This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
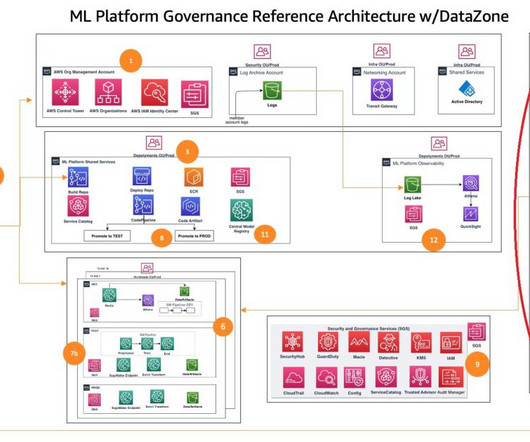
This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
The solution integrates large language models (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. Run the script init-script.bash : chmod u+x init-script.bash./init-script.bash
Amazon Comprehend is a fully managed service that can perform NLP tasks like custom entity recognition, topic modelling, sentiment analysis and more to extract insights from data without the need of any prior ML experience. Build your training script for the Hugging Face SageMaker estimator. return tokenized_dataset. to(device).
We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw. For example, to use the RedPajama dataset, use the following command: wget [link] python nemo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. For more information about prerequisites, see Get Started with Data Wrangler.
Twilio enables companies to use communications and data to add intelligence and security to every step of the customer journey, from sales and marketing to growth and customer service, and many more engagement use cases in a flexible, programmatic way. Twilio needed to implement an MLOps pipeline that queried data from PrestoDB.
However, as a new product in a new space for Amazon, Amp needed more relevant data to inform their decision-making process. Part 1 shows how data was collected and processed using the data and analytics platform, and Part 2 shows how the data was used to create show recommendations using Amazon SageMaker , a fully managed ML service.
They serve as a bridge between IT and other business functions, making data-driven recommendations that meet business requirements and improve processes while optimizing costs. Business analysts must own the call tracking systems and actively leverage data to tune the call center policies and procedures. Andrew Tillery. MAPCommInc.
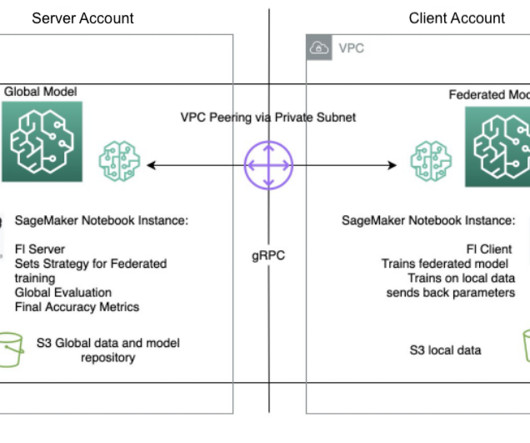
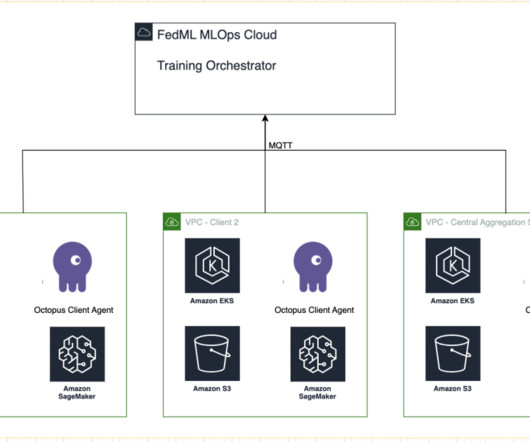
Machine learning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed. What is federated learning?
Data-driven decisions are essential in businesses to diminish the chances of errors, and online data analyst courses will teach you how to interpret data precisely. There is where data analysis comes in, you can use the data your company has, and key performance indicators (KPIs) to indicate what path you should follow.
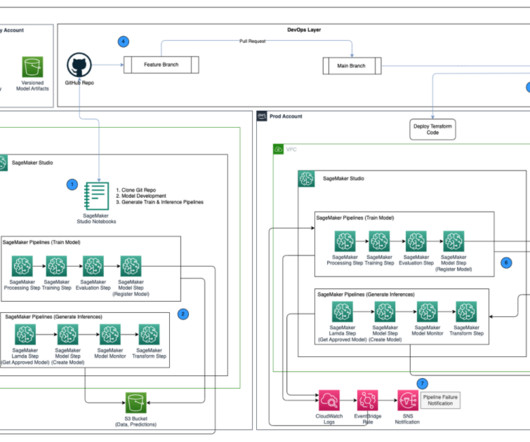
This enables data scientists to quickly build and iterate on ML models, and empowers ML engineers to run through continuous integration and continuous delivery (CI/CD) ML pipelines faster, decreasing time to production for models. You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices.
