This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A Harvard Business Review study found that companies using bigdata analytics increased profitability by 8%. While this statistic specifically addresses data-centric strategies, it highlights the broader value of well-structured technical investments. If you handle credit card payments, look for people familiar with PCI DSS.
Challenges in data management Traditionally, managing and governing data across multiple systems involved tedious manual processes, custom scripts, and disconnected tools. This approach was not only time-consuming but also prone to errors and difficult to scale.
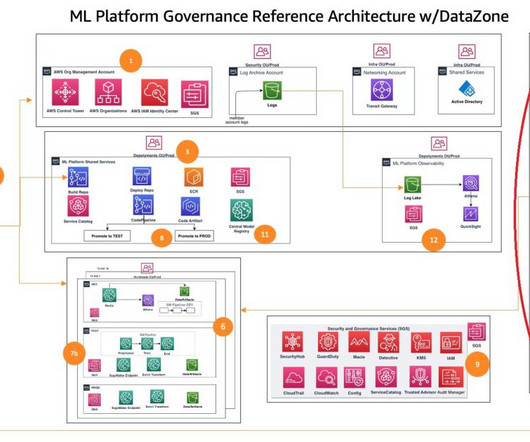
It also helps achieve data, project, and team isolation while supporting software development lifecycle bestpractices. He is passionate about building secure and scalable AI/ML and bigdata solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes.
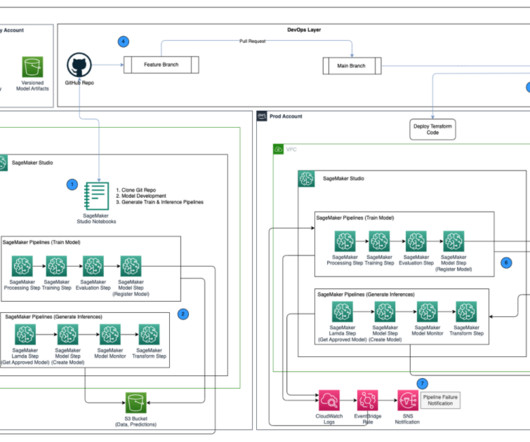
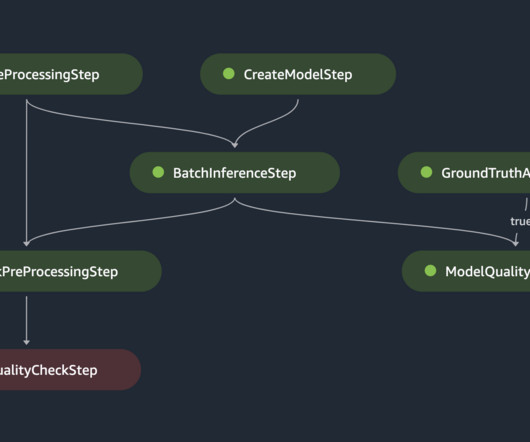
You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices. framework/createmodel/ – This directory contains a Python script that creates a SageMaker model object based on model artifacts from a SageMaker Pipelines training step. script is used by pipeline_service.py The model_unit.py
Under Advanced Project Options , for Definition , select Pipeline script from SCM. For Script Path , enter Jenkinsfile. upload_file("pipelines/train/scripts/raw_preprocess.py","mammography-severity-model/scripts/raw_preprocess.py") s3_client.Bucket(default_bucket).upload_file("pipelines/train/scripts/evaluate_model.py","mammography-severity-model/scripts/evaluate_model.py")
Today, CXA encompasses various technologies such as AI, machine learning, and bigdata analytics to provide personalized and efficient customer experiences. The development of chatbots, automated email responses, and AI-driven customer support tools marked a new era in customer service automation.
The business analyst’s role is to evaluate the customer experience and then identify how to improve the customer experience either with software changes or call center script changes. They can assess how current scripts are performing and change them as needed. There would be no operations without customers.
To learn more about real-time endpoint architectural bestpractices, refer to Creating a machine learning-powered REST API with Amazon API Gateway mapping templates and Amazon SageMaker. default_bucket() upload _path = f"training data/fhe train.csv" boto3.Session().resource("s3").Bucket resource("s3").Bucket Bucket (bucket).Object
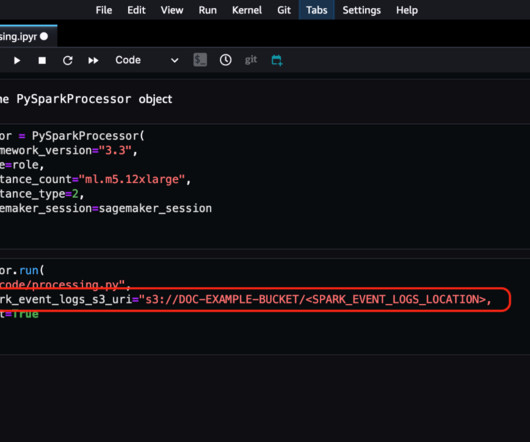
Amazon SageMaker offers several ways to run distributed data processing jobs with Apache Spark, a popular distributed computing framework for bigdata processing. install-scripts chmod +x install-history-server.sh./install-history-server.sh script and attach it to an existing SageMaker Studio domain.
