This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics? Each provisioned node was r7g.4xlarge,
From essentials like average handle time to broader metrics such as call center service levels , there are dozens of metrics that call center leaders and QA teams must stay on top of, and they all provide visibility into some aspect of performance. Kaye Chapman @kayejchapman. First contact resolution (FCR) measures might be…”.
This approach allows organizations to assess their AI models effectiveness using pre-defined metrics, making sure that the technology aligns with their specific needs and objectives. Curated judge models : Amazon Bedrock provides pre-selected, high-quality evaluation models with optimized prompt engineering for accurate assessments.
Compound AI system and the DSPy framework With the rise of generative AI, scientists and engineers face a much more complex scenario to develop and maintain AI solutions, compared to classic predictive AI. DSPy supports iteratively optimizing all prompts involved against defined metrics for the end-to-end compound AI solution.
To effectively optimize AI applications for responsiveness, we need to understand the key metrics that define latency and how they impact user experience. These metrics differ between streaming and nonstreaming modes and understanding them is crucial for building responsive AI applications.
The challenge: Resolving application problems before they impact customers New Relic’s 2024 Observability Forecast highlights three key operational challenges: Tool and context switching – Engineers use multiple monitoring tools, support desks, and documentation systems. New Relic AI conducts a comprehensive analysis of the checkout service.
A new list of benchmarks is published each year by ACSI, with minor quarterly updates. . Below is the complete list of the newest CSAT benchmarks. Internet Search Engines and Information: 79%. Click here to download the current industry benchmarks. According to the ACSI, the current overall U.S. Airlines: 73%. Banks: 81%.
Current RAG pipelines frequently employ similarity-based metrics such as ROUGE , BLEU , and BERTScore to assess the quality of the generated responses, which is essential for refining and enhancing the models capabilities. More sophisticated metrics are needed to evaluate factual alignment and accuracy.
All text-to-image benchmarks are evaluated using Recall@5 ; text-to-text benchmarks are evaluated using NDCG@10. Text-to-text benchmark accuracy is based on BEIR, a dataset focused on out-of-domain retrievals (14 datasets). Generic text-to-image benchmark accuracy is based on Flickr and CoCo.
The Amazon EU Design and Construction (Amazon D&C) team is the engineering team designing and constructing Amazon warehouses. The Amazon D&C team implemented the solution in a pilot for Amazon engineers and collected user feedback. of overall responses) can be addressed by user education and prompt engineering.
This requirement translates into time and effort investment of trained personnel, who could be support engineers or other technical staff, to review tens of thousands of support cases to arrive at an even distribution of 3,000 per category. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
Metrics, Measure, and Monitor – Make sure your metrics and associated goals are clear and concise while aligning with efficiency and effectiveness. Make each metric public and ensure everyone knows why that metric is measured. Jeff Greenfield is the co-founder and chief operating officer of C3 Metrics.
To get the most return out of their pay-per-click (PPC) campaign, businesses should learn which metrics to focus on and exert the most of their efforts. Now, the question is—what are the metrics and figures to benchmark for every industry? CPC is a metric that measures the cost an advertiser pays to the publisher (e.g.,
As new embedding models are released with incremental quality improvements, organizations must weigh the potential benefits against the associated costs of upgrading, considering factors like computational resources, data reprocessing, integration efforts, and projected performance gains impacting business metrics.
Customer benchmarking — the practice of identifying where a customer can improve or is already doing well by comparing to other customers – helps Customer Success Managers to deliver unique value to their customers. I’ve found that SaaS vendors use seven distinct strategies to empower CSMs with customer benchmarking.
Additionally, evaluation can identify potential biases, hallucinations, inconsistencies, or factual errors that may arise from the integration of external sources or from sub-optimal prompt engineering. This makes it difficult to apply standard evaluation metrics like BERTScore ( Zhang et al.
Continuous education involves more than glancing at release announcements it includes testing beta features, benchmarking real world results, and actively sharing insights. Engineers versed in the OWASP Top 10 address common security weaknesses with minimal fuss. This method can save hours of coding time and avoid technical debt.
