This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
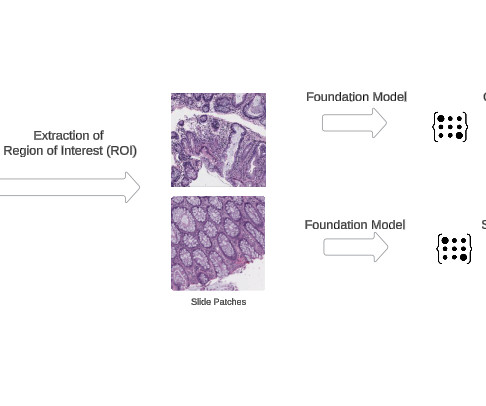
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
To get the most out of this metric, use it to inform budgeting and infrastructure-related decisions as opposed to using it for agent benchmarking purposes. Although some consumers place greater importance on accuracy than speed, AHT still has a special place in a call center’s daily operations. Customer Effort Score.
Chat scripts are a handy tool, especially for chat agents who find themselves often responding to related customer inquiries. Chat scripts, or canned responses, help companies ensure quality control, implement precise language for optimal results, and increase customer happiness. Not all companies implement chat scripts with success.
This sets a new benchmark for state-of-the-art performance in critical medical diagnostic tasks, from identifying cancerous cells to detecting genetic abnormalities in tumors. script that automatically downloads and organizes the data in your EFS storage. The AWS CloudFormation template for this solution uses t3.medium
In the case of a call center, you will mark the performance of the agents against key performance indicators like script compliance and customer service. The goal of QA in any call center is to maintain high levels of service quality, ensure agents adhere to company policies and scripts, and identify areas of improvement.
We also demonstrate the resulting speedup through benchmarking. Benchmark setup We used an AWS Graviton3-based c7g.4xl 1014-aws kernel) The ONNX Runtime repo provides inference benchmarkingscripts for transformers-based language models. The scripts support a wide range of models, frameworks, and formats.
You can see that for the 45 models we benchmarked, there is a 1.35x latency improvement (geomean for the 45 models). You can see that for the 33 models we benchmarked, there is around 2x performance improvement (geomean for the 33 models). We benchmarked 45 models using the scripts from the TorchBench repo.
Bill Dettering is the CEO and Founder of Zingtree , a SaaS solution for building interactive decision trees and agent scripts for contact centers (and many other industries). Interactive agent scripts from Zingtree solve this problem. Agents can also send feedback directly to script authors to further improve processes.
Call on experienced managers for guidance in setting up benchmarks. “Experienced call center managers are helpful in setting up the initial performance benchmarks for a new outbound call center program. These benchmarks are, at first, estimated based on the past performance of similar outbound call center projects.
Performance in a contact center refers to how effectively agents manage calls, resolve issues, and meet established benchmarks. Agent Script Adherence: Monitoring and measuring how well agents follow provided scripts. Set benchmarks against industry standards and collect as much valuable insights as possible.
Encourage agents to cheer up callers with more flexible scripting. “A 2014 survey suggested that 69% of customers feel that their call center experience improves when the customer service agent doesn’t sound as though they are reading from a script. Minimise language barriers with better hires.
That’s where a customer service script comes into play. Call handling scripts outline the customer’s journey and prompt the person representing your company to create a memorable and consistent interaction with a client, customer or business associate. They contain the preferred language and answers to commonly asked questions.
We also included a data exploration script to analyze the length of input and output tokens. As a next step, you can explore fine-tuning your own LLM with Medusa heads on your own dataset and benchmark the results for your specific use case, using the provided GitHub repository.
A call center scripting tool helps in building scripts for agents handling customer’s complaints and queries. These tools help develop the call center script in a structured way that is easy for both agents and customers to understand. . What Are Call Center Scripts? Decreased training time. Enhanced consistency.
Current evaluations from Anthropic suggest that the Claude 3 model family outperforms comparable models in math word problem solving (MATH) and multilingual math (MGSM) benchmarks, critical benchmarks used today for LLMs. Media organizations can generate image captions or video scripts automatically.
But nearly all contact center agents follow a script when engaging customers. Scripts ensure that agents are providing accurate information to customers. Given the high turnover rate for employees at most contact centers, scripts save time and money on training. The answer lies in real-time, branch logic dynamic scripting.
The SageMaker approval pipeline evaluates the artifacts against predefined benchmarks to determine if they meet the approval criteria. We now explore this script in more detail. Values passed to arguments can be parsed using standard methods like argparse and will be used throughout the script.
By Marcia Jenkins, Senior Operations Manager According to the 2021 Membership Marketing Benchmark report, it has been a challenging year for association membership. Scripting: The key to ensuring the long-term effectiveness of your outbound telemarketing script may be to eliminate the “script.” Is it failing?
It would also be helpful to give new hires information on which KPIs managers will assess, how these are tied to performance evaluations, and practical tips on how to hit their KPI benchmarks. Allow them to listen to recordings and also provide online scripts. Choose recordings that will help you demonstrate a specific point (i.e.,
wheels and set the previously mentioned environment variables # Clone PyTorch benchmark repo git clone [link] # Setup Resnet50 benchmark cd benchmark python3 install.py On successful completion of the inference runs, # the script prints the inference latency and accuracy results python3 run.py
For more information on the TPC-H data, its database entities, relationships, and characteristics, refer to TPC Benchmark H. We use a preprocessing script to connect and query data from a PrestoDB instance using the user-specified SQL query in the config file. For more information on processing jobs, see Process data.
Note that your model artifacts also include an inference script for preprocessing and postprocessing. If you don’t provide an inference script, the default inference handlers for the container you have chosen will be implemented. For these two frameworks, provide the model artifacts in the format the container expects.
