This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we provide bestpractices to maximize the value of SageMaker HyperPod task governance and make the administration and data science experiences seamless. As a bestpractice, set the fair-share weight higher for teams that will require access to capacity sooner than other teams.
From essentials like average handle time to broader metrics such as call center service levels , there are dozens of metrics that call center leaders and QA teams must stay on top of, and they all provide visibility into some aspect of performance. Kaye Chapman @kayejchapman. First contact resolution (FCR) measures might be…”.
In this post, we share comprehensive bestpractices and scientific insights for fine-tuning Meta Llama 3.2 The models were evaluated using the SQuAD F1 score metric , which measures the word-level overlap between generated responses and reference answers. Research Engineer at AWS Bedrock. We fine-tuned both Meta Llama 3.2
This approach allows organizations to assess their AI models effectiveness using pre-defined metrics, making sure that the technology aligns with their specific needs and objectives. Curated judge models : Amazon Bedrock provides pre-selected, high-quality evaluation models with optimized prompt engineering for accurate assessments.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. Security – The solution uses AWS services and adheres to AWS Cloud Security bestpractices so your data remains within your AWS account.
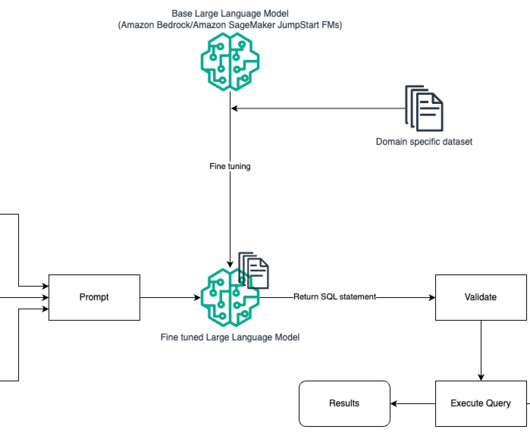
In this post, we provide an introduction to text to SQL (Text2SQL) and explore use cases, challenges, design patterns, and bestpractices. Effective prompt engineering is key to developing natural language to SQL systems. Prompt engineering – The model is trained to complete prompts designed to prompt the target SQL syntax.
For automatic model evaluation jobs, you can either use built-in datasets across three predefined metrics (accuracy, robustness, toxicity) or bring your own datasets. Regular evaluations allow you to adjust and steer the AI’s behavior based on feedback and performance metrics.
By documenting the specific model versions, fine-tuning parameters, and prompt engineering techniques employed, teams can better understand the factors contributing to their AI systems performance. Evaluation algorithm Computes evaluation metrics to model outputs. Different algorithms have different metrics to be specified.
The challenge: Resolving application problems before they impact customers New Relic’s 2024 Observability Forecast highlights three key operational challenges: Tool and context switching – Engineers use multiple monitoring tools, support desks, and documentation systems. The following diagram illustrates the workflow.
This post focuses on evaluating and interpreting metrics using FMEval for question answering in a generative AI application. FMEval is a comprehensive evaluation suite from Amazon SageMaker Clarify , providing standardized implementations of metrics to assess quality and responsibility. Question Answer Fact Who is Andrew R.
At CSM Practice, we are following the Covid-19 situation and its impact on customer success closely. And as we collectively work together to lower the curve, we would like to provide some guidance based on bestpractices to smoothen customer journeys during the Coronavirus pandemic. 3. Adjust Your Metrics and KPIs.
However, when transitioning between different foundation models, the prompts created for your original model might not be as performant for Amazon Nova models without prompt engineering and optimization. We also discuss the lessons learned and bestpractices for you to implement the solution for your real-world use cases.
It also helps achieve data, project, and team isolation while supporting software development lifecycle bestpractices. The DS uses SageMaker Training jobs to generate metrics captured by , selects a candidate model, and registers the model version inside the shared model group in their local model registry.