This post focuses on evaluating and interpreting metrics using FMEval for question answering in a generative AI application. FMEval is a comprehensive evaluation suite from Amazon SageMaker Clarify , providing standardized implementations of metrics to assess quality and responsibility. Question Answer Fact Who is Andrew R.
As a next step, you can explore fine-tuning your own LLM with Medusa heads on your own dataset and benchmark the results for your specific use case, using the provided GitHub repository. About the authors Daniel Zagyva is a Senior ML Engineer at AWS Professional Services.
They Leverage Their Data : The best performing contact centers leverage their operational and quality metrics in concert with their customer satisfaction scores and customer comments. They Avoid Benchmarking: High-performing contact center leaders do not waste a lot of time benchmarking their contact center performance.
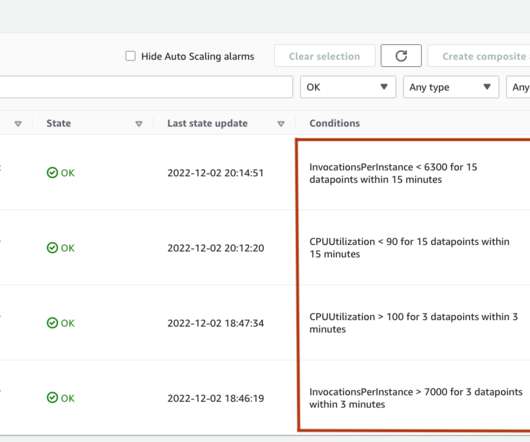
In this option, you select an ideal value of an Amazon CloudWatch metric of your choice, such as the average CPU utilization or throughput that you want to achieve as a target, and SageMaker will automatically scale in or scale out the number of instances to achieve the target metric. However, you can use any other benchmarking tool.
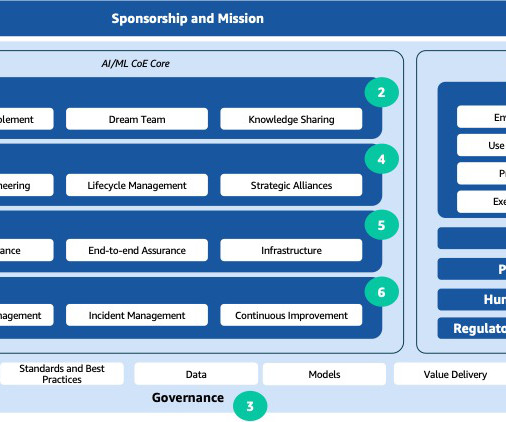
Benchmarking and metrics – Defining standardized metrics and benchmarking to measure and compare the performance of AI models, and the business value derived. Setting KPIs and metrics is pivotal to gauge effectiveness. Performance management Setting KPIs and metrics is pivotal to gauge effectiveness.
Model training benchmarks In large-scale training jobs where GPU communication is a significant bottleneck, SMDDP can markedly improve training speeds, as measured by model TFLOPS/GPU. Karan Dhiman is a Software Development Engineer at AWS, based in Toronto, Canada. 24xlarge nodes (512 NVIDIA A100 GPUs) PyTorch FSDP 97.89
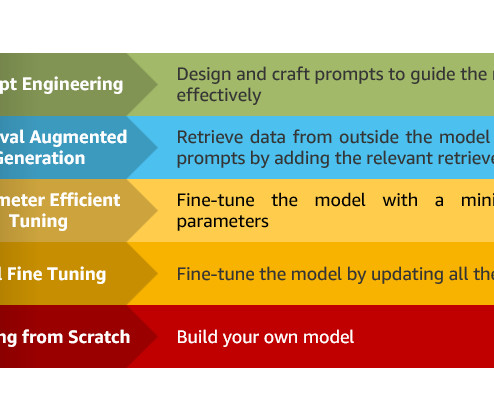
In particular, we provide practical best practices for different customization scenarios, including training models from scratch, fine-tuning with additional data using full or parameter-efficient techniques, Retrieval Augmented Generation (RAG), and prompt engineering.
Leave the session inspired to bring Amazon Q Apps to supercharge your teams’ productivity engines. Gain insights into training strategies, productivity metrics, and real-world use cases to empower your developers to harness the full potential of this game-changing technology.
