This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These models offer enterprises a range of capabilities, balancing accuracy, speed, and cost-efficiency. Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset.
This model is the newest Cohere Embed 3 model, which is now multimodal and capable of generating embeddings from both text and images, enabling enterprises to unlock real value from their vast amounts of data that exist in image form. This enables enterprises to unlock real value from their vast amounts of data that exist in image form.
Sonnet currently ranks at the top of S&P AI Benchmarks by Kensho , which assesses large language models (LLMs) for finance and business. For example, there could be leakage of benchmark datasets’ questions and answers into training data. Anthropic Claude 3.5 Kensho is the AI Innovation Hub for S&P Global. Anthropic Claude 3.5
1 To stay competitive and ensure long-term business success, enterprises must quickly adapt and continue to invest in customer experience (CX) initiatives. These solutions are setting new benchmarks for customer satisfaction by empowering organizations to solve more issues faster at a lower cost.
This week we feature an article by Shaista Haque who writes about the top technology trends of 2017 that she believes will disrupt customer experience benchmarks. Armed with this information, she writes about latest industry technologies and how it benefits organizations from small scale to global enterprises. Shep Hyken.
In our webinar, 2022 SaaS retention benchmarks , SaaS Capital Manager Director Rob Belcher shares the results from their 11th annual B2B SaaS benchmarking survey. You can download the full report for net retention and gross retention benchmarks as well as retention metrics in relation to ACV, growth, size, and more.
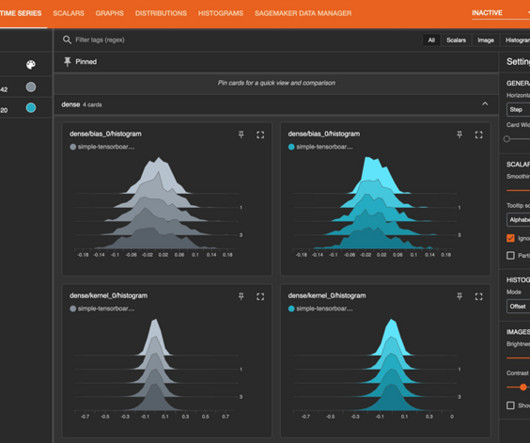
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
Developing and maintaining a successful enterprise in today’s demanding business landscape is no easy task. Whether you’re a small business or large-scale enterprise, maintaining database accuracy is essential for companies to optimize their operational performance and adequately represent their revenue and profitability.
This integration provides a powerful multilingual model that excels in reasoning benchmarks. The integration offers enterprise-grade features including model evaluation metrics, fine-tuning and customization capabilities, and collaboration tools, all while giving customers full control of their deployment.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
This unified view enables everyone supporting your enterprise software to understand and act on insights about application health and performance. The result is a more collaborative approach across multiple enterprise teams, leading to more reliable system maintenance and excellent customer experiences.
SaaS Capital joined us for a webinar to share the results from their 10th annual B2B SaaS benchmarking survey. Is the bar across the same for a SMB-focused company versus an enterprise-focused company? There are investors that focus on SMB, and there are others that focus solely on enterprise. Rarely are folks doing both.
Lowenstein says that to establish a culture, it has to flow throughout the enterprise, to permeate the DNA of the organization. If you want to benchmark your organization’s performance in the new world of behavioral economics against other companies, take our short questionnaire. Include the whole organization in the effort.
To help determine whether a serverless endpoint is the right deployment option from a cost and performance perspective, we have developed the SageMaker Serverless Inference Benchmarking Toolkit , which tests different endpoint configurations and compares the most optimal one against a comparable real-time hosting instance.
This blog post delves into how these innovative tools synergize to elevate the performance of your AI applications, ensuring they not only meet but exceed the exacting standards of enterprise-level deployments. By adopting this holistic evaluation approach, enterprises can fully harness the transformative power of generative AI applications.
