This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Use of recorded calls where similar issues were handled adeptly are particularly effective here.” – 5 Call Center Training BestPractices , CallMiner; Twitter: @CallMiner. ” – 15 BestPractices For Effective Call Center Management , Sling. Offer rewards for great performance.
In this post, we provide bestpractices to maximize the value of SageMaker HyperPod task governance and make the administration and data science experiences seamless. As a bestpractice, set the fair-share weight higher for teams that will require access to capacity sooner than other teams.
By following industry bestpractices for healthcare call centers, your organization can address patient needs better and deliver exceptional care. The agents gain essential skills needed to refine their communication skills a stay current with bestpractices.
Building cloud infrastructure based on proven bestpractices promotes security, reliability and cost efficiency. We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected bestpractices.
Frontline excellence training instructs managers in the following bestpractices of great coaches : Providing dedicated coaching with role modeling for the supervisors. The post BestPractices of Great Coaches appeared first on The Northridge Group. Accountability is essential for coaches as well as associates.
This succinct buying guide will help you cut through the noise in the call center software market and choose the best tools for your organization. The following series of tips and bestpractices simplify the selection process, allowing you to decide on excellent software options without wasting time.
Security – The solution uses AWS services and adheres to AWS Cloud Security bestpractices so your data remains within your AWS account. For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository.
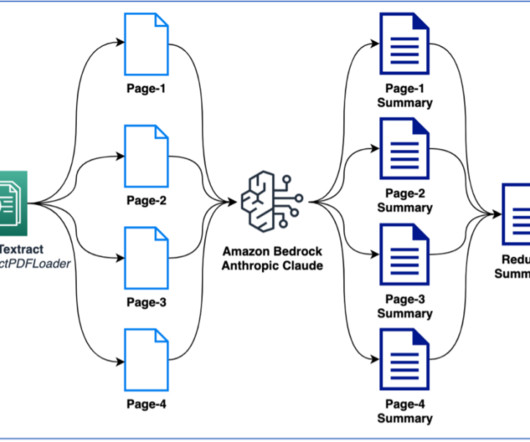
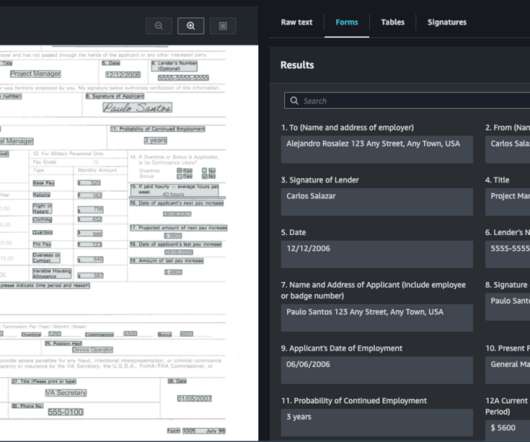
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Queries is a feature that enables you to extract specific pieces of information from varying, complex documents using natural language.
Amazon Bedrock Knowledge Bases has a metadata filtering capability that allows you to refine search results based on specific attributes of the documents, improving retrieval accuracy and the relevance of responses. Improving document retrieval results helps personalize the responses generated for each user.
Every year, AWS Sales personnel draft in-depth, forward looking strategy documents for established AWS customers. These documents help the AWS Sales team to align with our customer growth strategy and to collaborate with the entire sales team on long-term growth ideas for AWS customers.
Because these bestpractices might not be appropriate or sufficient for your environment, use them as helpful considerations rather than prescriptions. Bestpractice 2 – Communicate over a private network path Many customers rely on encryption in transit to securely communicate with Amazon Transcribe over the Internet.
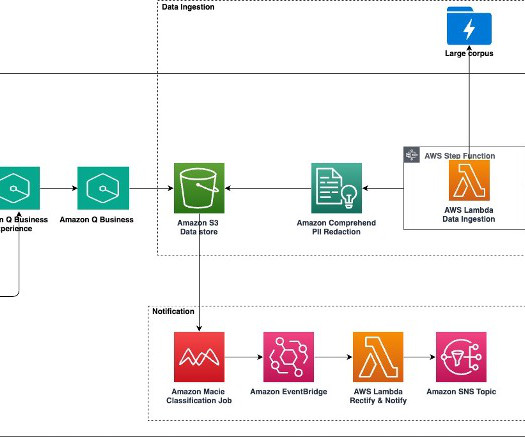
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
We developed the Document Translation app, which uses Amazon Translate , to address these issues. The Document Translation app uses Amazon Translate for performing translations. Amazon Translate provides high-quality document translations for contextual, accurate, and fluent translations. 1 – Translating a document.