We cover the key scenarios where scaling to zero is beneficial, provide bestpractices for optimizing scale-up time, and walk through the step-by-step process of implementing this functionality. We also discuss bestpractices for implementation and strategies to mitigate potential drawbacks.
Although automated metrics are fast and cost-effective, they can only evaluate the correctness of an AI response, without capturing other evaluation dimensions or providing explanations of why an answer is problematic. Human evaluation, although thorough, is time-consuming and expensive at scale.
That’s why we’ve compiled four bestpractices to help you meet your sales goals and keep your team busy. Our next lead generation bestpractice is customer service. Our next bestpractice in how to generate leads is to focus on your website. Case Study: B2B Lead Generation & Cold Calling.
You liked the overall experience and now want to deploy the bot in your production environment, but aren’t sure about bestpractices for Amazon Lex. In this post, we review the bestpractices for developing and deploying Amazon Lex bots, enabling you to streamline the end-to-end bot lifecycle and optimize your operations.
In this post, we explore the bestpractices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock. We also provide insights on how to achieve optimal results for different dataset sizes and use cases, backed by experimental data and performance metrics. Sonnet across various tasks.
Based on our experiments using best-in-class supervised learning algorithms available in AutoGluon , we arrived at a 3,000 sample size for the training dataset for each category to attain an accuracy of 90%. Where discrete outcomes with labeled data exist, standard ML methods such as precision, recall, or other classic ML metrics can be used.
Workforce Management 2025 Call Center Productivity Guide: Must-Have Metrics and Key Success Strategies Share Achieving maximum call center productivity is anything but simple. Revenue per Agent: This metric measures the revenue generated by each agent. For many leaders, it might often feel like a high-wire act.
In this post, we seek to address this growing need by offering clear, actionable guidelines and bestpractices on when to use each approach, helping you make informed decisions that align with your unique requirements and objectives. To do so, we create a knowledge base. For Job name , enter a name for the fine-tuning job.
The ability to quickly retrieve and analyze session data empowers developers to optimize their applications based on actual usage patterns and performance metrics. Example use case To demonstrate the power and simplicity of Session Management APIs, lets walk through a practical example of building a shoe shopping assistant.
Metrics, Measure, and Monitor – Make sure your metrics and associated goals are clear and concise while aligning with efficiency and effectiveness. Make each metric public and ensure everyone knows why that metric is measured. Jeff Greenfield is the co-founder and chief operating officer of C3 Metrics.
Leave the session inspired to bring Amazon Q Apps to supercharge your teams’ productivity engines. In this session, learn bestpractices for effectively adopting generative AI in your organization. This session provides practical steps to streamline your model selection process, providing high-quality, reliable AI deployments.
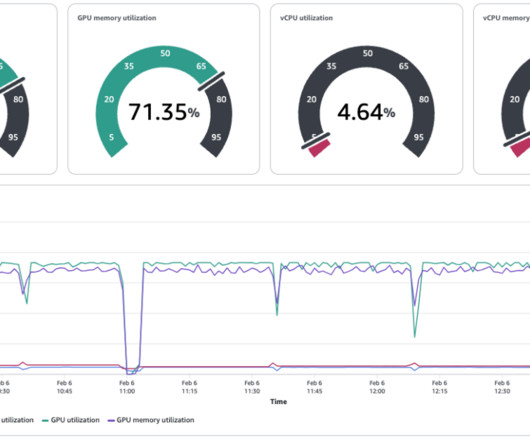
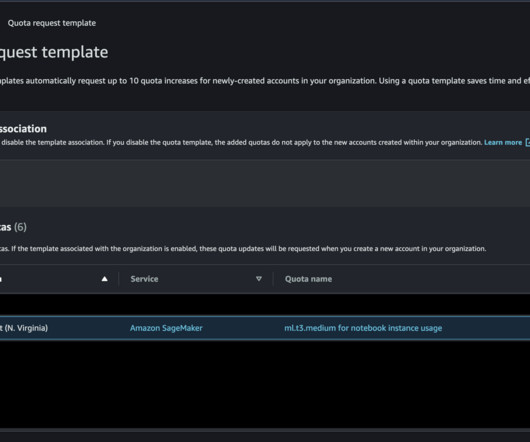
In addition, they can view near real-time utilization metrics and create Amazon CloudWatch metrics to view and programmatically query SageMaker quotas. This architecture includes the following workflow: A CloudWatch metric monitors the usage of the resource. Choose Select metric. Select the metric you want to monitor.