In this part of the blog series, we review techniques of prompt engineering and Retrieval Augmented Generation (RAG) that can be employed to accomplish the task of clinical report summarization by using Amazon Bedrock. Prompt engineering helps to effectively design and improve prompts to get better results on different tasks with LLMs.
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category.
This post is a joint collaboration between Salesforce and AWS and is being cross-published on both the Salesforce Engineering Blog and the AWS Machine Learning Blog. To get started, see this guide. __ About the Authors Pawan Agarwal is the Senior Director of Software Engineering at Salesforce. Salesforce, Inc.
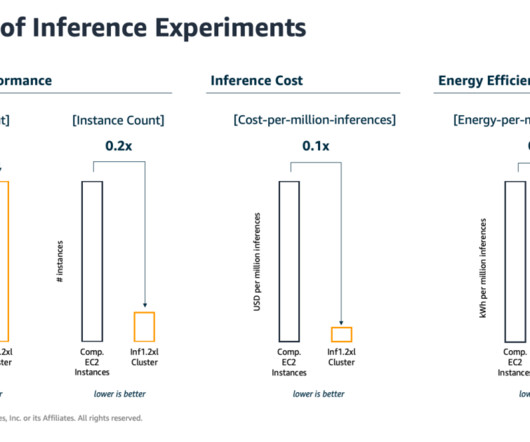
With G5 instances, ML customers get high performance and a cost-efficient infrastructure to train and deploy larger and more sophisticated models for natural language processing (NLP), computer vision (CV), and recommender engine use cases. Benchmarking approach. We also study the impact of full precision vs. mixed precision.
In addition, load testing can help guide the auto scaling strategies using the right metrics rather than iterative trial and error methods. For the context of load testing in this post, you can download our sample code from the GitHub repo to reproduce the results or use it as a template to benchmark your own models.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. The Carbontracker study estimates that training GPT-3 from scratch may emit up to 85 metric tons of CO2 equivalent, using clusters of specialized hardware accelerators.
Each machine learning (ML) system has a unique service level agreement (SLA) requirement with respect to latency, throughput, and cost metrics. An advanced job is a custom load test job that allows you to perform extensive benchmarks based on your ML application SLA requirements, such as latency, concurrency, and traffic pattern.
Chris Dishman Stop guessing, start growing: The customer success metrics that matter If you’re only tracking metrics like usage or churn, then you’re only seeing a small piece of the puzzle. When you track outcome-based metrics that help prove value to your customers, then you can proactively identify areas for growth and expansion.
The backbone of these advancements is ZOE, Zeta’s Optimization Engine. Together, these AI-driven tools and technologies aren’t just reshaping how brands perform marketing tasks; they’re setting new benchmarks for what’s possible in customer engagement. Saurabh Gupta is a Principal Engineer at Zeta Global.
The concepts illustrated in this post can be applied to applications that use PLM features, such as recommendation systems, sentiment analysis, and search engines. The performance of the architecture is typically measured using metrics such as validation loss. training.py ).
This post is co-written with Jad Chamoun, Director of Engineering at Forethought Technologies, Inc. and Salina Wu, Senior ML Engineer at Forethought Technologies, Inc. Forethought had to manage model inference on Amazon EKS ourselves, which was a burden on engineering efficiency. 2xlarge instances. seconds Large (550 tokens) 12.7
Each GPC has a raster engine for graphics and several TPCs. The NeuronCores contain four engines : the first three include a ScalarEngine for scalar calculations, a VectorEngine for vector calculations, and a TensorEngine for matrix calculations. And finally, there is a C++ programmable GPSIMD-engine allowing for custom operations.
An illuminated “check engine” light is scary because it doesn’t offer any solution. For many, “check engine” may as well just say “car broken”—and that’s terrifying. These categories are also represented numerically as a relative rating out of 100 based on a combination of established metric thresholds.
To showcase how this reduction can help you getting started with the creation of a custom entity recognizer, we ran some tests on a few open-source datasets and collected performance metrics. In this post, we walk you through the benchmarking process and the results we obtained while working on subsampled datasets. Dataset preparation.
As data and system conditions change, the model performance and efficiency metrics are tracked to ensure retraining is performed when needed. Your organization can choose the retraining mechanism—it can be quarterly, monthly, or based on science metrics, such as when accuracy drops below a given threshold.
