This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
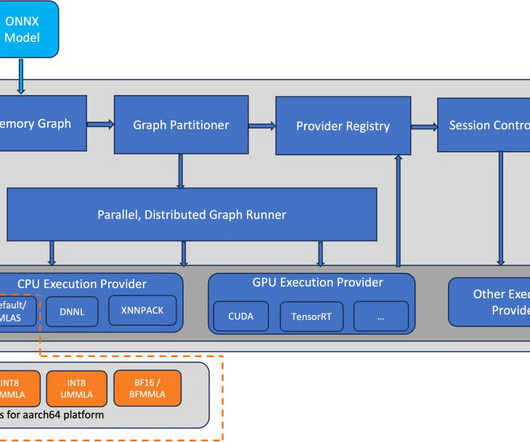
ONNX Runtime is the runtime engine used for model inference and training with ONNX. We also demonstrate the resulting speedup through benchmarking. Benchmark setup We used an AWS Graviton3-based c7g.4xl 1014-aws kernel) The ONNX Runtime repo provides inference benchmarkingscripts for transformers-based language models.
Bill Dettering is the CEO and Founder of Zingtree , a SaaS solution for building interactive decision trees and agent scripts for contact centers (and many other industries). Interactive agent scripts from Zingtree solve this problem. Agents can also send feedback directly to script authors to further improve processes.
We also included a data exploration script to analyze the length of input and output tokens. As a next step, you can explore fine-tuning your own LLM with Medusa heads on your own dataset and benchmark the results for your specific use case, using the provided GitHub repository.
Current evaluations from Anthropic suggest that the Claude 3 model family outperforms comparable models in math word problem solving (MATH) and multilingual math (MGSM) benchmarks, critical benchmarks used today for LLMs. Media organizations can generate image captions or video scripts automatically.
Performance in a contact center refers to how effectively agents manage calls, resolve issues, and meet established benchmarks. Agent Script Adherence: Monitoring and measuring how well agents follow provided scripts. HoduCC call and contact center software is engineered to enhance agents’ performance.
This requirement translates into time and effort investment of trained personnel, who could be support engineers or other technical staff, to review tens of thousands of support cases to arrive at an even distribution of 3,000 per category. Sonnet prediction accuracy through prompt engineering. We expect to release version 4.2.2
In this post, we dive deep into the new features with the latest release of LMI DLCs, discuss performance benchmarks, and outline the steps required to deploy LLMs with LMI DLCs to maximize performance and reduce costs. To use SmoothQuant, set option.quantize=smoothquan t with engine = DeepSpeed in serving.properties.
PrestoDB is an open source SQL query engine that is designed for fast analytic queries against data of any size from multiple sources. For more information on the TPC-H data, its database entities, relationships, and characteristics, refer to TPC Benchmark H. Twilio needed to implement an MLOps pipeline that queried data from PrestoDB.
We’ll cover fine-tuning your foundation models, evaluating recent techniques, and understanding how to run these with your scripts and models. As an added bonus, we’ll walk you through a Stable Diffusion deep dive, prompt engineering best practices, standing up LangChain, and more. More of a reader than a video consumer?
Machine learning (ML) experts, data scientists, engineers and enthusiasts have encountered this problem the world over. The team’s early benchmarking results show 7.3 The baseline model used in these benchmarking is a multi-layer perceptron neural network with seven dense fully connected layers and over 200 parameters.
Note that your model artifacts also include an inference script for preprocessing and postprocessing. If you don’t provide an inference script, the default inference handlers for the container you have chosen will be implemented. Gaurav Bhanderi is a Front End engineer with AI platforms team in SageMaker.
In this post, we show a high-level overview of how SMDDP works, how you can enable SMDDP in your Amazon SageMaker training scripts, and the performance improvements you can expect. About the Authors Apoorv Gupta is a Software Development Engineer at AWS, focused on building optimal deep learning systems for AWS infrastructure and hardware.
