This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At the heart of most technological optimizations implemented within a successful call center are fine-tuned metrics. Keeping tabs on the right metrics can make consistent improvement notably simpler over the long term. However, not all metrics make sense for a growing call center to monitor. Peak Hour Traffic.
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics? Each provisioned node was r7g.4xlarge,
Depending on your call center’s primary functions, certain metrics may prove meaningless and unusable in a practical sense, while others can be pivotal in assessing performance and improving over time. Following are a few metrics that matter for inbound call centers: Abandoned Call Rate. Types of Call Centers.
Metrics, Measure, and Monitor – Make sure your metrics and associated goals are clear and concise while aligning with efficiency and effectiveness. Make each metric public and ensure everyone knows why that metric is measured. Interactive agent scripts from Zingtree solve this problem. Bill Dettering.
In the case of a call center, you will mark the performance of the agents against key performance indicators like script compliance and customer service. The goal of QA in any call center is to maintain high levels of service quality, ensure agents adhere to company policies and scripts, and identify areas of improvement.
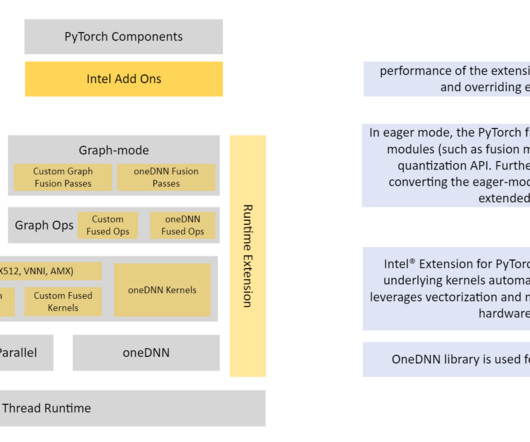
You can see that for the 45 models we benchmarked, there is a 1.35x latency improvement (geomean for the 45 models). You can see that for the 33 models we benchmarked, there is around 2x performance improvement (geomean for the 33 models). We benchmarked 45 models using the scripts from the TorchBench repo.
Encourage agents to cheer up callers with more flexible scripting. “A 2014 survey suggested that 69% of customers feel that their call center experience improves when the customer service agent doesn’t sound as though they are reading from a script. They are an easy way to track metrics and discover trends within your agents.
Measuring just a piece of this journey can seem short-sighted or not as powerful as other CX metrics, like Net Promoter Score (NPS). CX shouldn’t ever be measured by one metric alone. Customers and their experiences are complex and nuanced, so there’s no perfect metric. That alone is a powerful way to use CSAT.
We also included a data exploration script to analyze the length of input and output tokens. For demonstration purposes, we select 3,000 samples and split them into train, validation, and test sets. You need to run the Load and prepare the dataset section of the medusa_1_train.ipynb to prepare the dataset for fine-tuning.
Performance in a contact center refers to how effectively agents manage calls, resolve issues, and meet established benchmarks. Service Level Agreements (SLAs): Ensure compliance with SLAs, which outline expected service levels and performance metrics. Together, performance and QA form the backbone of a successful contact center.
This is why the amount of time spent on interactions is a key metric for ensuring the efficiency of your customer service. Contact Center AHT Components: Its important to understand that average handle time is, in a sense, a metric of metrics. Setting an Average Handle Time Benchmark: What is a Good AHT?
The SageMaker approval pipeline evaluates the artifacts against predefined benchmarks to determine if they meet the approval criteria. You can either have a manual approver or set up an automated approval workflow based on metrics checks in the aforementioned reports. We now explore this script in more detail.
Consequently, no other testing solution can provide the range and depth of testing metrics and analytics. And testingRTC offers multiple ways to export these metrics, from direct collection from webhooks, to downloading results in CSV format using the REST API. Happy days! You can check framerate information for video here too.
By Marcia Jenkins, Senior Operations Manager According to the 2021 Membership Marketing Benchmark report, it has been a challenging year for association membership. Scripting: The key to ensuring the long-term effectiveness of your outbound telemarketing script may be to eliminate the “script.” Is it failing?