Benchmarks We benchmarked evaluation metrics to ensure that the model quality didn’t deteriorate with the multi-GPU training path compared to single-GPU training. We also benchmarked on large datasets to ensure that our distributed GPU setups were performant and scalable. 8xlarge 15 1679 15.22 17 1509 15.51 19 1326 15.22
Figure 5 offers an overview on generative AI modalities and optimization strategies, including prompt engineering , Retrieval Augmented Generation , and fine-tuning or continued pre-training. Establish a metrics pipeline to provide insights into the sustainability contributions of your generative AI initiatives.
PrestoDB is an open source SQL query engine that is designed for fast analytic queries against data of any size from multiple sources. For more information on the TPC-H data, its database entities, relationships, and characteristics, refer to TPC Benchmark H. Twilio needed to implement an MLOps pipeline that queried data from PrestoDB.
It will help you set benchmarks to get a clear picture of your performance with your customers. A Net Promoter Score (NPS) is a customer satisfaction benchmark that measures how likely your customers are to recommend you to a friend or colleague. Keeping track of this metric can also help reduce support possibly needed in the future.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




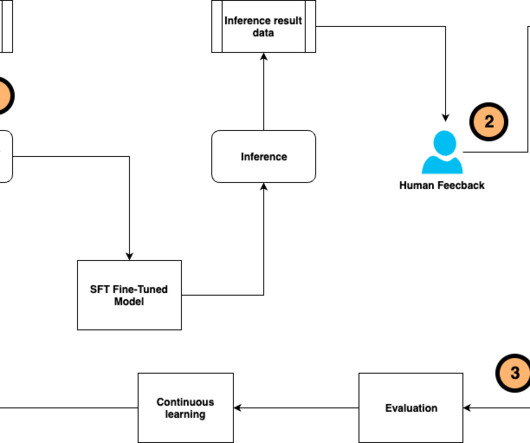





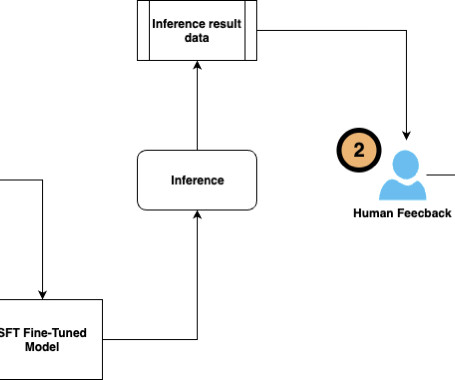





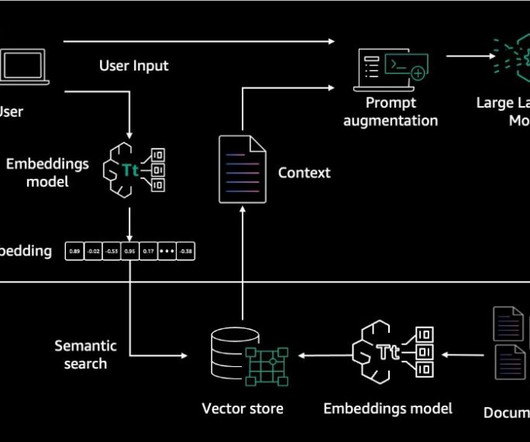


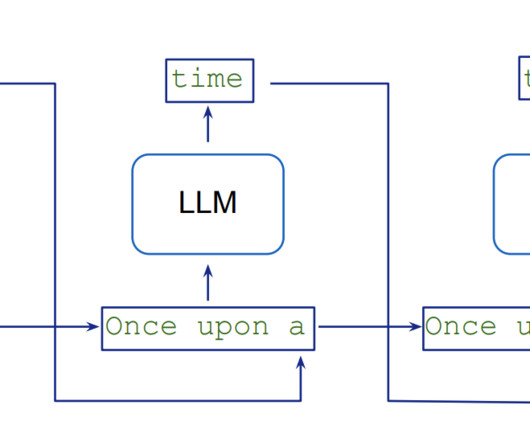


























Let's personalize your content