Welocalize benchmarks the performance of using LLMs and machine translations and recommends using LLMs as a post-editing tool. We use the custom terminology dictionary to compile frequently used terms within video transcription scripts. in Mechanical Engineering from the University of Notre Dame. Here’s an example.
We cover computer vision (CV), natural language processing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking. You can use the sample notebook to run the benchmarks and reproduce the results. Mohan Gandhi is a Senior Software Engineer at AWS.
The prospect of fine-tuning open source multimodal models like LLaVA are highly appealing because of their cost effectiveness, scalability, and impressive performance on multimodal benchmarks. It sets up a SageMaker training job to run the custom training script from LLaVA. For full parameter fine-tuning, ml.p4d.24xlarge
This was the perfect place to start for our prototype—not only would Axfood gain a new AI/ML platform, but we would also get a chance to benchmark our ML capabilities and learn from leading AWS experts. If discrepancies arise, a business logic within the postprocessing script assesses whether retraining the model is necessary.
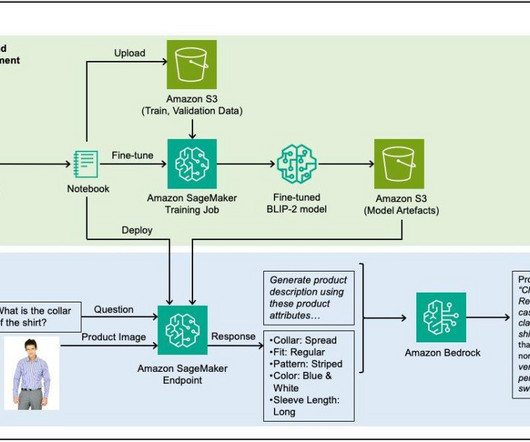
Customers can more easily locate products that have correct descriptions, because it allows the search engine to identify products that match not just the general category but also the specific attributes mentioned in the product description. The script also merges the LoRA weights into the model weights after training.
Code generation DBRX models demonstrate benchmarked strengths for coding tasks. user Write a Python script to read a CSV file containing stock prices and plot the closing prices over time using Matplotlib. The file should have columns named 'Date' and 'Close' for this script to work correctly.
Typically, HyperPod clusters are used by multiple users: machine learning (ML) researchers, software engineers, data scientists, and cluster administrators. To achieve this multi-user environment, you can take advantage of Linux’s user and group mechanism and statically create multiple users on each instance through lifecycle scripts.
Prompt engineering Prompt engineering refers to efforts to extract accurate, consistent, and fair outputs from large models, such text-to-image synthesizers or large language models. For more information, refer to EMNLP: Prompt engineering is the new feature engineering.
Data scientists and machine learning engineers are constantly looking for the best way to optimize their training compute, yet are struggling with the communication overhead that can increase along with the overall cluster size. To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script.
SageMaker LMI containers provide two ways to deploy the model: A no-code option where we just provide a serving.properties file with the required configurations Bring your own inference script We look at both solutions and go over the configurations and the inference script ( model.py ). The container requires your model.py
Finally, we’ll benchmark performance of 13B, 50B, and 100B parameter auto-regressive models and wrap up with future work. A ready-to-use training script for GPT-2 model can be found at train_gpt_simple.py. You can find an example in the same training script train_gpt_simple.py. Benchmarking performance. 24xlarge nodes.
In this post, we outline the key benefits and pain points addressed by SageMaker Training Managed Warm Pools, as well as benchmarks and best practices. Benchmarks. We performed benchmarking tests to measure job startup latency using a 1.34 Overview of SageMaker Training Managed Warm Pools. When should you use warm pools?
Touchpoints may involve any medium you use to interact with customers, including: Search engine marketing. This may occur through encountering your brand or product through a search engine result, a search engine ad, a social media post, a video, a review on a technology website, word-of-mouth or other means. Blog content.