For modern companies that deal with enormous volumes of documents such as contracts, invoices, resumes, and reports, efficiently processing and retrieving pertinent data is critical to maintaining a competitive edge. What if there was a way to process documents intelligently and make them searchable in with high accuracy?
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
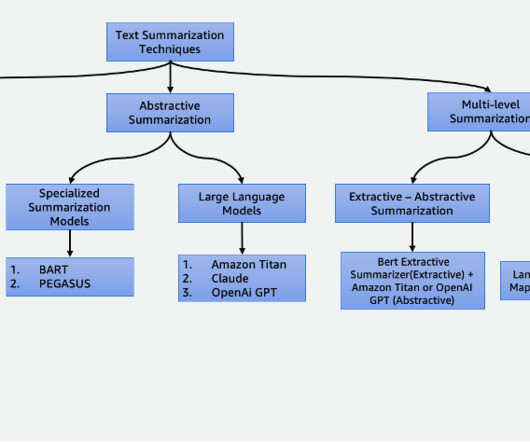
Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks. These models take the extracted summaries as input and produce abstractive summaries that capture the essence of the original document while ensuring readability and coherence.
While using their data source, they want better visibility into the document processing lifecycle during data source sync jobs. They want to know the status of each document they attempted to crawl and index, as well as the ability to troubleshoot why certain documents were not returned with the expected answers.
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. Then we introduce the solution deployment using three AWS CloudFormation templates.
There are several use cases where RAG can help improve FM performance: Question answering – RAG models help question answering applications locate and integrate information from documents or knowledge sources to generate high-quality answers. The retrieved information provides useful context and ideas.
We also discuss the lessons learned and bestpractices for you to implement the solution for your real-world use cases. You are required to provide a summarization based on given document. The document is provided in XML tags. Do not add any information that is not mentioned in the document.
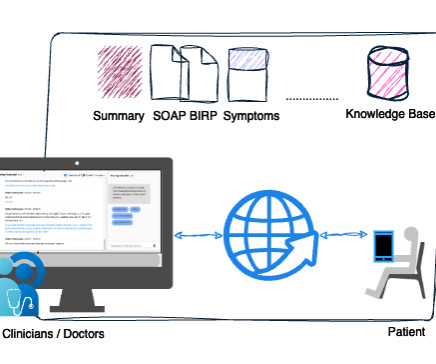
Today, physicians spend about 49% of their workday documenting clinical visits, which impacts physician productivity and patient care. By using the solution, clinicians don’t need to spend additional hours documenting patient encounters. This blog post focuses on the Amazon Transcribe LMA solution for the healthcare domain.
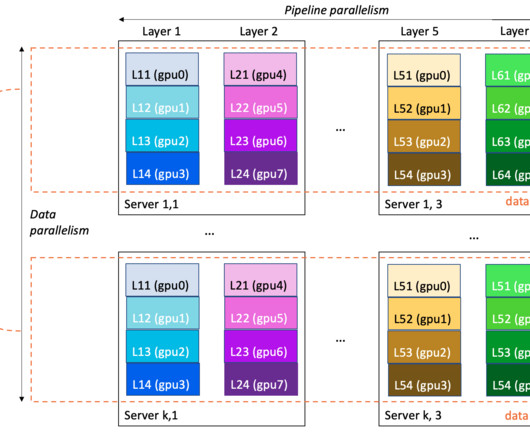
In this post, we dive into tips and bestpractices for successful LLM training on Amazon SageMaker Training. The post covers all the phases of an LLM training workload and describes associated infrastructure features and bestpractices. Some of the bestpractices in this post refer specifically to ml.p4d.24xlarge
RAG workflow: Converting data to actionable knowledge RAG consists of two major steps: Ingestion Preprocessing unstructured data, which includes converting the data into text documents and splitting the documents into chunks. Document chunks are then encoded with an embedding model to convert them to document embeddings.
The following is an example FlowMultiTurnInputRequestEvent JSON object: { "nodeName": "Trip_planner", "nodeType": "AgentNode", "content": { "document": "Certainly! The following is an example FlowOutputEvent JSON object: { "nodeName": "FlowOutputNode", "content": { "document": "Great news! I've successfully booked your flight to Paris.
In this post, we go through a set of bestpractices for using ML to create a bot that will delight your customers by accurately understanding them. The bestpractices listed in the following sections can support you in building a bot that will give your customers a great user experience and work well for your use case.
