This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we discuss bestpractices for working with FMEval in ground truth curation and metric interpretation for evaluating question answering applications for factual knowledge and quality. Ground truth data in AI refers to data that is known to be true, representing the expected outcome for the system being modeled.
Site monitors conduct on-site visits, interview personnel, and verify documentation to assess adherence to protocols and regulatory requirements. However, this process can be time-consuming and prone to errors, particularly when dealing with extensive audio recordings and voluminous documentation.
This pipeline could be a batch pipeline if you prepare contextual data in advance, or a low-latency pipeline if you’re incorporating new contextual data on the fly. In the batch case, there are a couple challenges compared to typical data pipelines. He entered the bigdata space in 2013 and continues to explore that area.
Organizations are similarly challenged by the overflow of BigData from transactions, social media, records, interactions, documents, and sensors. But the ability to correlate and link all of this data, and derive meaningful insights, can offer a great opportunity.
Amazon SageMaker Model Cards enable you to standardize how models are documented, thereby achieving visibility into the lifecycle of a model, from designing, building, training, and evaluation. SageMaker model cards document critical details about your ML models in a single place for streamlined governance and reporting.
An agile approach brings the full power of bigdata analytics to bear on customer success. An agile approach to CS management can be broken down into seven steps: Document your client’s requirements. Document Your Client’s Requirements. Standardize your documentation approach by developing a requirements template.
View this document on the publisher’s website. Advancements in artificial intelligence (AI), machine learning, BigData analytics, and mobility are all driving contact center innovation. This BigData application is intended to track, evaluate, and measure activities and sentiment at every step of the customer journey.
Use group sharing engines to share documents with strategies and knowledge across departments. Create CX playbooks & bestpractice to guide interactions with customers. Data can be insightful to all of the roles HR takes on in facilitating the company’s CX goals. —@tcrawford. —@EngageGXD.
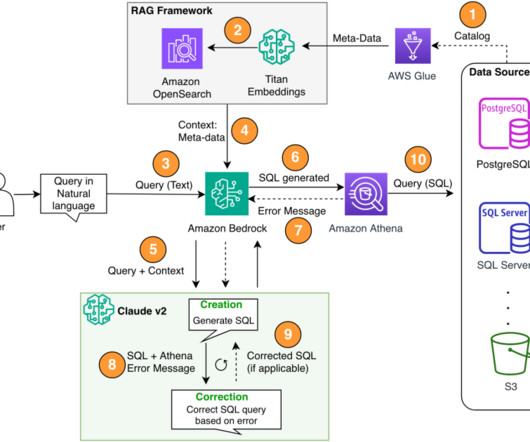
Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources. Clean up To clean up the resources, you can start by cleaning up your S3 bucket where the data resides.
Amazon Q returns the response as a JSON object (detailed in the Amazon Q documentation ). sourceAttributions – The source documents used to generate the conversation response. In Retrieval Augmentation Generation (RAG), this always refers to one or more documents from enterprise knowledge bases that are indexed in Amazon Q.
One of the tools available as part of the ML governance is Amazon SageMaker Model Cards , which has the capability to create a single source of truth for model information by centralizing and standardizing documentation throughout the model lifecycle. They provide a fact sheet of the model that is important for model governance.
For example, a use case that’s been moved from the QA stage to pre-production could be rejected and sent back to the development stage for rework because of missing documentation related to meeting certain regulatory controls. About the authors Ram Vittal is a Principal ML Solutions Architect at AWS.
In general, Addepto’s services consist of comprehensive consulting services regarding bigdata analytics and data science, business intelligence (BI), machine learning (ML), artificial intelligence (AI), and even AI software development. With Addepto’s help, your company will make the most of NLP.
Business analysts are involved in activities such as relationship building, process evaluation, requirements gathering, process improvement, scope definition, requirements documentation, non-technical and technical design, scope management, project support, charting future direction and road mapping.
Amazon Kendra supports a variety of document formats , such as Microsoft Word, PDF, and text from various data sources. In this post, we focus on extending the document support in Amazon Kendra to make images searchable by their displayed content. This means you can manipulate and ingest your data as needed.
Clients can use document as a source for planning and work closely with both the business and technical teams to ensure success to deliver on the brand’s promise. Evolve commerce with interaction and behavior pattern analytics by putting bigdata to work. Strive for unity among channel connectivity.
If an organization has undocumented features of its API, for instance, or if someone is rolling out an API and doesn’t have it properly documented or controlled, hackers can potentially take advantage. At the end of the day, businesses must be cautious as to what is being exposed and documented when writing APIs.
Synchronous translation has limits on the document size it can translate; as of this writing, it’s set to 5,000 bytes. For larger document sizes, consider using an asynchronous route of creating the job using start_text_translation_job and checking the status via describe_text_translation_job.
Companies use advanced technologies like AI, machine learning, and bigdata to anticipate customer needs, optimize operations, and deliver customized experiences. Objective Data conversion for storage and retrieval. Scope Limited to data and documents. Efficiency and automation of existing workflows.
This is a story about finding the hidden gems in your customer interaction data. And the good news is you don’t need “BigData” to find them. In the age of bigdata, insights around workflow processes and creating better documentation can be lost. So, what should you do with it?
In addition to an overview of the vendor, these documents identify key differentiators, product offerings, and provide a number of features that should help a client create short list when determining which vendor to put on out an RFI or RFP. Today, it maintains two offices, one in San Mateo, California and one in Tel Aviv, Israel.
To learn more about real-time endpoint architectural bestpractices, refer to Creating a machine learning-powered REST API with Amazon API Gateway mapping templates and Amazon SageMaker. In this example, we’re passing the data through as an S3 object; alternatively, that data may be sent directly to the Sagemaker endpoint.