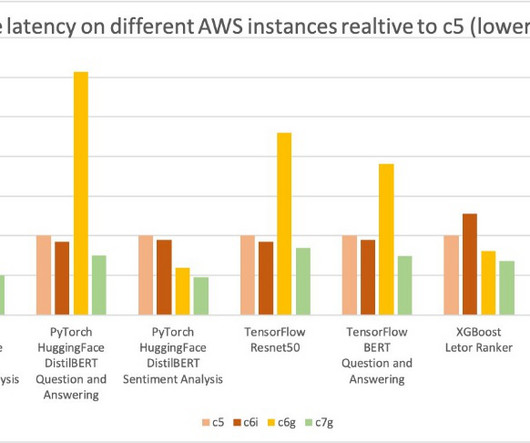
Refer to the appendix for instance details and benchmark data. Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions. Benchmark data The following table compares the cost and relative performance between c5 and c6 instances.
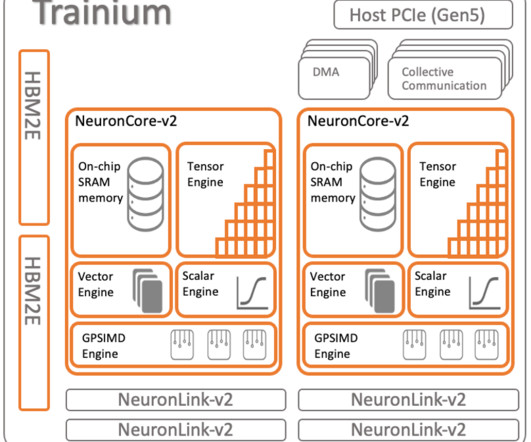
Trainium support for custom operators Trainium (and AWS Inferentia2) supports CustomOps in software through the Neuron SDK and accelerates them in hardware using the GPSIMD engine (General Purpose Single Instruction Multiple Data engine). The scalar and vector engines are highly parallelized and optimized for floating-point operations.
We provide an overview of key generative AI approaches, including prompt engineering, Retrieval Augmented Generation (RAG), and model customization. Building large language models (LLMs) from scratch or customizing pre-trained models requires substantial compute resources, expert data scientists, and months of engineering work.
AlexaTM 20B has shown competitive performance on common natural language processing (NLP) benchmarks and tasks, such as machine translation, data generation and summarization. To use a large language model in SageMaker, you need an inferencing script specific for the model, which includes steps like model loading, parallelization and more.
The concepts illustrated in this post can be applied to applications that use PLM features, such as recommendation systems, sentiment analysis, and search engines. We use the Recognizing Textual Entailment dataset from the GLUE benchmarking suite. He specializes in Generative AI and Machine Learning Data Engineering.
Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training. AI Engineering, Mobileye. Performance benchmark results. You can build logic in your training script to assign the instance groups to certain training and data processing tasks.
. * The `if __name__ == "__main__"` block checks if the script is being run directly or imported. To run the script, you can use the following command: ``` python hello.py ``` * The output will be printed in the console: ``` Hello, world! Evaluate model on test set, compare to benchmarks, analyze errors and biases.
Briefly, this is made possible by an installation script specified by CustomActions in the YAML file used for creating the ParallelCluster (see Create ParallelCluster ). You can invoke neuron-top during the training script run to inspect NeuronCore utilization at each node. Jeffrey Huynh is a Principal Engineer in AWS Annapurna Labs.
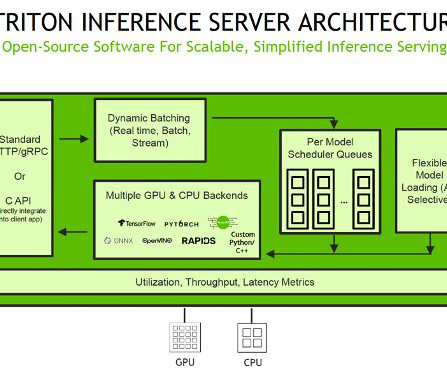
To serve models, Triton supports various backends as engines to support the running and serving of various ML models for inference. With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization. Import the ONNX model into TensorRT and generate the TensorRT engine.