This two-part series explores bestpractices for building generative AI applications using Amazon Bedrock Agents. It’s also a bestpractice to collect any extra information that would be shared with the agent in a production system. Implement citation mechanisms to reference source documents in responses.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. Virginia) AWS Region. The following diagram illustrates the solution architecture.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
Its agent for software development can solve complex tasks that go beyond code suggestions, such as building entire application features, refactoring code, or generating documentation. In this session, learn bestpractices for effectively adopting generative AI in your organization. Hear from Availity on how 1.5
BestPractices for Onboarding New Tenants to the ISP Network As an Internet Service Provider (ISP) you know it’s not easy to acquire tenants (clients or subscribers who rent or lease Internet services from you). It’s critical to actively think about the entire customer journey, define it, map it, and document it.”
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. AnalyzeDocument Signatures is a feature within Amazon Textract that offers the ability to automatically detect signatures on any document. Lastly, we share some bestpractices for using this feature.
We cover the key scenarios where scaling to zero is beneficial, provide bestpractices for optimizing scale-up time, and walk through the step-by-step process of implementing this functionality. We also discuss bestpractices for implementation and strategies to mitigate potential drawbacks.
In this post, we discuss bestpractices for working with FMEval in ground truth curation and metric interpretation for evaluating question answering applications for factual knowledge and quality. We used Amazon’s Q2 2023 10Q report as the source document from the SEC’s public EDGAR dataset to create 10 question-answer-fact triplets.
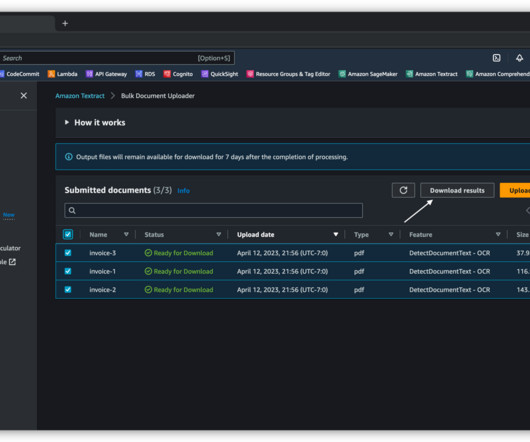
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. In this post, we walk through when and how to use the Amazon Textract Bulk Document Uploader to evaluate how Amazon Textract performs on your documents.
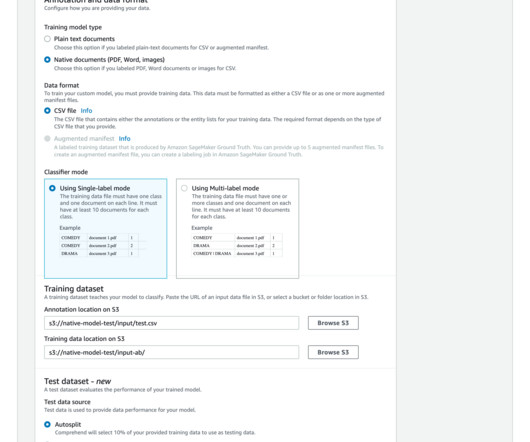
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
In this post, we explore the bestpractices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock. However, achieving optimal performance with fine-tuning requires effort and adherence to bestpractices.
When using your data source, you might want better visibility into the document processing lifecycle during data source sync jobs. They could include knowing the status of each document you attempted to crawl and index, as well as being able to troubleshoot why certain documents were not returned with the expected answers.
In this post, we seek to address this growing need by offering clear, actionable guidelines and bestpractices on when to use each approach, helping you make informed decisions that align with your unique requirements and objectives. Under Knowledge Bases, choose Create. Specify a chunking strategy. Choose Next.
Site monitors conduct on-site visits, interview personnel, and verify documentation to assess adherence to protocols and regulatory requirements. However, this process can be time-consuming and prone to errors, particularly when dealing with extensive audio recordings and voluminous documentation.
In this post, we provide an overview of the Meta Llama 3 models available on AWS at the time of writing, and share bestpractices on developing Text-to-SQL use cases using Meta Llama 3 models. All the code used in this post is publicly available in the accompanying Github repository.
Just like any forum, the online world has its own codes, bestpractices, and of course, language – one that is imperative to know in our digital age. Regardless of the channels and formats you use, here are a handful of bestpractices to communicate effectively with your clients online. Do you speak Internet?
By documenting the specific model versions, fine-tuning parameters, and prompt engineering techniques employed, teams can better understand the factors contributing to their AI systems performance. This record-keeping allows developers and researchers to maintain consistency, reproduce results, and iterate on their work effectively.
The following bestpractices will help you establish standardized benchmarking when comparing different foundation models. Document your evaluation configuration and parameters for reproducibility. Document any modifications made based on evaluation insights. decode('utf-8') for line in content.strip().split('n'):
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. Who are the data stewards for my proprietary database sources?
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content