Or, will my business’s growth come from building a product that is in its very nature designed to grow and attract customers (thus, reducing the need for sales teams and costly go-to-market engines)? Here are some of the lessons I’ve learned as a CEO and my advice on 5 product-led growth bestpractices that you can use in your own business.
In this article, we explore bestpractices of Agile for remote teams. For example, a 2002 GitLab survey has shown that 82% of remote engineers name communication as the most challenging part of their work. Even the small wins will boost the teams morale and cheer your engineers up.
Youre dealing with metrics and KPIs, sure, but also human emotions, tech stacks, and rapidly evolving customer expectations. Monitoring call center performance metrics is crucial for ensuring smooth customer interactions and motivated agents. Its part art, part science. But flip that scenario.
Youre dealing with metrics and KPIs, sure, but also human emotions, tech stacks, and rapidly evolving customer expectations. Monitoring call center performance metrics is crucial for ensuring smooth customer interactions and motivated agents. Its part art, part science. But flip that scenario.
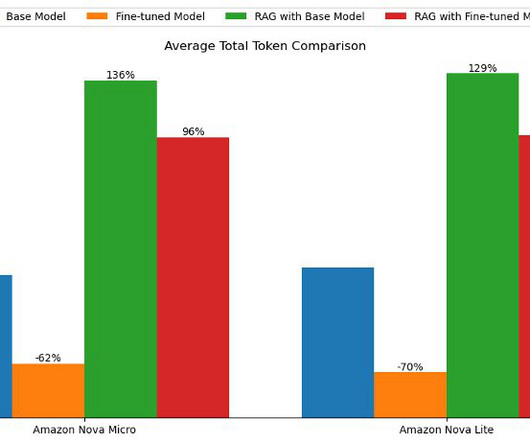
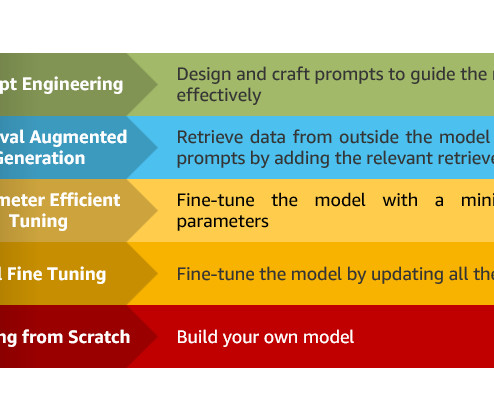
In particular, we provide practicalbestpractices for different customization scenarios, including training models from scratch, fine-tuning with additional data using full or parameter-efficient techniques, Retrieval Augmented Generation (RAG), and prompt engineering.
Proactive quality control is the engine that powers this positive cycle. Regular Meetings: Conduct regular business reviews to track progress on action plans, discuss performance metrics, and address any roadblocks that may arise. Tie rewards to specific, measurable quality metrics.
Because this is an emerging area, bestpractices, practical guidance, and design patterns are difficult to find in an easily consumable basis. This integration makes sure enterprises can take advantage of the full power of generative AI while adhering to bestpractices in operational excellence.