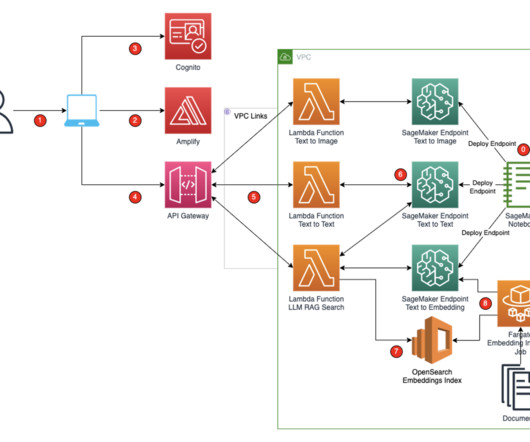
In this post, we build a secure enterprise application using AWS Amplify that invokes an Amazon SageMaker JumpStart foundation model, Amazon SageMaker endpoints, and Amazon OpenSearch Service to explain how to create text-to-text or text-to-image and Retrieval Augmented Generation (RAG). You access the React application from your computer.
They provide customized reporting and analysis, survey deployment via email, SMS, and phone, and national benchmarking to compare against competitors. Drive Research Drive Research works with major brands like Google, Apple, and Amazon to provide enterprise-level customer insights and market research.
As enterprise businesses embrace machine learning (ML) across their organizations, manual workflows for building, training, and deploying ML models tend to become bottlenecks to innovation. Building an MLOps foundation that can cover the operations, people, and technology needs of enterprise customers is challenging. About the Author.
Continuous education involves more than glancing at release announcements it includes testing beta features, benchmarking real world results, and actively sharing insights. Both enterprises and java coder professionals gain long-term rewards when they focus on ongoing improvement.
a low-code enterprise graph machine learning (ML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. Enterprise graphs can require terabytes of memory storage, requiring graph ML scientists to build complex training pipelines. GraphStorm 0.1
According to a survey from PwC, nearly half (48%) of U.S. consumers define good customer service as friendly and welcoming. Meanwhile, an overwhelming majority (82%) of the top-performing companies report paying “close attention” to customer experience.
Daniel Seaborne, Managing Director for UK & South Africa at Sabio Group said , “Our London event has set the benchmark for CX excellence since 2017. ” Gabriel Rodriguez, Managing Director for Sabio Spain, added : “Spanish enterprises are embracing digital transformation at remarkable speed.
What does it mean to be a Connected Enterprise and does it really matter? Today, the key to success lies in becoming a Connected Enterprise where all parts of the organisation work together to deliver exceptional customer experiences. Calabrio’s new blog series explores the rise of the Connected Enterprise.
And it strikes the ideal balance between intelligence and speed – qualities especially critical for enterprise use cases. Current evaluations from Anthropic suggest that the Claude 3 model family outperforms comparable models in math word problem solving (MATH) and multilingual math (MGSM) benchmarks, critical benchmarks used today for LLMs.
A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard. The Massive Text Embedding Benchmark (MTEB) evaluates text embedding models across a wide range of tasks and datasets.
By using the same evaluator model across all comparisons, youll get consistent benchmarking results to help identify the optimal model for your use case. The following best practices will help you establish standardized benchmarking when comparing different foundation models. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
Through the Tethr platform and its hundreds of out-of-box packaged insight categories, we’ve eliminated much of the work needed to make listening to the voice of the customer across the enterprise successful and deliver meaningful, positive business outcomes in a fraction of the time it takes with other products. The post J.D.
a leading global CX (customer experience) technology and services innovator for AI-enabled CX with solutions from TTEC Engage and TTEC Digital , announced today that TTEC Digital has been recognized as a Major Contender in the 2024 Everest Group PEAK Matrix ® Assessment for Digital Transformation Services for Mid-market Enterprises.
GraphStorm is a low-code enterprise graph machine learning (GML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. Comprehensive study of LM+GNN for large graphs with rich text features Many enterprise applications have graphs with text features. Dataset Num.
A set of key performance indicators and benchmarks to track and measure client progress towards goals. To measure your customers’ progress towards their objectives, goals should be defined in terms of measurable key performance indicators and benchmarks.
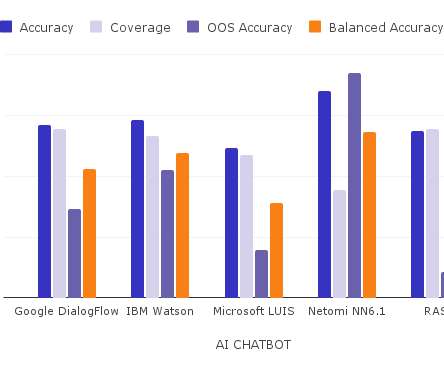
NLU Benchmarking Report: The Process . We assessed the ability of an AI to correctly answer use cases for businesses of all sizes (small to enterprise). Download your copy of the NLU Benchmarking Report now for the full results. NLU Benchmarking Report: The Results . Here are the highlights of the report: .
