This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. The following table provides example questions with their domain and question type.
Call on experienced managers for guidance in setting up benchmarks. “Experienced call center managers are helpful in setting up the initial performance benchmarks for a new outbound call center program. These benchmarks are, at first, estimated based on the past performance of similar outbound call center projects.
This sets a new benchmark for state-of-the-art performance in critical medical diagnostic tasks, from identifying cancerous cells to detecting genetic abnormalities in tumors. Through practical examples, we show you how to adapt this FM to these specific use cases while optimizing computational resources.
Chat scripts are a handy tool, especially for chat agents who find themselves often responding to related customer inquiries. Chat scripts, or canned responses, help companies ensure quality control, implement precise language for optimal results, and increase customer happiness. Not all companies implement chat scripts with success.
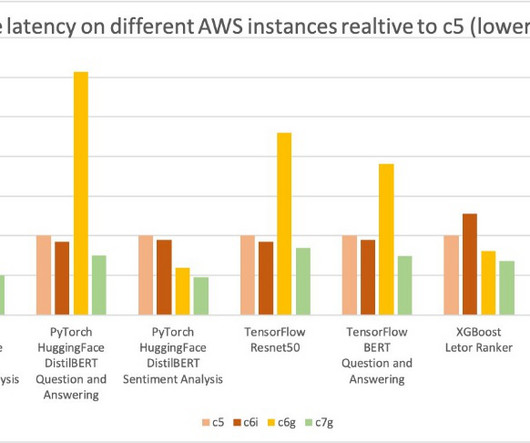
You can see that for the 45 models we benchmarked, there is a 1.35x latency improvement (geomean for the 45 models). You can see that for the 33 models we benchmarked, there is around 2x performance improvement (geomean for the 33 models). We benchmarked 45 models using the scripts from the TorchBench repo.
Example: Campaign A has a high call volume but campaign B has less calls and the agents that are assigned campaign B are not busy. Bill Dettering is the CEO and Founder of Zingtree , a SaaS solution for building interactive decision trees and agent scripts for contact centers (and many other industries). Bill Dettering.
For example, when tested on the MT-Bench dataset , the paper reports that Medusa-2 (the second version of Medusa) speeds up inference time by 2.8 For example, you can still use an ml.g5.4xlarge instance with 24 GB of GPU memory to host your 7-billion-parameter Llama or Mistral model with extra Medusa heads. times on the same dataset.
” He gives the example of Apple’s products, which are noted for their beautiful design, functionalities, and aesthetics. Performance in a contact center refers to how effectively agents manage calls, resolve issues, and meet established benchmarks. Drexler said, “I’m looking for best practices constantly.”
That’s where a customer service script comes into play. Call handling scripts outline the customer’s journey and prompt the person representing your company to create a memorable and consistent interaction with a client, customer or business associate. One simple example, “Thank you for calling (name of company).
In our example, the organization is willing to approve a model for deployment if it passes their checks for model quality, bias, and feature importance prior to deployment. For this example, we provide a centralized model. You can create and run the pipeline by following the example provided in the following GitHub repository.
We also showcase a real-world example for predicting the root cause category for support cases. For the use case of labeling the support root cause categories, its often harder to source examples for categories such as Software Defect, Feature Request, and Documentation Improvement for labeling than it is for Customer Education.
The prospect of fine-tuning open source multimodal models like LLaVA are highly appealing because of their cost effectiveness, scalability, and impressive performance on multimodal benchmarks. For example, instead of simply asking the model to describe the image, ask specific questions about the image and relating to its content.
When you select the option to use the SDK, you will see example code that you can use in the notebook editor of your choice in SageMaker Studio. In this section, we provide some example prompts and sample output. Code generation DBRX models demonstrate benchmarked strengths for coding tasks.
For example, if a customer is waiting in line to speak with an agent for 30 minutes, that number isnt figured into the final AHT. Setting an Average Handle Time Benchmark: What is a Good AHT? For example, a caller may be asked On a scale of one to ten, how likely are you to recommend to a friend?
For example, for PyTorch this would be a model.pth. Note that your model artifacts also include an inference script for preprocessing and postprocessing. If you don’t provide an inference script, the default inference handlers for the container you have chosen will be implemented.
It would also be helpful to give new hires information on which KPIs managers will assess, how these are tied to performance evaluations, and practical tips on how to hit their KPI benchmarks. Allow them to listen to recordings and also provide online scripts. Choose recordings that will help you demonstrate a specific point (i.e.,
The following code shows an example of how a query is configured within the config.yml file. For more information on the TPC-H data, its database entities, relationships, and characteristics, refer to TPC Benchmark H. The sklearn_processor is used in the ProcessingStep to run the scikit-learn script that preprocesses data.
