This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
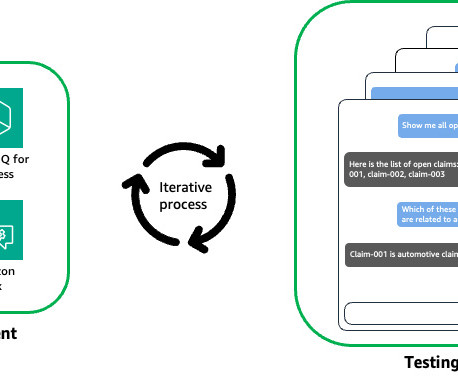
The Amazon EU Design and Construction (Amazon D&C) team is the engineering team designing and constructing Amazon warehouses. The Amazon D&C team implemented the solution in a pilot for Amazon engineers and collected user feedback. During the pilot, users provided 118 feedback responses.
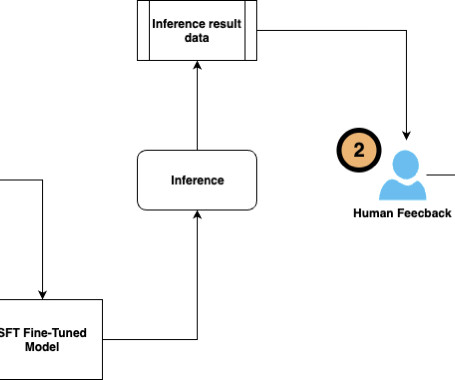
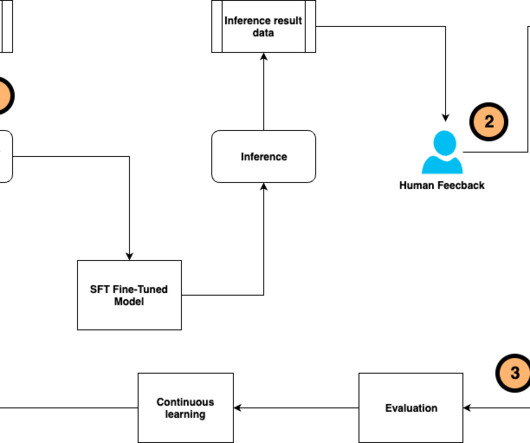
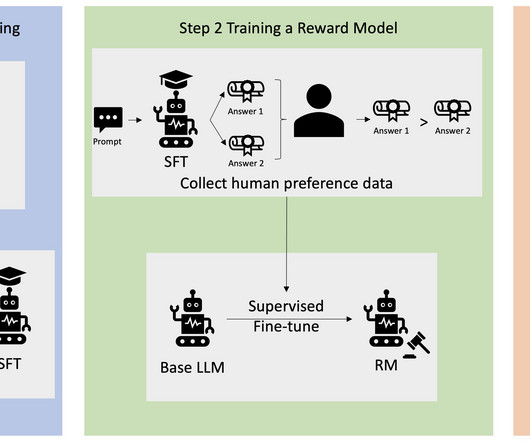
Continuous fine-tuning also enables models to integrate human feedback, address errors, and tailor to real-world applications. When you have user feedback to the model responses, you can also use reinforcement learning from human feedback (RLHF) to guide the LLMs response by rewarding the outputs that align with human preferences.
A new list of benchmarks is published each year by ACSI, with minor quarterly updates. . Below is the complete list of the newest CSAT benchmarks. Internet Search Engines and Information: 79%. Click here to download the current industry benchmarks. According to the ACSI, the current overall U.S. Airlines: 73%. Banks: 81%.
It consists of the following key components: Speech recognition The customers spoken language is captured and converted into text using Amazon Transcribe , which serves as the speech recognition engine. The transcript (text) is then fed into the machine translation engine. The customers translated speech is then streamed to the agent.
Curated judge models : Amazon Bedrock provides pre-selected, high-quality evaluation models with optimized prompt engineering for accurate assessments. Expert analysis : Data scientists or machine learning engineers analyze the generated reports to derive actionable insights and make informed decisions. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
Yes, you can collect their feedback on your brand offerings with simple questions like: Are you happy with our products or services? Various customer feedback tools help you track your customers’ pulse consistently. What Is a Customer Feedback Tool. Read more: 12 Channels to Capture Customer Feedback. Here we go!
It simplifies data integration from various sources and provides tools for data indexing, engines, agents, and application integrations. You also define a prompt template following Claude prompt engineering guidelines. Additionally, the column Feedback provides a clear explanation of the result of the passing score.
This requirement translates into time and effort investment of trained personnel, who could be support engineers or other technical staff, to review tens of thousands of support cases to arrive at an even distribution of 3,000 per category. Sonnet prediction accuracy through prompt engineering. We expect to release version 4.2.2
Customer benchmarking — the practice of identifying where a customer can improve or is already doing well by comparing to other customers – helps Customer Success Managers to deliver unique value to their customers. I’ve found that SaaS vendors use seven distinct strategies to empower CSMs with customer benchmarking.