These include metrics such as ROUGE or cosine similarity for text similarity, and specific benchmarks for assessing toxicity (Detoxify), prompt stereotyping (cross-entropy loss), or factual knowledge (HELM, LAMA). You are a Support Agent and an expert on the enterprise application software. Customer: "Thank you for clarifying.
These five common revenue leaks, many of which are related to those top concerns, are directly impacted by enterprise-wide communication practices. As CEOs and companies prepare to tackle some of the top concerns for this year, only the most successful will prioritize communication as part of their plans. Employee – mission disconnect.
In our webinar, 2022 SaaS retention benchmarks , SaaS Capital Manager Director Rob Belcher shares the results from their 11th annual B2B SaaS benchmarking survey. You can download the full report for net retention and gross retention benchmarks as well as retention metrics in relation to ACV, growth, size, and more.
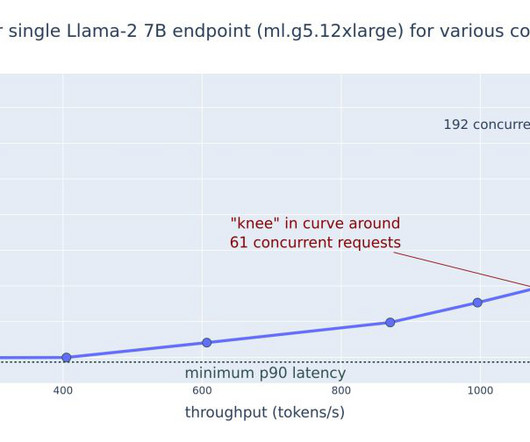
SageMaker AI provides enterprise-grade security features to help keep your data and applications secure and private. Tokens We evaluated SageMaker endpoint hosted DeepSeek-R1 distilled variants on performance benchmarks using two sample input token lengths. Then we repeated the test with concurrency 10. 2xlarge , and ml.g6e.12xlarge
Customers using SageMaker HyperPod Leading startups like Writer, Luma AI, and Perplexity, as well as major enterprises such as Thomson Reuters and Salesforce, are accelerating model development with SageMaker HyperPod.
Many brands have set a trend in terms of customer support and become the benchmark. Beyond that, in Level 4, we will start to interact with Assistants that can effortlessly include information about us from disparate enterprise systems in the organization. So can you recommend a new strategy that helps newbies get a competitive edge?
The best of both worlds: unmatched enterprise-grade implementation and usability The G2 Winter 2024 reports ranked Totango as the number one customer success software in the enterprise implementation index. This recognition shines a spotlight on our commitment to offering an easy and efficient implementation process.
As you aim to bring your proofs of concept to production at an enterprise scale, you may experience challenges aligning with the strict security compliance requirements of their organization. Optionally, you can commit to third-party version control systems such as GitHub, GitLab, or Enterprise Git.
The technical sessions covering generative AI are divided into six areas: First, we’ll spotlight Amazon Q , the generative AI-powered assistant transforming software development and enterprise data utilization. Learn how Toyota utilizes analytics to detect emerging themes and unlock insights used by leaders across the enterprise.
While there may be pressure to cut costs, there is little evidence of outsourcing at an enterprise level. At this stage, the organization executives have either assessed the success of a pilot outsourcing program and have decided to proactively pursue it at an enterprise level or external pressures have forced the organization to act.
Neuron7’s Agentic AI sets a new benchmark by going beyond case deflection. The Business Impact of Resolution Pathways Leading global enterprises, including Daktronics, KARL STORZ, Keysight Technologies, and Terumo BCT, have already embraced Neuron7s innovative solution.
Call Center Industry Turnover Rate Benchmarks Call center turnover rates are notoriously high compared to other industries. Depending on the type of work performed, typical benchmarks range from as low as 15% to 45%, or even higher. And employee churn among new hires can be especially high. Contact center industry averages vary.
BURLINGTON, MASSACHUSETTS, UNITED STATES, April 17, 2024 / EINPresswire.com / — Zappix and GTS have launched their advanced Customer Engagement Solutions and Call Center Operational Enhancements for North American enterprises and government clients, marking a significant step forward in customer service and operational efficiency.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content