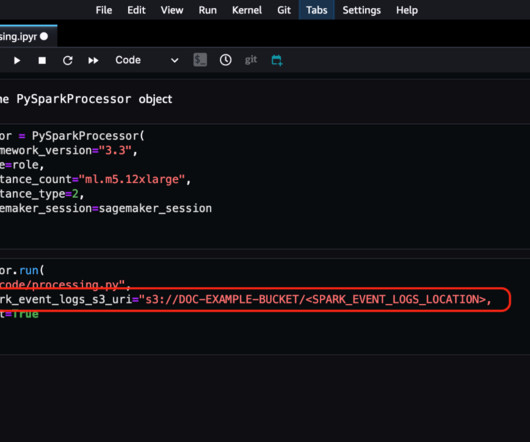
Amazon SageMaker offers several ways to run distributed data processing jobs with Apache Spark, a popular distributed computing framework for bigdata processing. It offers magic ( %spark , %sql ) commands to run Spark code, perform SQL queries, and configure Spark settings like executor memory and cores.
Anand Moorthy, Vice President, Global Testing Practice, Financial Services, Capgemini stated, “Our collaboration with Blueprint provides very robust requirements and documentation tools for customer implementations and internal product development,” said.
When you meet face-to-face, you can also securely share sensitive documents and information. Top features include screen sharing (for presentations) and on-screen collaboration (for documents). Read our article to find out more bestpractices for SMS texting. You can also easily share documents, images, and links.
You can change the existing policies here by selecting the policy and editing the document. This role can also be recreated via Infrastructure as Code (IaC) by simply taking the contents of the policy documents and inserting them into your existing solution. Note that the following policy locks down Studio domain creation to VPC only.
You can learn more on the Canvas product page and documentation. His knowledge ranges from application architecture to bigdata, analytics, and machine learning. As business analysts, we created various visualizations to assess the trends in QuickSight. This capability is available in all Regions where Canvas is now supported.
In the artificial intelligence (AI) space, athenahealth uses data science and machine learning (ML) to accelerate business processes and provide recommendations, predictions, and insights across multiple services. Each project maintained detailed documentation that outlined how each script was used to build the final model.
One of the tools available as part of the ML governance is Amazon SageMaker Model Cards , which has the capability to create a single source of truth for model information by centralizing and standardizing documentation throughout the model lifecycle. They provide a fact sheet of the model that is important for model governance.
Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on bigdata and analytics and AI/ML with Amazon Web Services. Raj provided technical expertise and leadership in building data engineering, bigdata analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS.
Amazon Comprehend is a fully managed and continuously trained natural language processing (NLP) service that can extract insight about the content of a document or text. With 8 years of experience in the IT industry, Ray is dedicated to building modern solutions on the cloud, especially in NoSQL, bigdata, and machine learning.
Despite significant advancements in bigdata and open source tools, niche Contact Center Business Intelligence providers are still wed to their own proprietary tools leaving them saddled with technical debt and an inability to innovate from within. Together, we can develop bestpractices and sharable templates for the entire industry.
More information can be found in the official MLflow documentation. He regularly speaks at AI and machine learning conferences across the world including O’Reilly AI, Open Data Science Conference, and BigData Spain. At this point, the MLflow SDK only needs AWS credentials.
And you can look at various specific areas such as data analytics, bigdata, being able to study patterns within data, using artificial intelligence or using machine learning to actually gather up every customer interaction, and remember the original problem and the solution. This kind of thing really helps the agents.
The goal of this post is to empower AI and machine learning (ML) engineers, data scientists, solutions architects, security teams, and other stakeholders to have a common mental model and framework to apply security bestpractices, allowing AI/ML teams to move fast without trading off security for speed.
The Senior Back-End Software Engineer will have demonstrated practical experience in building high-performance and reliable systems and possess a love for Git and all that version control provides (we can also accept a love/hate relationship with Git). Design, implement, and document new platform features and associated unit tests.
Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks. These models take the extracted summaries as input and produce abstractive summaries that capture the essence of the original document while ensuring readability and coherence.
Enhancing documentation and support: Provide comprehensive documentation and support resources to guide external clients through the BYOM process, including bestpractices for model preparation, integration, and optimization. Saurabh Gupta is a Principal Engineer at Zeta Global.
In this post, we discuss bestpractices for applying LLMs to generate ground truth for evaluating question-answering assistants with FMEval on an enterprise scale. By following these guidelines, data teams can implement high fidelity ground truth generation for question-answering use case evaluation with FMEval.
When a query arises, analysts must engage in a time-consuming process of reaching out to subject matter experts (SMEs) and go through multiple policy documents containing standard operating procedures (SOPs) relevant to the query. They spend hours consulting SMEs and reviewing extensive policy documents.
Model cards are an essential component for registered ML models, providing a standardized way to document and communicate key model metadata, including intended use, performance, risks, and business information. The Amazon DataZone project ID is captured in the Documentation section.
Your task is to review a proposal document from the perspective of a given persona, and assess it based on dimensions defined in a rubric. Review the provided proposal document: {PROPOSAL} 2. Ben West is a hands-on builder with experience in machine learning, bigdata analytics, and full-stack software development.
Data scientists Perform data analysis, model development, model evaluation, and registering the models in a model registry. Governance officer Review the models performance including documentation, accuracy, bias and access, and provide final approval for models to be deployed. However, the journey doesnt stop here.
She helps AWS customers to bring their big ideas to life and accelerate the adoption of emerging technologies. Hin Yee works closely with customer stakeholders to identify, shape and deliver impactful use cases leveraging Generative AI, AI/ML, BigData, and Serverless technologies using agile methodologies.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content