This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
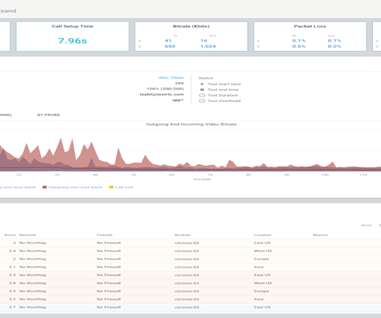
To get the most out of this metric, use it to inform budgeting and infrastructure-related decisions as opposed to using it for agent benchmarking purposes. By harnessing the information each of the above metrics presents you with, it is possible to consistently improve your call center’s performance over time.
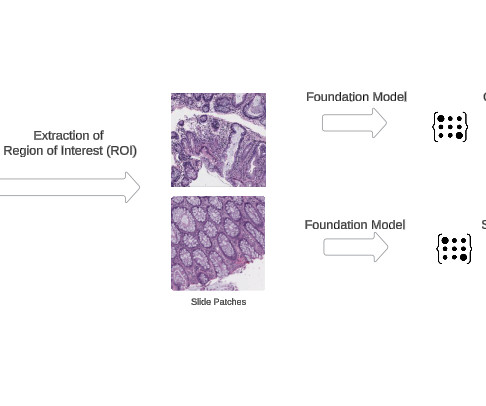
This sets a new benchmark for state-of-the-art performance in critical medical diagnostic tasks, from identifying cancerous cells to detecting genetic abnormalities in tumors. script that automatically downloads and organizes the data in your EFS storage. The AWS CloudFormation template for this solution uses t3.medium
Bill Dettering is the CEO and Founder of Zingtree , a SaaS solution for building interactive decision trees and agent scripts for contact centers (and many other industries). Interactive agent scripts from Zingtree solve this problem. Agents can also send feedback directly to script authors to further improve processes.
The prospect of fine-tuning open source multimodal models like LLaVA are highly appealing because of their cost effectiveness, scalability, and impressive performance on multimodal benchmarks. Subsequently, we used Python to generate different types of visual presentation such as pie charts and funnel charts based on the text descriptions.
Our Cx Culture Navigator benchmarking study included an assessment of the opinions of around 2,800 employees across 10 different organizations. We recently presented this at the CXPA Insight Exchange , check out the slides below. PeopleMetrics recently took up the challenge.
The software service industry presents unique challenges for customer success management while also creating unique opportunities that call for specific strategies. SaaS success outcomes can be defined in terms of measurable digital benchmarks. Customer success in SaaS differs from CS in other industries.
Well, good news; at Spearline, we have a powerful scheduling tool that will execute test scripts in front of your WebRTC application at any interval throughout the day and night, alerting you to issues before your users even notice. Is your beauty sleep interrupted with nightmares of bad user experiences throughout the week?
Code generation DBRX models demonstrate benchmarked strengths for coding tasks. user Write a Python script to read a CSV file containing stock prices and plot the closing prices over time using Matplotlib. The file should have columns named 'Date' and 'Close' for this script to work correctly. Let's break it down: 1.
Read Email Response Times: Benchmarks and Tips for Support for practical advice. Bot of America In what was initially presented as friendly, human social media service, but later revealed to be another bamboozled bot, Bank of America repeatedly sent generic “helpful” Twitter replies to an artist protesting the bank’s behavior.
In this blog post, we’ll first present our latest performance improvements in the SageMaker model parallel library. Finally, we’ll benchmark performance of 13B, 50B, and 100B parameter auto-regressive models and wrap up with future work. A ready-to-use training script for GPT-2 model can be found at train_gpt_simple.py.
Nowadays, we’re buying each other birthday presents and making inappropriate jokes. If it has a search engine, which most do, focus on putting in the correct keywords to get the script or article that you need to solve the customer’s problem. Understanding Industry Benchmarks. You don’t want them to hate you.