For example, a B2C customer might prioritize user experience, while a B2B client might emphasize return on investment. SaaS success outcomes can be defined in terms of measurable digital benchmarks. For example, a customer who is slow to complete the onboarding process can be sent an email prompt with a link to tutorial tips.
We have seen a similar trend in the price-performance advantage for other workloads on Graviton, for example video encoding with FFmpeg. wheels and set the previously mentioned environment variables # Clone PyTorch benchmark repo git clone [link] # Setup Resnet50 benchmark cd benchmark python3 install.py
You will also find a Deploy button, which takes you to a landing page where you can test inference with an example payload. Deploy Gemma with SageMaker Python SDK You can find the code showing the deployment of Gemma on JumpStart and an example of how to use the deployed model in this GitHub notebook. This looks pretty good!
For example, establishing expected follow-up time and communications format when an IT department responds to a technical support call. In such cases, standards provide a useful benchmark, especially for new employees learning how to do the job. Consider this example. Standards can also support your brand.
If youre running this code using an Amazon SageMaker notebook instance, edit the IAM role thats attached to the notebook (for example, AmazonSageMaker-ExecutionRole-XXX) instead of creating a new role. The following table shows an example. preference) and the fine-tuned model with original 500 examples (76.4% preference).
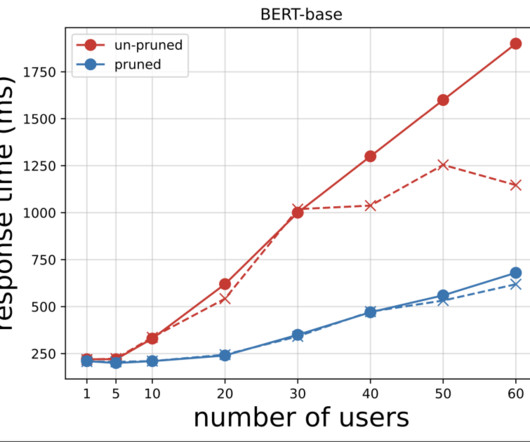
In the following example figure, we show INT8 inference performance in C6i for a BERT-base model. Refer to the appendix for instance details and benchmark data. Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions.
Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training. Performance benchmark results. For example, consider a powerful GPU instance type, ml.p4d.24xlarge For example, if you’re training the model on ml.trn1.32xlarge, ml.p4d.24xlarge,
The team’s early benchmarking results show 7.3 The baseline model used in these benchmarking is a multi-layer perceptron neural network with seven dense fully connected layers and over 200 parameters. The following table summarizes the benchmarking result on ml.p3.16xlarge SageMaker training instances. Number of Instances.
For example, a product that has a description that includes words such as “long sleeve” and “cotton neck” will be returned if a consumer is looking for a “long sleeve cotton shirt.” To fine-tune our model, we need to convert our structured examples into a collection of question and answer pairs. We prepared entrypoint_vqa_finetuning.py
The Neuron SDK is the software stack that provides the driver, compiler, runtime, framework integration (for example, PyTorch Neuron), and user tools that allow you to access the benefits of the Trainium accelerators. For example: apiVersion: eksctl.io/v1alpha5 An ECR repository is used to store the training container images.
We have examples available for Stable Diffusion 2.1 This notebook presents an end-to-end example of how to compile a Stable Diffusion model, save the compiled Neuron models, and load it into the runtime for inference. The emb tensor is used as example input for the torch_neuronx.trace function. model on the GitHub repo.
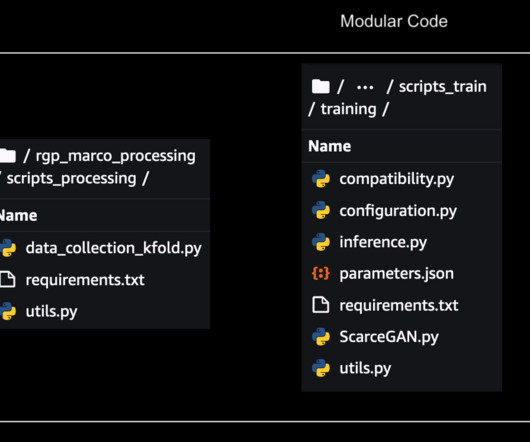
We’ll cover fine-tuning your foundation models, evaluating recent techniques, and understanding how to run these with your scripts and models. All of the example notebooks and supporting code will ship in a public repository, which you can use to step through on your own. Want to jump right into the code?
The code to invoke the pipeline script is available in the Studio notebooks, and we can change the hyperparameters and input/output when invoking the pipeline. This is quite different from our earlier method where we had all the parameters hard coded within the scripts and all the processes were inextricably linked.
In this post, we use a Hugging Face BERT-Large model pre-training workload as a simple example to explain how to useTrn1 UltraClusters. The following diagram shows an example. You can invoke neuron-top during the training script run to inspect NeuronCore utilization at each node. Complete instructions can be found on GitHub.
