

Benchmarking Amazon Nova and GPT-4o models with FloTorch
AWS Machine Learning
MARCH 11, 2025
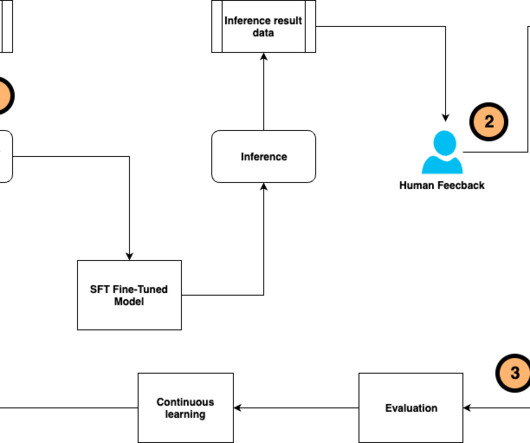
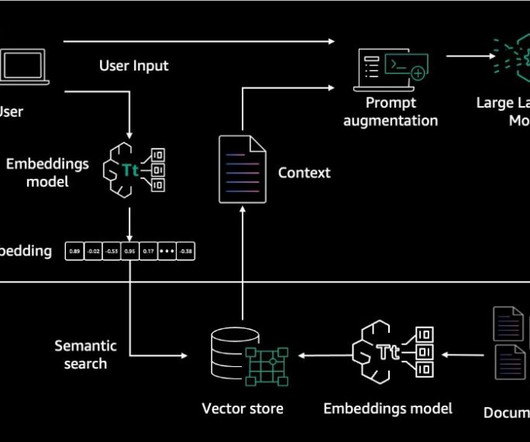
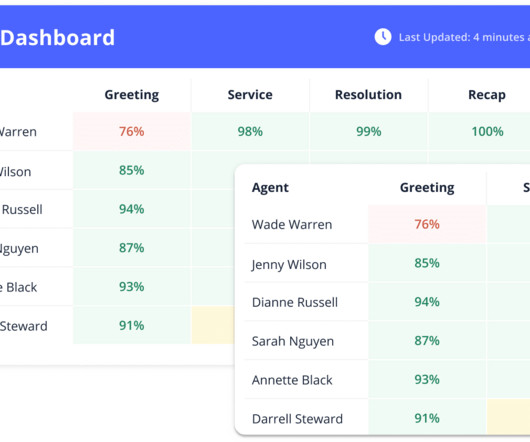
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics?












































Let's personalize your content