Cloud computing has gained significant momentum as an effective way to store, manage, and process data without the constraints of physical servers. In the same spirit, cloud computing is often the backbone of AI applications, advanced analytics, and data-heavy systems. This keeps performance stable and user experiences positive.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
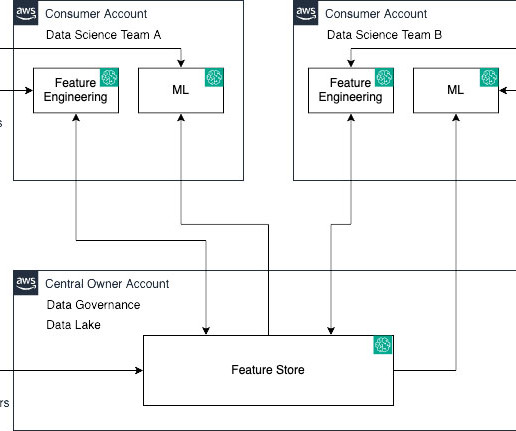
Today, companies are establishing feature stores to provide a central repository to scale ML development across business units and data science teams. The offline store is an append-only store and can be used to store and access historical feature data. Table formats provide a way to abstract data files as a table.
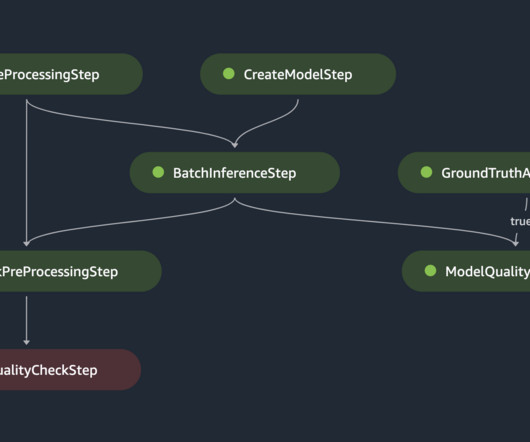
Homomorphic encryption is a new approach to encryption that allows computations and analytical functions to be run on encrypted data, without first having to decrypt it, in order to preserve privacy in cases where you have a policy that states data should never be decrypted. The following figure shows both versions of these patterns.
Today, CXA encompasses various technologies such as AI, machine learning, and bigdata analytics to provide personalized and efficient customer experiences. Personalization: Using AI and machine learning, CXA systems can analyze customer data to provide personalized experiences.
With increased access to data, ML has the potential to provide unparalleled business insights and opportunities. To address this issue, federated learning (FL) is a decentralized and collaborative ML training technique that offers data privacy while maintaining accuracy and fidelity.
After downloading the latest Neuron NeMo package, use the provided neox and pythia pre-training and fine-tuning scripts with optimized hyper-parameters and execute the following for a four node training. Dr. Huan works on AI and Data Science. Each trn1.32xl has 16 accelerators with two workers per accelerator.
We use the custom terminology dictionary to compile frequently used terms within video transcription scripts. Max Goff is a data scientist/data engineer with over 30 years of software development experience. Yaoqi Zhang is a Senior BigData Engineer at Mission Cloud. Here’s an example. She received her Ph.D.
This architecture design represents a multi-account strategy where ML models are built, trained, and registered in a central model registry within a data science development account (which has more controls than a typical application development account).
The one-size-fit-all script no longer cuts it. Technology is also creating new opportunities for contact centers to not only better serve customers but also gain deep insights through BigData. With analytics, contact centers can leverage their data to see trends, understand preferences and even predict future requirements.
We live in an era of bigdata, AI, and automation, and the trends that matter in CX this year begin with the abilities – and pain points – ushered in by this technology. For example, bigdata makes things like hyper-personalized customer service possible, but it also puts enormous stress on data security.
Developers usually test their processing and training scripts locally, but the pipelines themselves are typically tested in the cloud. One of the main drivers for new innovations and applications in ML is the availability and amount of data along with cheaper compute options. Model training and tuning. Model evaluation.
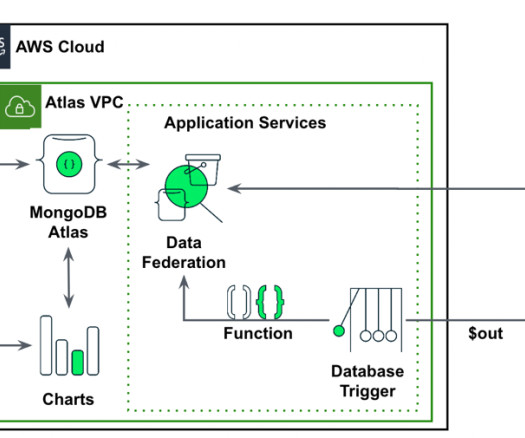
By harnessing the transformative potential of MongoDB’s native time series data capabilities and integrating it with the power of Amazon SageMaker Canvas , organizations can overcome these challenges and unlock new levels of agility.