We cover computer vision (CV), natural language processing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking. You can use the sample notebook to run the benchmarks and reproduce the results. Create an endpoint configuration.
We first benchmark the performance of our model on a single instance to identify the TPS it can handle per our acceptable latency requirements. The entire set of code for the example is available in the following GitHub repository. Overview of solution. For CPUUtilization , you may see percentages above 100% at first in CloudWatch.
It can be applied even when there are only a few available training examples, or even none at all. AlexaTM 20B has shown competitive performance on common natural language processing (NLP) benchmarks and tasks, such as machine translation, data generation and summarization. This is known as in-context learning.
In this post, we show a high-level overview of how SMDDP works, how you can enable SMDDP in your Amazon SageMaker training scripts, and the performance improvements you can expect. You can find more SMDDP examples with sharded data parallel training in the Amazon SageMaker Examples GitHub repository.
Read Email Response Times: Benchmarks and Tips for Support for practical advice. It was the bots that seemed to offer help but failed to deliver it, like this Flowxo example: Be the best bot you can be: Look for alternatives to chat bots that will still meet your customer service goals. You’ll spot the rough edges more easily.
For example, 8 V100 GPUs (32GB each) are sufficient to hold the model states replica of a 10B-parameter model which needs about 200GB of memory when training with Adam optimizer using mixed-precision. To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script. Benchmarking performance.
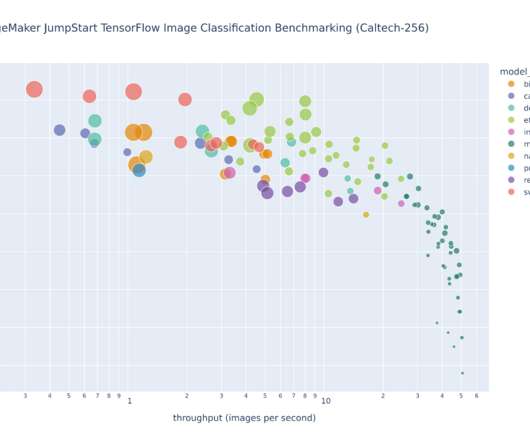
The former question addresses model selection across model architectures, while the latter question concerns benchmarking trained models against a test dataset. This post provides details on how to implement large-scale Amazon SageMaker benchmarking and model selection tasks. swin-large-patch4-window7-224 195.4M efficientnet-b5 29.0M
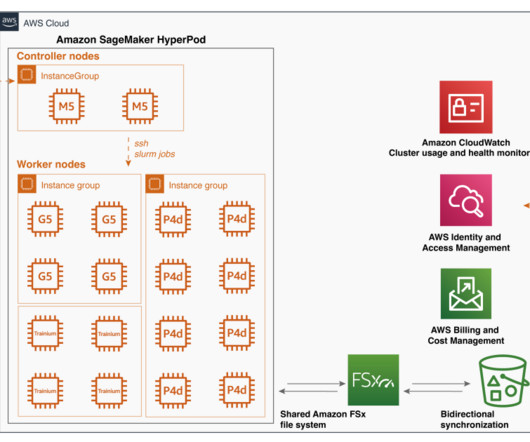
Furthermore, as clusters scale to larger sizes (for example, more than 32 nodes), they require built-in resiliency mechanisms such as automated faulty node detection and replacement to improve cluster goodput and maintain efficient operations. For example, when working with a smaller backbone model like Stable Diffusion 1.5,
For a university or college, for example, intents might include: . For example, a student wishing to pay fees might say “I’d like to pay my bill” or ask, “how can I pay my tuition online?” Over time, your chatbot will learn to correctly identify new examples of each intent outside of the original programming.
To achieve this multi-user environment, you can take advantage of Linux’s user and group mechanism and statically create multiple users on each instance through lifecycle scripts. For Directory DNS name , enter your preferred directory DNS name (for example, hyperpod.abc123.com For Directory type , select AWS Managed Microsoft AD.
One example is an online retailer who deploys a large number of inference endpoints for text summarization, product catalog classification, and product feedback sentiment classification. We use the Recognizing Textual Entailment dataset from the GLUE benchmarking suite. Choose System terminal under Utilities and files. training.py ).
See the example below. Flip the script on your results and use that as a motivator. After inbound sales calls, for example, prospects can share how satisfied they were with the conversation. For example, a journey map may identify customers feel their invoices are too long and hard to understand. Ways to use CSAT .
The following figure shows a performance benchmark of fine-tuning a RoBERTa model on Amazon EC2 p4d.24xlarge inference with AWS Graviton processors for details on AWS Graviton-based instance inference performance benchmarks for PyTorch 2.0. Run your DLC container with a model training script to fine-tune the RoBERTa model.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content