Flip the script With testingRTC, you only need to write scripts once, you can then run them multiple times and scale them up or down as you see fit. testingRTC simulates any user behavior using our powerful Nightwatch scripting, you can manage these scripts via our handy git integration.
Keep them up to date on new policies, best customer support practices, adjustments to the call center script, and more. TIP: Call center scripts should be considered living documents, as they’ll need to be regularly updated to align with new industry trends, department goals, and both agent and customer feedback.
The prospect of fine-tuning open source multimodal models like LLaVA are highly appealing because of their cost effectiveness, scalability, and impressive performance on multimodal benchmarks. It sets up a SageMaker training job to run the custom training script from LLaVA. For full parameter fine-tuning, ml.p4d.24xlarge
Code generation DBRX models demonstrate benchmarked strengths for coding tasks. user Write a Python script to read a CSV file containing stock prices and plot the closing prices over time using Matplotlib. The file should have columns named 'Date' and 'Close' for this script to work correctly.
The team’s early benchmarking results show 7.3 The baseline model used in these benchmarking is a multi-layer perceptron neural network with seven dense fully connected layers and over 200 parameters. The following table summarizes the benchmarking result on ml.p3.16xlarge SageMaker training instances. Number of Instances.
Our Cx Culture Navigator benchmarking study included an assessment of the opinions of around 2,800 employees across 10 different organizations. When you listen to employee/customer interactions you hear scripted conversations and inflexible policies not real people with individual discretion to take the right action for the customer.
Setting an Average Handle Time Benchmark: What is a Good AHT? So, while this industry standard offers a good starting place for contact centers looking to benchmark their own performance, its important to analyze your operations metrics within their historical context to derive insights that guide your strategies for improvement.
In this post, we dive deep into the new features with the latest release of LMI DLCs, discuss performance benchmarks, and outline the steps required to deploy LLMs with LMI DLCs to maximize performance and reduce costs. Performance benchmarking results We compared the performance of the latest SageMaker LMI DLCs version (0.25.0)
We cover computer vision (CV), natural language processing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking. You can use the sample notebook to run the benchmarks and reproduce the results. Create an endpoint configuration.
SaaS success outcomes can be defined in terms of measurable digital benchmarks. Laying out a customer journey map allows CS teams to set measurable goals for each customer experience stage, set benchmarks, and implement automated strategies corresponding to mapped stages. Both automated and manual tracking serve a role.
Well, good news; at Spearline, we have a powerful scheduling tool that will execute test scripts in front of your WebRTC application at any interval throughout the day and night, alerting you to issues before your users even notice. Is your beauty sleep interrupted with nightmares of bad user experiences throughout the week?
To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script. In this section, we only call out a few main steps with code snippets from the ready-to-use training script train_gpt_simple.py. The notebook uses the script data_prep_512.py Benchmarking performance. return loss.
Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training. Performance benchmark results. You can build logic in your training script to assign the instance groups to certain training and data processing tasks.
SageMaker LMI containers provide two ways to deploy the model: A no-code option where we just provide a serving.properties file with the required configurations Bring your own inference script We look at both solutions and go over the configurations and the inference script ( model.py ). The container requires your model.py
We first benchmark the performance of our model on a single instance to identify the TPS it can handle per our acceptable latency requirements. Note that the model container also includes any custom inference code or scripts that you have passed for inference. Any issues related to end-to-end latency can then be isolated separately.
In this post, we show a high-level overview of how SMDDP works, how you can enable SMDDP in your Amazon SageMaker training scripts, and the performance improvements you can expect. Below is a sample result on 32 p4d instances comparing NCCL and SMDDP AllGather. 24xlarge nodes (512 NVIDIA A100 GPUs) PyTorch FSDP 97.89
We’ll cover fine-tuning your foundation models, evaluating recent techniques, and understanding how to run these with your scripts and models. We’ll cover preparing training datasets at scale on AWS, including picking the right instances and storage techniques.
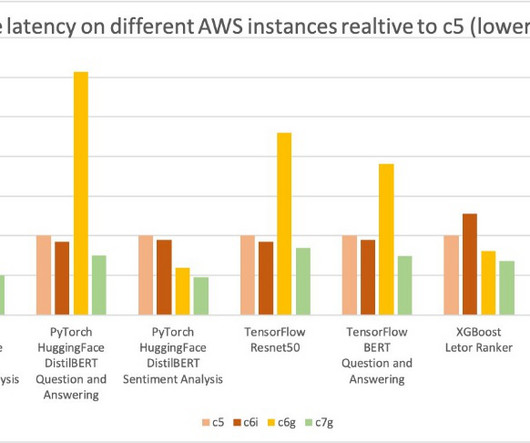
Refer to the appendix for instance details and benchmark data. Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions. Benchmark data The following table compares the cost and relative performance between c5 and c6 instances.
Read Email Response Times: Benchmarks and Tips for Support for practical advice. This one was a robot, but there are plenty of real humans who aren’t able to break from the script even when the play suddenly has a new act. Be careful about scripting customer service responses too tightly. You’ll spot the rough edges more easily.
. * The `if __name__ == "__main__"` block checks if the script is being run directly or imported. To run the script, you can use the following command: ``` python hello.py ``` * The output will be printed in the console: ``` Hello, world! Evaluate model on test set, compare to benchmarks, analyze errors and biases.
The code to invoke the pipeline script is available in the Studio notebooks, and we can change the hyperparameters and input/output when invoking the pipeline. This is quite different from our earlier method where we had all the parameters hard coded within the scripts and all the processes were inextricably linked.
In such cases, standards provide a useful benchmark, especially for new employees learning how to do the job. But service standards can also be too rigid, or too scripted, and inadvertently degrade a service experience or cause damage to a service brand. Standards can also support your brand.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content