineers – We built a system that aggregates information about a company’s specific products and field expertise. A chatbot enables field engineers to quickly access relevant information, troubleshoot issues more effectively, and share knowledge across the organization.
However, optimizing training performance often requires weeks of iterative testingexperimenting with algorithms, fine-tuning parameters, monitoring training impact, debugging issues, and benchmarking performance.
They Avoid Benchmarking: High-performing contact center leaders do not waste a lot of time benchmarking their contact center performance. Leaders in these contact centers do not forklift leading practices, they elect to quickly re- engineer practices to fit their environment and purpose. They strive for differentiation.
The buffer was implemented after benchmarking the captioning model’s performance. The benchmarking revealed that the model performed optimally when processing batches of images, but underperformed when analyzing individual images. About the authors Vlad Lebedev is a Senior Technology Leader at Mixbook.
Acting as a model hub, JumpStart provided a large selection of foundation models and the team quickly ran their benchmarks on candidate models. Here, Amazon SageMaker Ground Truth allowed ML engineers to easily build the human-in-the-loop workflow (step v). Burak is still a research affiliate in MIT. With a background in visual design.
Welocalize benchmarks the performance of using LLMs and machine translations and recommends using LLMs as a post-editing tool. in Mechanical Engineering from the University of Notre Dame. Max Goff is a data scientist/data engineer with over 30 years of software development experience. She received her Ph.D.
Recommended instances and benchmarks The following table lists all the Meta SAM 2.1 Conclusion In this post, we explored how SageMaker JumpStart empowers data scientists and ML engineers to discover, access, and deploy a wide range of pre-trained FMs for inference, including Metas most advanced and capable models to date. models today.
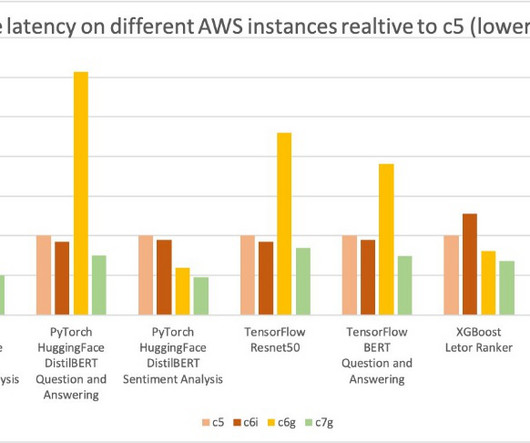
We cover computer vision (CV), natural language processing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking. You can use the sample notebook to run the benchmarks and reproduce the results. Mohan Gandhi is a Senior Software Engineer at AWS.
In this part of the blog series, we review techniques of prompt engineering and Retrieval Augmented Generation (RAG) that can be employed to accomplish the task of clinical report summarization by using Amazon Bedrock. Prompt engineering helps to effectively design and improve prompts to get better results on different tasks with LLMs.
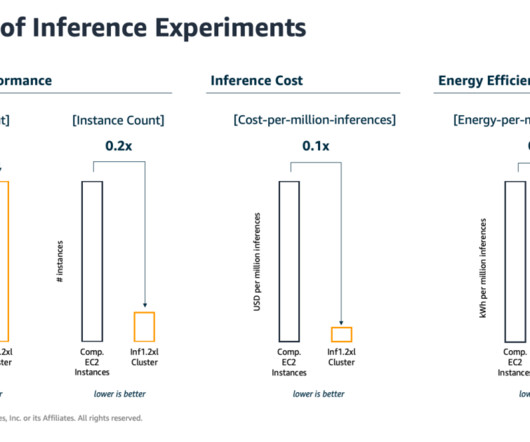
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. Therefore, we used common customer-inspired ML use cases for benchmarking and testing. Performance, Cost and Energy Efficiency Results of Inference Benchmarks AWS Inferentia delivers 6.3
Performance in a contact center refers to how effectively agents manage calls, resolve issues, and meet established benchmarks. HoduCC call and contact center software is engineered to enhance agents’ performance. Set benchmarks against industry standards and collect as much valuable insights as possible.
You can get guidance on the hardware for best price/performance ratio to deploy your endpoint by running a SageMaker Inference Recommender benchmarking job. Alwin (Qiyun) Zhao is a Senior Software Development Engineer with the Amazon SageMaker Inference Platform team. You can expand the Advanced options section to see more options.
Figure 5 offers an overview on generative AI modalities and optimization strategies, including prompt engineering , Retrieval Augmented Generation , and fine-tuning or continued pre-training. Establish a metrics pipeline to provide insights into the sustainability contributions of your generative AI initiatives.
But, many engineering teams have had their fire fighting experiences. Quality levels before a migration can be used as a benchmark to gain full visibility of the impact of infrastructure changes. Cloud solutions boast high reliability and present very compelling arguments. On-premises solutions have their imperfections as well.
Assure your customers with an independent quality benchmark. Benchmarks will need to be met against a number of test criteria for each country in order to be certified in that country. Country-by-country benchmarks on audio quality, connection rates and post-dial delay. Improve your quality management. Global Expansion.
This post is a joint collaboration between Salesforce and AWS and is being cross-published on both the Salesforce Engineering Blog and the AWS Machine Learning Blog. To get started, see this guide. __ About the Authors Pawan Agarwal is the Senior Director of Software Engineering at Salesforce. Salesforce, Inc.
To activate continuous batching, DJServing provides the following additional configurations as per serving.properties: engine =MPI – We encourage you to use the MPI engine for continuous batching. In our analysis, we benchmarked the performance to illustrate the benefits of continuous batching over traditional dynamic batching.
With G5 instances, ML customers get high performance and a cost-efficient infrastructure to train and deploy larger and more sophisticated models for natural language processing (NLP), computer vision (CV), and recommender engine use cases. Benchmarking approach. Benchmarking results. Model Type. twmkn9/bert-base-uncased-squad2.
You can fine-tune the following parameters in serving.properties of the LMI container for using continuous batching: engine – The runtime engine of the code. The following diagram shows the dynamic batching of requests with different input sequence lengths being processed together by the model. Use MPI to enable continuous batching.
A model that generates a comprehensive category tree allows our commercial teams to benchmark our existing product portfolio against that of our competitors, offering a strategic advantage. About the Authors Nafi Ahmet Turgut finished his master’s degree in Electrical & Electronics Engineering and worked as a graduate research scientist.
Prompt engineering Prompt engineering refers to efforts to extract accurate, consistent, and fair outputs from large models, such text-to-image synthesizers or large language models. For more information, refer to EMNLP: Prompt engineering is the new feature engineering.
The procedure is further simplified with the use of Inference Recommender , a right-sizing and benchmarking tool built inside SageMaker. However, you can use any other benchmarking tool. Benchmarking To derive the right scaling policy, the first step in the plan is to determine application behavior on the chosen hardware.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content