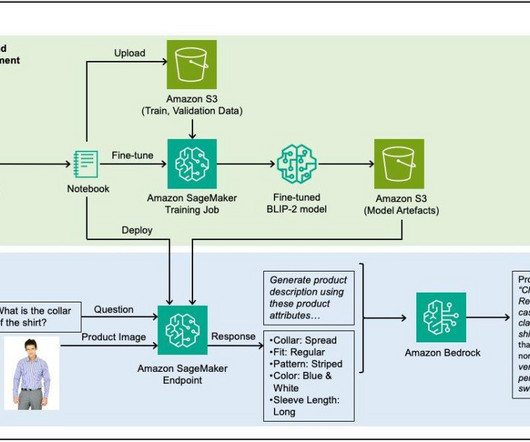
SageMaker starts and manages all of the necessary Amazon Elastic Compute Cloud (Amazon EC2) instances for us, supplies the appropriate Hugging Face container, uploads the specified scripts, and downloads data from our S3 bucket to the container to /opt/ml/input/data. We prepared entrypoint_vqa_finetuning.py
This notebook presents an end-to-end example of how to compile a Stable Diffusion model, save the compiled Neuron models, and load it into the runtime for inference. Configure the model with a provided script In this section, we show how to configure the LMI container to host the Stable Diffusion models. model on the GitHub repo.
Alternatively, with entity lists, you provide a list of entities with their corresponding entity type label, and a set of unannotated documents in which you expect your entities to be present. In this post, we walk you through the benchmarking process and the results we obtained while working on subsampled datasets.
Reporting & Visualization: Results are aggregated and presented in dashboards and reports, providing insights into individual agent performance, team trends, compliance adherence, and overall customer experience metrics. Measure performance based on targets that are aligned to your standards and benchmarks.
Solution overview In this section, we present the overall workflow and explain the approach. We use the Recognizing Textual Entailment dataset from the GLUE benchmarking suite. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset. training.py ).
In this second part, we present a proof-of-concept healthcare and life sciences use case from a real-world dataset eICU. For benchmark analysis, we considered the task of predicting the in-hospital mortality of patients [2]. script converts NumPy arrays into Torch tensors, as shown in the following code snippet. and data_loader.py
AlexaTM 20B has shown competitive performance on common natural language processing (NLP) benchmarks and tasks, such as machine translation, data generation and summarization. To use a large language model in SageMaker, you need an inferencing script specific for the model, which includes steps like model loading, parallelization and more.
DL scripts often require boilerplate code, notably the aforementioned double for loop structure that splits the dataset into minibatches and the training into epochs. At the time of this writing, it supports PyTorch and includes 25 techniques—called methods in the MosaicML world—along with standard models, datasets, and benchmarks.
The question is typically presented to the customer using a 1–5 scale, one being very dissatisfied and 5 being very satisfied. . Flip the script on your results and use that as a motivator. But if you are just starting to explore customer feedback in general, this is a simple way to get started and then benchmark against in the future.
Even if you already have a pre-trained model, it may still be easier to use its corollary in SageMaker and input the hyperparameters you already know rather than port it over and write a training script yourself. The training and inference scripts for the selected model or algorithm. Benchmarking the trained models.
As noted in the 2019 Dimension Data Customer Experience (CX) Benchmarking report: 88% of contact center decision-makers expect self-service volumes to increase over the next 12 months. Agents will be presented with increasingly more complex situations which will require more engagement, insight and analysis.
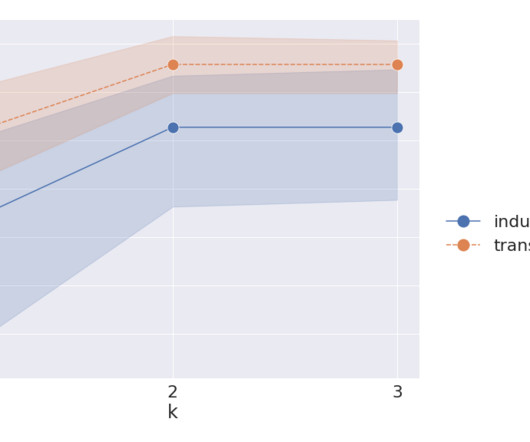
This post presents an implementation of a fraud detection solution using the Relational Graph Convolutional Network (RGCN) model to predict the probability that a transaction is fraudulent through both the transductive and inductive inference modes. Each training transaction is provided with a binary label denoting if it is fraudulent.