In this post, we show how to incorporate human feedback on the incorrect reasoning chains for multi-hop reasoning to improve performance on these tasks. Solution overview With the onset of large language models, the field has seen tremendous progress on various natural language processing (NLP) benchmarks.
They don’t do anything else except maybe monitor a few calls and give some feedback. Agents can also send feedback directly to script authors to further improve processes. Feedback loops are imperative to success. If a QA person is responsible for delivering coaching/feedback, it can be time-consuming.
After testing available open source models, we felt that the out-of-the-box capabilities and responses were insufficient with prompt engineering alone to meet our needs. To initially evaluate the performance of this fine-tuned model, we crowd-sourced user feedback to iteratively create more samples.
This includes virtual assistants where users expect immediate feedback and near real-time interactions. The playground provides immediate feedback, helping you understand how the model responds to various inputs and letting you fine-tune your prompts for optimal results. For example, content for inference.
Figure 5 offers an overview on generative AI modalities and optimization strategies, including prompt engineering , Retrieval Augmented Generation , and fine-tuning or continued pre-training. Alternatively, you can create a specialized agent that monitors compliance with sustainability regulations in real time.
Acting as a model hub, JumpStart provided a large selection of foundation models and the team quickly ran their benchmarks on candidate models. Here, Amazon SageMaker Ground Truth allowed ML engineers to easily build the human-in-the-loop workflow (step v). Burak is still a research affiliate in MIT. With a background in visual design.
The team’s approach to customer feedback and improving customer experience are often cited by us as a beacon of best practice, but they’re actually going one step further. They are actively investing in their customer feedback programme in a strategic move to drive growth in the emerging Underfloor Heating market.
In addition, agents submit their feedback related to the machine-generated answers back to the Amazon Pharmacy development team, so that it can be used for future model improvements. Agents also label the machine-generated response with their feedback (for example, positive or negative). Burak is passionate about yoga and meditation.
Sentiment Analysis Sentiment analysis helps companies understand customer emotions by evaluating feedback across social media, reviews, and service logs. For instance, if sentiment data reveals dissatisfaction trends, companies can respond promptly, showing customers that their feedback matters.
Benchmarking and metrics – Defining standardized metrics and benchmarking to measure and compare the performance of AI models, and the business value derived. An example KPI is model accuracy: assessing models against benchmarks provides reliable and trustworthy AI-generated outcomes.
Customer impact, customer feedback Customers don’t always provide businesses with the gift of feedback. Engineers and technicians who would otherwise be doing some proactive work, end up fire-fighting. Reports allow you to benchmark the performance of your telecoms network. Agents might not escalate their own experiences.
This post is a joint collaboration between Salesforce and AWS and is being cross-published on both the Salesforce Engineering Blog and the AWS Machine Learning Blog. Their feedback helped develop the inference component feature, which now allows Salesforce and other SageMaker users to utilize GPU resources more effectively.
If customers are the fuel, employees are the engine, and together they drive the forward trajectory of any company. The benefits of collecting customer feedback. Collecting customer feedback provides the fodder for more effective marketing activities and elucidates operational imperfections that influence churn.
We’ll dive into reinforcement learning with human feedback, exploring how to use it skillfully and at scale to truly maximize your foundation model performance. As an added bonus, we’ll walk you through a Stable Diffusion deep dive, prompt engineering best practices, standing up LangChain, and more.
It will help you set benchmarks to get a clear picture of your performance with your customers. A Net Promoter Score (NPS) is a customer satisfaction benchmark that measures how likely your customers are to recommend you to a friend or colleague. Products & Engineering. Let’s start with the basics. They’re stable.
instruction tuned text-only models (8B, 70B, 405B) are optimized for multilingual dialogue use cases and outperform many of the publicly available chat models on common industry benchmarks. Engineering marvel**: When it was built for the 1889 World's Fair, the Eiffel Tower was a groundbreaking feat of engineering. The Llama 3.1
Tasks such as routing support tickets, recognizing customers intents from a chatbot conversation session, extracting key entities from contracts, invoices, and other type of documents, as well as analyzing customer feedback are examples of long-standing needs. We also examine the uplift from fine-tuning an LLM for a specific extractive task.
Reinforcement Learning from Human Feedback (RLHF) is recognized as the industry standard technique for ensuring large language models (LLMs) produce content that is truthful, harmless, and helpful. Gone are the days when you need unnatural prompt engineering to get base models, such as GPT-3, to solve your tasks.
Each GPC has a raster engine for graphics and several TPCs. The NeuronCores contain four engines : the first three include a ScalarEngine for scalar calculations, a VectorEngine for vector calculations, and a TensorEngine for matrix calculations. And finally, there is a C++ programmable GPSIMD-engine allowing for custom operations.
Built on AWS with asynchronous processing, the solution incorporates multiple quality assurance measures and is continually refined through a comprehensive feedback loop, all while maintaining stringent security and privacy standards. As new models become available on Amazon Bedrock, we have a structured evaluation process in place.