Amazon CodeWhisperer currently supports Python, Java, JavaScript, TypeScript, C#, Go, Rust, PHP, Ruby, Kotlin, C, C++, Shell scripting, SQL, and Scala. times more energy efficient than the median of surveyed US enterprise data centers and up to 5 times more energy efficient than the average European enterprise data center.
Refer to Operating model for bestpractices regarding a multi-account strategy for ML. Data I/O design SageMaker interacts directly with Amazon S3 for reading inputs and storing outputs of individual steps in the training and inference pipelines. Refer to the./env_files/dev_env.tfvars
You can also find the script on the GitHub repo. He helps organizations in achieving specific business outcomes by using data and AI, and accelerating their AWS Cloud adoption journey. He has extensive experience across bigdata, data science, and IoT, across consulting and industrials.
The pipeline allowed Amp data engineers to easily deploy Airflow DAGs or PySpark scripts across multiple environments. Amp used Amazon EMR on Amazon Elastic Kubernetes Service (Amazon EKS) to configure and manage containers for their data processing and transformation jobs. Data Engineer for Amp on Amazon.
You can use this script add_users_and_groups.py After running the script, if you check the Amazon Cognito user pool on the Amazon Cognito console, you should see the three users created. import boto3 # Session using the SageMaker Execution Role in the Data Science Account session = boto3.Session() large', framework_version='1.0-1',
Each project maintained detailed documentation that outlined how each script was used to build the final model. In many cases, this was an elaborate process involving 5 to 10 scripts with several outputs each. These had to be manually tracked with detailed instructions on how each output would be used in subsequent processes.
These systems were basically guided menus that enabled customers to reach the best matching agents for their queries instead of wasting time talking to the wrong agents. With AI, you’ll be able to monitor your agents’ adherence to your company’s compliance guidelines and bestpractices.
But modern analytics goes beyond basic metricsit leverages technologies like call center data science, machine learning models, and bigdata to provide deeper insights. Predictive Analytics: Uses historical data to forecast future events like call volumes or customer churn. What is contact center bigdata analytics?
And if you’re still relying on a traditional contact center model with long wait times, scripted interactions, and frustrated customers, your business is destined to lose a lot of customers, and concurrently, money. Customer expectations have reached new heights, and businesses must adapt to meet their demands.
For example, conversation intelligence tools can automatically scan conversations and detect whether any agents are deviating from the script. Balto tests different responses to common customer objections to determine what works best so you can instantly scale bestpractices across your entire team to boost revenue.
Read our article to find out more bestpractices for SMS texting. If you’ve ever encountered a customer support agent who’s been using a script, then you know how frustrated your customers will feel if your agents do the same. AI and bigdata are more available now in customer service programs and tools.
And you can look at various specific areas such as data analytics, bigdata, being able to study patterns within data, using artificial intelligence or using machine learning to actually gather up every customer interaction, and remember the original problem and the solution.
Data Security & Privacy in AI Chatbot Communication for Enterprise Business Data security and privacy are critical considerations for any enterprise business using AI chatbots to communicate with customers or employees. Here’s a step-by-step guide to getting started with chatbot scripts. Like what you are reading?
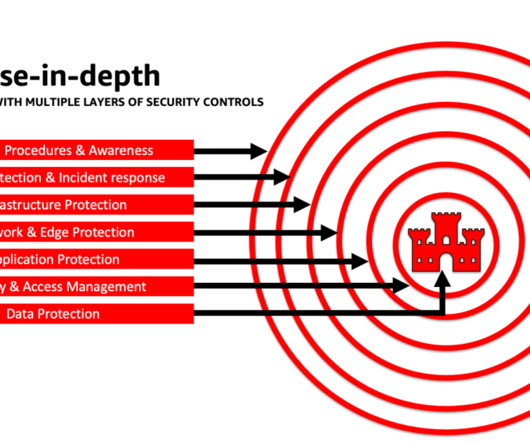
The goal of this post is to empower AI and machine learning (ML) engineers, data scientists, solutions architects, security teams, and other stakeholders to have a common mental model and framework to apply security bestpractices, allowing AI/ML teams to move fast without trading off security for speed.
This year, expect companies to adopt bestpractices in knowledge management so that information is easier to find and utilize for greater service efficiencies. BigData is Getting Bigger. IDC predicts that the market for BigData will reach $16.1 Source: The Contact Center Satisfaction Index Mid-Year 2013.
Create slide decks, presentations, digital material, weekly blogs, and scripts for animations and videos. Experience researching and reporting on relevant industry trends and bestpractices to identify opportunities for new or improved SEO content. Experience and/or knowledge of AI, BigData, Tech.
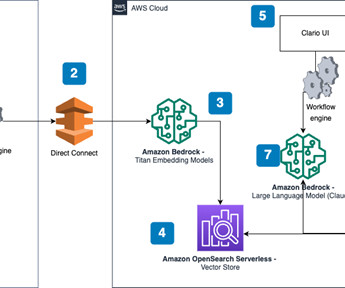
The solution is shown in the following figure: Architecture walkthrough Charter-derived documents are processed in an on-premises script in preparation for uploading. The script chunks the documents and calls an embedding model to produce the document embeddings. Files are sent to AWS using AWS Direct Connect.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content