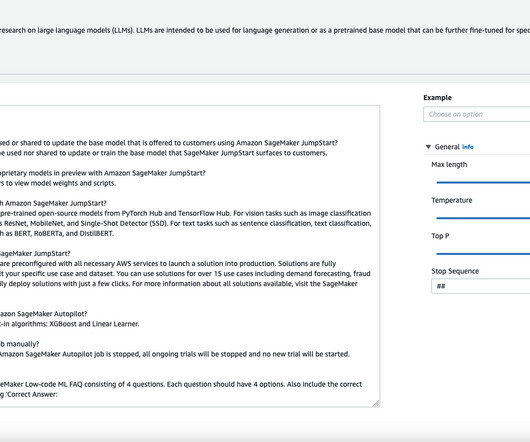
In this post, we present a comprehensive guide of deploying a multiple-choice quiz solution for the FAQ pages of any AWS service, based on the AI21 Jurassic-2 Jumbo Instruct foundation model on Amazon SageMaker Jumpstart. Q: Can I see the model weights and scripts of proprietary models in preview with Amazon SageMaker JumpStart?
To demonstrate the practical aspect of your customer profiles, write up role-play scripts for each profile and have staff act them out. Host inter-departmental updates, bring in outside teachers for workshops, or outside companies for presentations. Act it out. Make the information universally available. The format is up to you.
For our LLM, we use Llama 2 , the next generation open-source LLM, which outperforms existing open-source language models on many benchmarks, including reasoning, coding, proficiency, and knowledge tests. You can refer to the inference script and configuration file for more details.
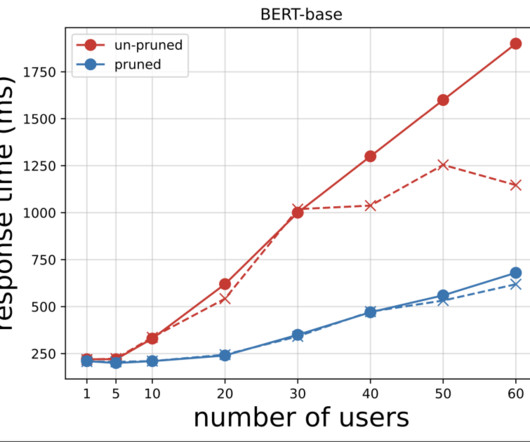
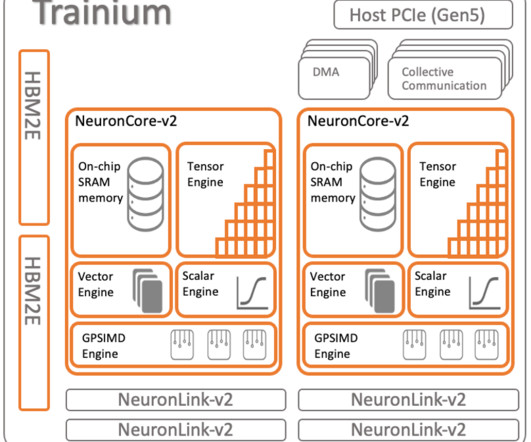
This is the same as developing any C++ function for PyTorch, and the only libraries that need to be present in the development environment are those for PyTorch and C++. She is also part of the Technical Field Community dedicated to hardware acceleration and helps with testing and benchmarking AWS Inferentia and AWS Trainium workloads.
Well, good news; at Spearline, we have a powerful scheduling tool that will execute test scripts in front of your WebRTC application at any interval throughout the day and night, alerting you to issues before your users even notice. Is your beauty sleep interrupted with nightmares of bad user experiences throughout the week?
