This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In their 15th annual Net Promoter Benchmark Study, he gave a great presentation of some really interesting stats on NPS. Rocks and I will be presenting more information from Satmetrix’s 15th Annual Net Promoter Study in the upcoming webinar: “ 15 Years of Tracking Net Promoter: What Have We Learned? ” Quite a lot, it turns out.
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
In 2004, I presented to an insurance company in Germany about how they should be evoking the proper emotions in their customers. Once you have the buy-in from your organization, you need to figure out what you need to change in your present experience to evoke these emotions. It was a tough audience.
I went to a presentation about the results of our research concerning customer satisfaction with some of our key products and services. I was taken by the fact the person presenting was presenting it as if to say, “I don’t know why I bother in presenting this to you.” I stopped her and asked her why.
Cohere Embed 3 makes it simple to locate specific UI mockups, visual templates, and presentation slides based on a text description. All text-to-image benchmarks are evaluated using Recall@5 ; text-to-text benchmarks are evaluated using NDCG@10. Generic text-to-image benchmark accuracy is based on Flickr and CoCo.
To get the most out of this metric, use it to inform budgeting and infrastructure-related decisions as opposed to using it for agent benchmarking purposes. By harnessing the information each of the above metrics presents you with, it is possible to consistently improve your call center’s performance over time.
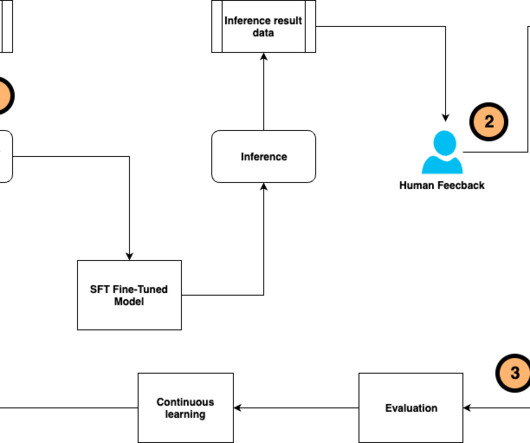
To address these challenges, we present an innovative continuous self-instruct fine-tuning framework that streamlines the LLM fine-tuning process of training data generation and annotation, model training and evaluation, human feedback collection, and alignment with human preference.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
There is a lack of focus on presenting the business case for your program. If you want to benchmark your organization’s performance in the new world of behavioral economics against other companies, take our short questionnaire. Companies look inside the organization to see what’s good for them.
We had people in to train us all on how to make this decision using this matrix, which was what to look for in a CRM system and how to “score” the presentation for the data we collected on it. After the presentations and the scoring, the matrix told us to go with Company A’s CRM. So, we didn’t. We’re depending on you to take action.
Net Promoter Score (NPS) benchmarkingpresents an interesting challenge for many business leaders. Collectively, we have learned a lot through NPS benchmarking studies. Collectively, we have learned a lot through NPS benchmarking studies. Drawbacks of NPS Benchmarking. Consider a Competitive Benchmark Study.
Some parts of science are presented, reinforced, and secured as fact; these are the trunk and the thick branches coming off the trunk of the tree. If you want to benchmark your organization’s performance in the new world of behavioral economics against other companies, take our short questionnaire. He compares it to a tree.
The ASQ Awards are a benchmark in the aviation industry, measuring airport performance directly through feedback collected via 700,000 live surveys in 2024. This year, 95 airports received recognition, with 181 awards presented across multiple categories , ranging from cleanliness to overall passenger enjoyment.
We engage in Behavioral Journey Mapping to determine where people are concerning their thinking as they progress through your present Customer Experience, what we call the “As Is” experience. In other words, you already present a mental model for how customers decide things in your experience.
Perhaps most importantly, these concepts and actions will keep you ahead of the competition, because if these trends at the end of last year say anything, it’s that the competition isn’t fairing much better than you with their Customer Experience at present.
The problem this presents is one of perception where “Our CX is failing, it’s time to turn it off” becomes an all too common occurrence. Present the facts, with an honest interpretation about what they mean for your business and encourage that message to move through your entire organisation.
The custom plugin presents information and insights directly within the Amazon Q Business interface, eliminating the need to switch between the New Relic and Amazon Q interfaces, and enabling faster problem resolution. This report provides clear, actionable recommendations and includes real-time application performance insights.