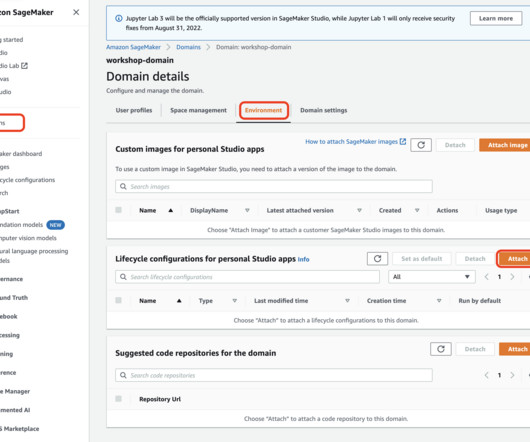
Studio provides all the tools you need to take your models from data preparation to experimentation to production while boosting your productivity. Alternatively to using notebook instances or shell scripts, you can use the Studio Image Build CLI to work with Docker in Studio.
Who needs a cross-account feature store Organizations need to securely share features across teams to build accurate ML models, while preventing unauthorized access to sensitive data. Their task is to construct and oversee efficient data pipelines. This provides an audit trail required for governance and compliance.
Whether you’re seeking to generate content, analyze data, or explore innovative ideas, this integration empowers you to do it all without leaving the familiar Slack environment. About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice.
Amazon SageMaker offers several ways to run distributed data processing jobs with Apache Spark, a popular distributed computing framework for bigdata processing. install-scripts chmod +x install-history-server.sh./install-history-server.sh script and attach it to an existing SageMaker Studio domain.
To keep pace with new products, a new model was produced each month using the latest training data. Data augmentation for model training and manually managing the complete end-to-end training cycle was adding significant overhead. For certain SKUs, we augmented data to encompass a broader range of environmental conditions.
From understanding the fundamentals of call center predictive analytics to diving into real-world call center analytics use cases, this comprehensive guide covers everything you need to know about analyzing call center data. Predictive Analytics: Uses historical data to forecast future events like call volumes or customer churn.
Amazon CodeWhisperer currently supports Python, Java, JavaScript, TypeScript, C#, Go, Rust, PHP, Ruby, Kotlin, C, C++, Shell scripting, SQL, and Scala. times more energy efficient than the median of surveyed US enterprise data centers and up to 5 times more energy efficient than the average European enterprise data center.
Refer to notebook examples for SageMaker algorithms – SageMaker provides a suite of built-in algorithms to help data scientists and ML practitioners get started with training and deploying ML models quickly. The input directory should look like the following code if the training data contains two images.
Amazon Q can help you get fast, relevant answers to pressing questions, solve problems, generate content, and take actions using the data and expertise found in your company’s information repositories and enterprise systems. You can also find the script on the GitHub repo. Amazon Q uses the chat_sync API to carry out the conversation.
With an expanding network of users, Trumid’s AI and Data Strategy team partnered with the AWS Machine Learning Solutions Lab. Real-world data is complex and interconnected, and often contains network structures. Traditional ML algorithms require data to be organized as tables or sequences. Benefits of graph machine learning.
Refer to notebook examples for SageMaker algorithms – SageMaker provides a suite of built-in algorithms to help data scientists and ML practitioners get started with training and deploying ML models quickly. We first fetch any additional packages, as well as scripts to handle training and inference for the selected task.
Accordingly, I expect to see a range of new solutions see the light of day in 2018; solutions that bring the old solutions like Interactive Voice Response (cue the robotic ‘press 1 for English’ script) into the 21 st century, on a channel people actually like to use.
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. RAG is a popular technique that combines the use of private data with large language models (LLMs). Choose Next.
Refer to notebook examples for SageMaker algorithms – SageMaker provides a suite of built-in algorithms to help data scientists and ML practitioners get started with training and deploying ML models quickly. We first fetch any additional packages, as well as scripts to handle training and inference for the selected task.
These customers need to balance governance, security, and compliance against the need for machine learning (ML) teams to quickly access their data science environments in a secure manner. The script performs the required API calls using the AWS Command Line Interface (AWS CLI) and the previously configured parameters and profiles.
Security is a big-data problem. We showcase how SophosAI uses Amazon SageMaker distributed training with terabytes of data to train a powerful lightweight XGBoost (Extreme Gradient Boosting) model. SageMaker automatically splits the data across nodes, aggregates the results across peer nodes, and generates a single model.
As data scientists iterate through that process, they need a reliable method to easily track experiments to understand how each model version was built and how it performed. When data scientists approach a new ML problem, they have to answer many different questions, from data availability to how they will measure model performance.
In the artificial intelligence (AI) space, athenahealth uses data science and machine learning (ML) to accelerate business processes and provide recommendations, predictions, and insights across multiple services. Each project maintained detailed documentation that outlined how each script was used to build the final model.
Retently’s reporting tool enables organizations to analyze their data and act on the received customer feedback. TechSee’s technology combines AI with deep machine learning, proprietary algorithms, and BigData to deliver a scalable cognitive system that becomes smarter with every customer support interaction.
We are also seeing the influx of bigdata and the switch to mobile. These are the innate functional limitations of every non-human "system" Namely, no matter how advanced a piece of customer service software is, there are always situations in which its script is not able to make certain leaps that biology is capable of.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content