Look into benchmarking. The benchmarking process is a continuous loop. The benchmarking process is a continuous loop. For some businesses, benchmarking and maintaining quality can be a challenge. Special circumstances will force agents to deviate from their scripts. Write solid scripts. Which ran long.
These include metrics such as ROUGE or cosine similarity for text similarity, and specific benchmarks for assessing toxicity (Detoxify), prompt stereotyping (cross-entropy loss), or factual knowledge (HELM, LAMA). The agent went over the details and presented the steps along necessary along with the documentation links.
This can include things like: Spending time updating outdated call scripts Improving the feedback sharing process between customer service and other teams Finding new learning opportunities for the team to level up their skills Putting measures in place to stay mentally healthy when working from home. Be a Good Performance Assessor.
Decision Tree: An “If this… then that” framework that guides the customer to choose from a list of pre-defined scripts and options. This framework can be presented either through keywords or buttons. You don’t need to be a bot expert or know how to code complex scripts to build a successful chatbot.
The scripts and tools sales agents are using don’t seem to match the company’s marketing efforts. . They prospect for one lead, nurture the next, make a presentation to another, and try to close a few others. Craft sales scripts for prospecting. . 2) Create personalized phone and email scripts .
First and foremost, Consumer Duty is presenting practical compliance challenges for companies, ensuring that all existing and planned customer communications about financial products meet all of the FCA’s new requirements - such as ensuring clear communications, value for money, and protecting vulnerable consumers.
Laying the groundwork: Collecting ground truth data The foundation of any successful agent is high-quality ground truth data—the accurate, real-world observations used as reference for benchmarks and evaluating the performance of a model, algorithm, or system.
Take advantage of free trials and benchmark different providers to stay informed. Ask about integrations with helpdesks, CRMs, script builders, survey templates, etc. Be present during the change. There are all considerations to keep in mind when picking your CTI system. Focus on success. Ask for training.
The use of real-time speech analytics (RTSA) solutions to continuously monitor conversations between agents and customers enables businesses to ensure the compliance of all calls by helping agents adhere to scripts, ensuring contracts are explained correctly and reducing cancellations and customer disputes.
Naturally, this is setting a new benchmark for E-commerce stores, since customers are choosing to shop at only the best websites in the competitive space. This is essentially a software program that uses scripted rules and AI to provide human customers with relevant guidance. Incorporate a digital sales agent. Lead generation.
According to our 2018 Live Chat Benchmark Report , Comm100’s Chatbot takes care of about 20% of all incoming live chat inquiries alone. They can also offer expansive menus that present customers with options that they weren’t even thinking about when they initiated the chat – encouraging clicks and product discovery.
Previously, it required a data scientist to write over 100 lines of code within an Amazon SageMaker Notebook to identify and retrieve the proper image, set the right training script, and import the right hyperparameters. RAG benchmark Compare the fine-tuned models performance against a RAG system using a pre-trained model.
Some call centers benchmarks you can use for quality assurance include categories like friendliness, efficiency, service, or other customer satisfaction metrics. After providing a score in each benchmark category based on a defined rubric, the call is then given an overall quality score. Are agents creative with their solutions?
On top of that, each new employee should have a benchmark assessment during a one-on-one session (we’d suggest on live calls) to highlight areas where they need to improve from the start. The format is up to you; host inter-departmental updates, bring in outside teachers for workshops, or companies for presentations.
You can also host customer panel or ask me anything (AMA) webinars to encourage more interactive, dynamic discussions compared to the traditional format with a sole presenter or one-way dialogue. For these types of less scriptedpresentations, having a moderator who is highly knowledgeable on the topic is a must.
It also presents opportunities to offer well-deserved praise when it’s warranted. Track your metrics and KPIs for at least a quarter to get a benchmark for goals to reach and surpass. Continually refine your call center scripts in response to data from customer feedback and call center data.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content