The Executive Guide to Improving 6 Contact Center Metrics. Keep them up to date on new policies, best customer support practices, adjustments to the call center script, and more. As a contact center leader, it’s easy to get caught up in high-level metrics and reports. Improve the Customer Journey.
The digital nature of SaaS customer experience means that success outcomes are defined primarily in terms of digital, measurable key performance indicators, such as product usage metrics. SaaS success outcomes can be defined in terms of measurable digital benchmarks. Onboarding metrics, such as average time-to-value.
For more information on the TPC-H data, its database entities, relationships, and characteristics, refer to TPC Benchmark H. We use a preprocessing script to connect and query data from a PrestoDB instance using the user-specified SQL query in the config file. For more information on processing jobs, see Process data.
The prospect of fine-tuning open source multimodal models like LLaVA are highly appealing because of their cost effectiveness, scalability, and impressive performance on multimodal benchmarks. It sets up a SageMaker training job to run the custom training script from LLaVA. For full parameter fine-tuning, ml.p4d.24xlarge
All the training and evaluation metrics were inspected manually from Amazon Simple Storage Service (Amazon S3). The code to invoke the pipeline script is available in the Studio notebooks, and we can change the hyperparameters and input/output when invoking the pipeline.
Well, good news; at Spearline, we have a powerful scheduling tool that will execute test scripts in front of your WebRTC application at any interval throughout the day and night, alerting you to issues before your users even notice. Is your beauty sleep interrupted with nightmares of bad user experiences throughout the week?
From there, we dive into how you can track and understand the metrics and performance of the SageMaker endpoint utilizing Amazon CloudWatch metrics. We first benchmark the performance of our model on a single instance to identify the TPS it can handle per our acceptable latency requirements. Metrics to track.
The goal of NAS is to find the optimal architecture for a given problem by searching over a large set of candidate architectures using techniques such as gradient-free optimization or by optimizing the desired metrics. The performance of the architecture is typically measured using metrics such as validation loss. training.py ).
Thats where call center agent performance metrics come in. When the right metrics are tracked and acted upon, the results are undeniable. Lets explore how these performance metrics provide the foundation for a thriving call center and set you up to exceed both customer and business goals. But how do you measure success?
Thats where call center agent performance metrics come in. When the right metrics are tracked and acted upon, the results are undeniable. Lets explore how these performance metrics provide the foundation for a thriving call center and set you up to exceed both customer and business goals. But how do you measure success?
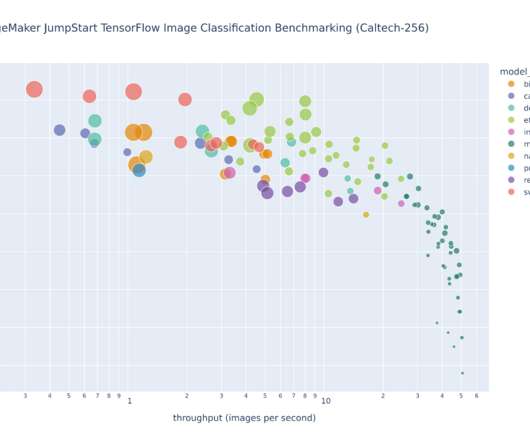
The former question addresses model selection across model architectures, while the latter question concerns benchmarking trained models against a test dataset. This post provides details on how to implement large-scale Amazon SageMaker benchmarking and model selection tasks. swin-large-patch4-window7-224 195.4M efficientnet-b5 29.0M
It may sound complicated, but a fairly simple set of KPI metrics can help you measure your lead source ROI. The most important KPI metrics for monitoring your lead source ROI are: Cost per Acquisition. There is no benchmark that determines whether your CPA is good enough or not. Sales script that needs improvement.
In this blog, we'll run you through all the important sales metrics and KPIs you need to assess for optimum results. . Measuring your sales metrics and KPIs is a healthy exercise for improving overall sales performance. But, weighing every other metric under the sun means you're in for a waste of your precious time.
Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training. Performance benchmark results. The quick way to identify a CPU bottleneck is to monitor CPU and GPU utilization metrics for SageMaker training jobs in Amazon CloudWatch.
Where discrete outcomes with labeled data exist, standard ML methods such as precision, recall, or other classic ML metrics can be used. These metrics provide high precision but are limited to specific use cases due to limited ground truth data. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
In this post, we show a high-level overview of how SMDDP works, how you can enable SMDDP in your Amazon SageMaker training scripts, and the performance improvements you can expect. Below is a sample result on 32 p4d instances comparing NCCL and SMDDP AllGather. 24xlarge nodes (512 NVIDIA A100 GPUs) PyTorch FSDP 97.89
The method is trained on a dataset of video clips and achieves state-of-the-art results on fashion video and human dance synthesis benchmarks, demonstrating its ability to animate arbitrary characters while maintaining appearance consistency and temporal stability. The implementation of AnimateAnyone can be found in this repository.
At Outsource Consultants, we understand the pivotal role these metrics play in driving success and enhancing customer experiences. By focusing on these essential metrics, contact centers can optimize their operations and deliver outstanding service. Train agents on the impact of these metrics.
Refer to the appendix for instance details and benchmark data. Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions. Benchmark data The following table compares the cost and relative performance between c5 and c6 instances.
These images contain the Neuron SDK (excluding the Neuron driver, which runs directly on the Trn1 instances), PyTorch training script, and required dependencies. Create a training container image Next, we need to create a training container image that includes the PyTorch training script along with any dependencies.
The deployments are done using bash scripts, and in this case we use the following command: bash malware_detection_deployment_scripts/deploy.sh -s ' ' -b 'malware- detection- -artifacts' -p -r " " -a. When the training models are complete, you can access the evaluation metrics by selecting Check metrics on the model page.
How to Maximize Outsourced Outbound Call Center Performance Set Clear Performance Metrics Effective management of an outsourced outbound call center requires specific, measurable goals. Set realistic targets based on industry benchmarks and your business objectives. Advanced analytics tools to optimize scripts and measure performance.
To showcase how this reduction can help you getting started with the creation of a custom entity recognizer, we ran some tests on a few open-source datasets and collected performance metrics. In this post, we walk you through the benchmarking process and the results we obtained while working on subsampled datasets. Dataset preparation.
Metrics are the most effective way of monitoring and measuring the performance of your contact centres. Tracking the right metrics can unlock a wealth of insights that will make your call centre operations more effective than ever. How can call centres improve metrics? What are the call centre metrics that need to be tracked?
Syne Tune allows us to find a better hyperparameter configuration that achieves a relative improvement between 1-4% compared to default hyperparameters on popular GLUE benchmark datasets. training script. We might also care about other objectives, such as training time, (dollar) cost, latency, or fairness metrics.
Lack of Confidence: Some managers are great at meeting metrics and making schedules. Tools like interaction analytics can help call center managers identify relevant issues and deliver precise, targeted feedback to agents and have a more direct impact on metrics like call handling time. I mean, really listen and act on what they say.
They dont just pull answers from a script; they analyze, predict, and adapt. 2025 Live Chat Benchmark Report Uncover key performance benchmarks across industries and see how AI is shaping the future of customer service. Recognizes keywords and follows scripts. Thats all you can say?!” Yeah, those days are over.
Laying the groundwork: Collecting ground truth data The foundation of any successful agent is high-quality ground truth data—the accurate, real-world observations used as reference for benchmarks and evaluating the performance of a model, algorithm, or system. Task completion rate – This measures the success rate of the agent.
To demonstrate the practical aspect of your customer profiles, write up role-play scripts for each profile and have staff act them out. Or, you might share a few metrics like FCR or abandon rate before and after your team uses Fonolo’s Voice Call-Backs! Act it out. Make the information universally available.
Even if you already have a pre-trained model, it may still be easier to use its corollary in SageMaker and input the hyperparameters you already know rather than port it over and write a training script yourself. The training and inference scripts for the selected model or algorithm.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content