Online customers in the pre-purchase stage typically find companies in one of two ways: on social media or through a search engine. Recommended for you: 8 Proactive Chat Best Practices with Ready-to-Use Scripts. Comm100’s 2020 Live Chat Benchmark Report found that 74.5 Ask us about our free shipping codes!”).
DL scripts often require boilerplate code, notably the aforementioned double for loop structure that splits the dataset into minibatches and the training into epochs. At the time of this writing, it supports PyTorch and includes 25 techniques—called methods in the MosaicML world—along with standard models, datasets, and benchmarks.
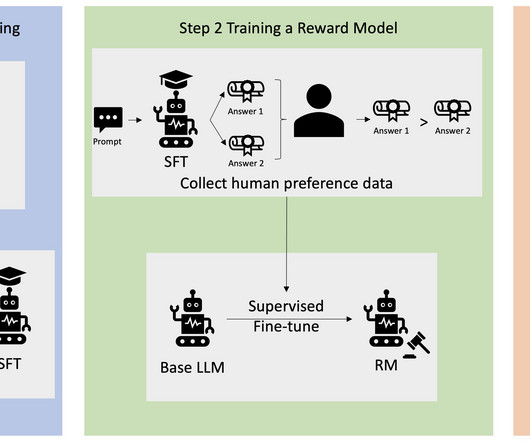
Gone are the days when you need unnatural prompt engineering to get base models, such as GPT-3, to solve your tasks. The script initiates the SFT model using its current weights and then optimizes them under the guidance of a reward model, so that the resulting RLHF trained model aligns with human preference. yaml ppo_hh.py
The following figure shows a performance benchmark of fine-tuning a RoBERTa model on Amazon EC2 p4d.24xlarge inference with AWS Graviton processors for details on AWS Graviton-based instance inference performance benchmarks for PyTorch 2.0. Run your DLC container with a model training script to fine-tune the RoBERTa model.
In this post, we walk you through the benchmarking process and the results we obtained while working on subsampled datasets. Sampling configuration and benchmarking process. This was done by using a custom script designed to create subsampled datasets in which each entity type appears at least k times, within a minimum of n documents.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Wei-Chih Chen is a Machine Learning Engineer at the AWS Generative AI Innovation Center, where he works on model customization and optimization for LLMs. We convert the samples into the format required by the customization job using the to_customization_format function and save them as train.jsonl.
For benchmark analysis, we considered the task of predicting the in-hospital mortality of patients [2]. You can place the data in any folder of your choice, as long as the path is consistently referenced in the training script and has access enabled. Import the data loader into the training script. and data_loader.py
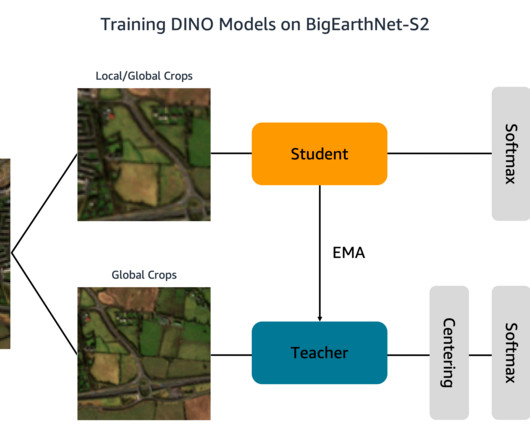
Prepare the BigEarthNet-S2 dataset BigEarthNet-S2 is a benchmark archive that contains 590,325 multispectral images collected by the Sentinel-2 satellite. To train the classifier, we create a SageMaker PyTorch Estimator that runs the training script, eval_linear.py. file: init_distributed_mode function in the util.py
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content