Online, you can present far more products. If you want to benchmark your organization’s performance in the new world of behavioral economics against other companies, take our short questionnaire. They have reduced an assortment of tens of thousands down to three easy steps. You can offer 50 million webcams if you want.
You have probably seen the meme on social media or heard John Mulaney’s joke about the surprising non-issue quicksand presents in adulthood: How to Design for Uncertainty in Your CX. If you want to benchmark your organization’s performance in the new world of behavioral economics against other companies, take our short questionnaire.
To calculate NPS scores, you must present your customers with a survey question: “How likely are you to recommend our product or service to a friend or colleague?” Let’s take a look at some NPS benchmarks for different industries: Average NPS by Industry in the USA, 2020. Net Promoter scale. The answers are scored on a 0-10 scale.
I talk a lot about how people are irrational and have presented evidence for it. If you want to benchmark your organization’s performance in the new world of behavioral economics against other companies, take our short questionnaire. Most people can get on board with the idea that we are not robots that are purely rational.
A Proactive Approach to Moderation in Virtual Reality The metaverse presents unparalleled opportunities for connection, immersion, and innovation. This case study highlights how structured, scalable moderation can transform player experiences, setting a benchmark for the industry at large.
The problem this presents is one of perception where “Our CX is failing, it’s time to turn it off” becomes an all too common occurrence. Present the facts, with an honest interpretation about what they mean for your business and encourage that message to move through your entire organisation.
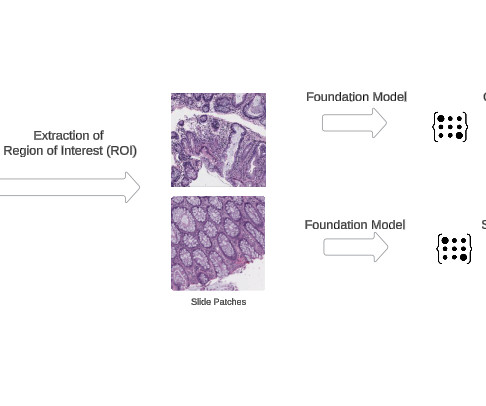
This sets a new benchmark for state-of-the-art performance in critical medical diagnostic tasks, from identifying cancerous cells to detecting genetic abnormalities in tumors. Use FMs for WSI-level tasks Analyzing entire WSIs presents unique challenges due to their massive size, often exceeding 50,000 x 50,000 pixels.
I presented my plan to spend my budget to improve our experience along with the benefits in customer loyalty we would gain for the investment. I went back to the committee a couple of months after that and presented the same case for my investment with a different name and a new look. However, the committee said no.
This post describes how to get started with the software development agent, gives an overview of how the agent works, and discusses its performance on public benchmarks. We are grateful to the team releasing and maintaining this benchmark. We are proud to be able to share our state-of-the-art results on this benchmark.
Here, we present our insights and top takeaways from The New 9 to 5: The State of CX in the Gig Economy – Customer Service Benchmark Report. View all of our findings in The New 9 to 5: The State of CX in the Gig Economy – Customer Service Benchmark Report ! The Gig Economy + CX.
Providing effective multilingual customer support in global businesses presents significant operational challenges. Through collaboration between AWS and DXC Technology, weve developed a scalable voice-to-voice (V2V) translation prototype that transforms how contact centers handle multi-lingual customer interactions.
In this sense, CES can almost act as a gauge of how well a company is doing against its benchmarks and those of competitors. Set Benchmarks and Goals All too many SaaS companies get caught up in CES data collection that they forget the reason they’re doing it altogether: to improve team and product performance.
The reaction you get presenting the same process to a customer in the morning is unlike what you would get at night after life has happened to them. If you want to benchmark your organization’s performance in the new world of behavioral economics against other companies, take our short questionnaire.
One of my all-time favorite sessions as a presenter was “The Case Against NPS” alongside Matt Beckwith. NPS Pros – There is no better metric for benchmarking data…across industries, historical timelines, and geographic regions.There is still no better metric for the overall Customer Experience. NPS still has value.
o Revisit the reports and slides you presented so far. Can you introduce a few changes and present KPIs differently than you did before? taking into consideration you are not present in the room). taking into consideration you are not present in the room). Benchmarks. Lessons learned.