Polypipe Building Products, the UK’s leading manufacturer of plastic piping systems and low-carbon heating solutions for the residential market, has shared it has been investing in its customer feedback programme to drive growth in the emerging Underfloor Heating market.
If it has a search engine, which most do, focus on putting in the correct keywords to get the script or article that you need to solve the customer’s problem. Understanding Industry Benchmarks. Making the Most of Customer Feedback. Learn your agent information database. Learn how to get around it quickly.
This was the perfect place to start for our prototype—not only would Axfood gain a new AI/ML platform, but we would also get a chance to benchmark our ML capabilities and learn from leading AWS experts. Please leave any feedback or questions in the comments section.
Over the past three years more industries have recorded a dramatic decline in customer satisfaction than those who have improved, according to the Temkin Group’s 2017 Experience Ratings Report (a cross-industry open standard benchmark of customer experience). All hands support is just not the answer. Customer service isn’t valued.
Additionally, evaluation can identify potential biases, hallucinations, inconsistencies, or factual errors that may arise from the integration of external sources or from sub-optimal prompt engineering. In this case, the model choice needs to be revisited or further prompt engineering needs to be done.
This may be related to a complicated deployment such as enterprise software, or peer-to-peer, such as engineers from the supplier and customer companies meeting to work out usage details, or a customer appointee who interfaces with multiple locations of the supplier company in a single morning.
We’ve been working hard on creating a flexible engine that will allow us to create reports quickly so that our customers can get the important data they need to make crucial decisions in theie business. Country-by-country benchmarks on audio quality, connection rates and post-dial delay. UI REDESIGN. You asked, we listened.
With SageMaker MLOps tools, teams can easily train, test, troubleshoot, deploy, and govern ML models at scale to boost productivity of data scientists and ML engineers while maintaining model performance in production. Enable a data science team to manage a family of classic ML models for benchmarking statistics across multiple medical units.
The Kindle tablet actually came into existence because of a customer’s desires, not as a result of an engineer. Understanding Industry Benchmarks. Making the Most of Customer Feedback. A great example of a company who created a product from a customer’s suggestion is Amazon. They Can Teach You How to Better Serve Them.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Although existing large language model (LLM) benchmarks like MT-bench evaluate model capabilities, they lack the ability to validate the application layers. To further explore the best practices of building and testing conversational AI agent evaluation at scale, get started by trying Agent Evaluation and provide your feedback.
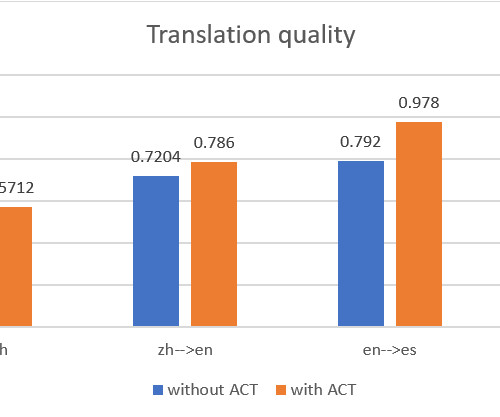
We used the BLEU (BiLingual Evaluation Understudy) score to benchmark the translation quality between the two methods. If you are interested in learning more about these benchmark analyses, refer to Auto Machine Translation and Synchronization for “Dive into Deep Learning”. Yunfei has a PhD in Electronic and Electrical Engineering.
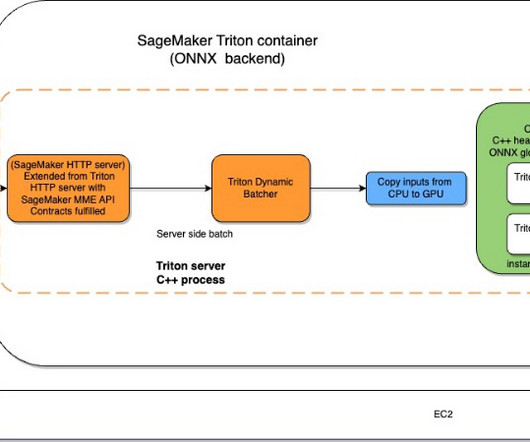
Furthermore, we benchmark the ResNet50 model and see the performance benefits that ONNX provides when compared to PyTorch and TensorRT versions of the same model, using the same input. The testing benchmark results are as follows: PyTorch – 176 milliseconds, cold start 6 seconds TensorRT – 174 milliseconds, cold start 4.5 seconds to 1.61
This is why it’s important to keep an eye on what people are saying about your business online and make sure that any negative feedback is addressed promptly and professionally. Good Reputation Benchmarks are Relative. Review benchmarks can be relative both to the industry and to the local community your businesses are in.
They went from being a company known for its excellent engineering and top-of-the-line products to being more flexible and considering more user experience aspects, like paying attention to which industry the buyer worked in, what they’d commonly be doing with the device, and even the budget they worked with.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content