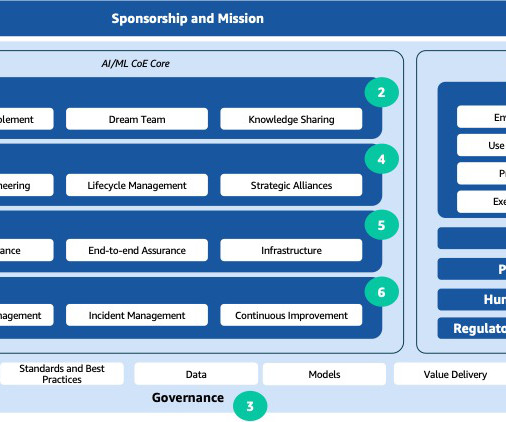
They establish and enforce bestpractices encompassing design, development, processes, and governance operations, thereby mitigating risks and making sure robust business, technical, and governance frameworks are consistently upheld. Platform – A central platform such as Amazon SageMaker for creation, training, and deployment.
Now more than ever, organizations need to actively manage the Average-Speed-of-Answer (ASA) metric. Older citizens, the unhealthy, and those in low-income areas have always been targets for social engineering. Despite the pandemic, customers have retained the expectation that if they call you, you’ll be there for them.
A/B testing is used in scenarios where closed loop feedback can directly tie model outputs to downstream business metrics. This feedback is then used to determine the statistical significance of changing from one model to another, helping you select the best model through live production testing.
Data engineering development is done using AWS Glue Studio. Code artifacts for both data science activities and data engineering activities are stored in Git. Deployment times stretched for months and required a team of three system engineers and four ML engineers to keep everything running smoothly.
Amazon Q Business only provides metric information that you can use to monitor your data source sync jobs. As a security bestpractice, storing the client application data in Secrets Manager is recommended. You must create and run the crawler that determines the documents your data source indexes.
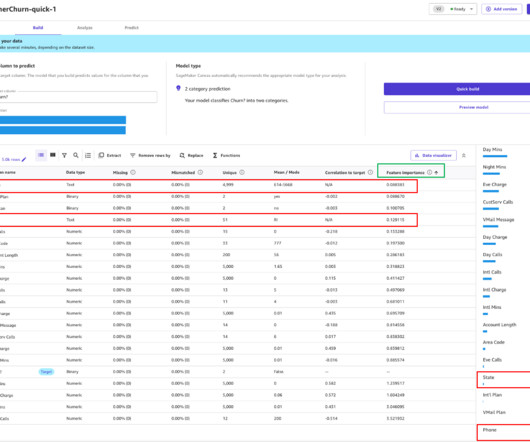
It also enables you to evaluate the models using advanced metrics as if you were a data scientist. In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab. The F1 score provides a balanced evaluation of the model’s performance.
Prompt engineering is typically an iterative process, and teams experiment with different techniques and prompt structures until they reach their target outcomes. Model monitoring – The model monitoring service allows tenants to evaluate model performance against predefined metrics. They’re illustrated in the following figure.
There are unique considerations when engineering generative AI workloads through a resilience lens. If you’re performing prompt engineering, you should persist your prompts to a reliable data store. Make sure to use bestpractices for rate limiting, backoff and retry, and load shedding.
Additionally, the complexity increases due to the presence of synonyms for columns and internal metrics available. You can add additional information such as which SQL engine should be used to generate the SQL queries. The produced query should be functional, efficient, and adhere to bestpractices in SQL query optimization.
Moreover, there is a potential danger of bestpractices of an inherent convergence. If we all use the same bestpractices, then we are converging on what everyone else does. When we worked with the water utility years ago, we learned that an expensive part of their costs was the field engineer labor.
Additionally, evaluation can identify potential biases, hallucinations, inconsistencies, or factual errors that may arise from the integration of external sources or from sub-optimal prompt engineering. This makes it difficult to apply standard evaluation metrics like BERTScore ( Zhang et al.
Recall@5 is a specific metric used in information retrieval evaluation, including in the BEIR benchmark. Breanne holds a Bachelor of Science in Computer Engineering from University of Illinois at Urbana Champaign. This example uses ml.g5.xlarge, xlarge, but you might need to adjust this based on your specific needs.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content