Using these models, you too can learn how to go toe-to-toe with your Finance team by presenting trade-offs to get the headcount you need. In this article, we cover: Budgeting Benchmarks: Do They Cause More Harm than Good? Budgeting Benchmarks: Do They Cause More Harm than Good? Not exactly.
Here are some examples of these metrics: Retrieval component Context precision Evaluates whether all of the ground-truth relevant items present in the contexts are ranked higher or not. Evaluate RAG components with Foundation models We can also use a Foundation Model as a judge to compute various metrics for both retrieval and generation.
In fact many business strategies that I’ve seen, which seek to pepper their presentation with customer language, if you look closer are really channel strategies or product strategies – reflecting the current silos in that business. Too few companies have a Customer Strategy, let alone a Customer Insight (CI) Strategy.
Tokens We evaluated SageMaker endpoint hosted DeepSeek-R1 distilled variants on performance benchmarks using two sample input token lengths. DeepSeek-R1-Distill-Llama-8B DeepSeek-R1-Distill-Llama-8B was benchmarked across ml.g5.2xlarge , ml.g5.12xlarge , ml.g6e.2xlarge Then we repeated the test with concurrency 10.
For SaaS B2B clients, QBR meetings tend to focus on assessing value as measured by KPI performance benchmarks. Generate a report summarizing KPIs benchmarks from the last QBR and progress toward them. Prepare any presentation aids you want to incorporate, such as illustrative stories or graphs summarizing data. Demonstrate ROI.
Jina Embeddings v2 is the preferred choice for experienced ML scientists for the following reasons: State-of-the-art performance – We have shown on various text embedding benchmarks that Jina Embeddings v2 models excel on tasks such as classification, reranking, summarization, and retrieval. The answer should only use the presented context.
we released a LM+GNN benchmark using the large graph dataset, Microsoft Academic Graph (MAG), on two standard graph ML tasks: node classification and link prediction. min 10B 8 31 min 8 41 min 8 8 min 100B 16 61 min 16 416 min 16 50 min More benchmark details and results are available in our KDD 2024 paper. Dataset Num. of nodes Num.
Cloud solutions boast high reliability and present very compelling arguments. Quality levels before a migration can be used as a benchmark to gain full visibility of the impact of infrastructure changes. But, many engineering teams have had their fire fighting experiences. On-premises solutions have their imperfections as well.
Presented by: Dave Kellogg , principal, Dave Kellogg Consulting. Presented by: Ryan Johansen , a stress management consultant who trains CS professionals on becoming top performers without burning out. 4/ 2022 SaaS retention benchmarks: How does your company compare? Presented by: Rob Belcher , managing director, SaaS Capital.
“ NPS has been a good metric to benchmark and help brands understand the overall outcome of their experience. The full process in described in this presentation. Although the subtitle says "benchmark", don't rush into comparing your scores with top-performing companies. The real value is in the “WHY”. Now it's your turn!
The device further processes this response, including text-to-speech (TTS) conversion for voice agents, before presenting it to the user. The FM analyzes the prompt and begins generating an appropriate response, streaming it back to the users device.
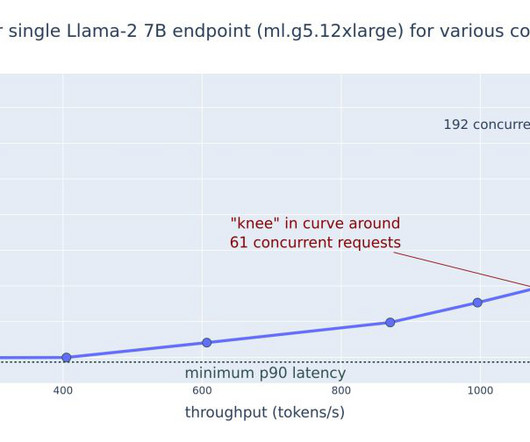
We start by describing our benchmarking approach and then present throughput vs. latency curves across batch sizes and data type precision. Benchmarking approach. We use Amazon Simple Storage Service (Amazon S3) as a common data store to download configuration and upload benchmark results for summarization. Model Type.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content