This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Predictive Analytics takes this a step further by analyzing bigdata to anticipate customer needs, streamline workflows, and deliver personalized responses. These measures ensure customer data is protected, building trust and maintaining the integrity of customer relationships.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise. latest USER root RUN dnf install python3.11
Customer Science to me in the integration between a number of existing disciplines; Behavioral Science, Technology (AI) and Bigdata. We often say there is a big difference between what Customers say and what they do. Use Customer Science to document how your efforts work or don’t. Key Takeaways.
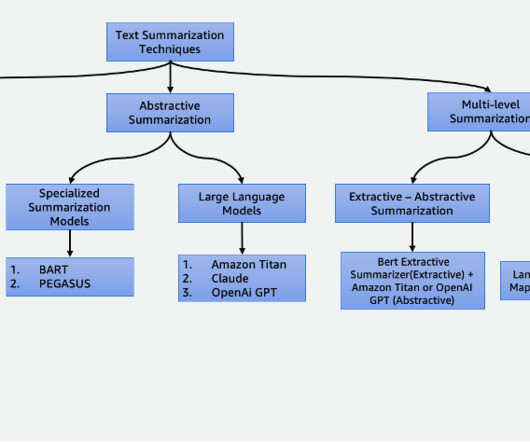
Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks. These models take the extracted summaries as input and produce abstractive summaries that capture the essence of the original document while ensuring readability and coherence.
A recent Calabrio research study of more than 1,000 C-Suite executives has revealed leaders are missing a key data stream – voice of the customer data. Download the report to learn how executives can find and use VoC data to make more informed business decisions.
Site monitors conduct on-site visits, interview personnel, and verify documentation to assess adherence to protocols and regulatory requirements. However, this process can be time-consuming and prone to errors, particularly when dealing with extensive audio recordings and voluminous documentation.
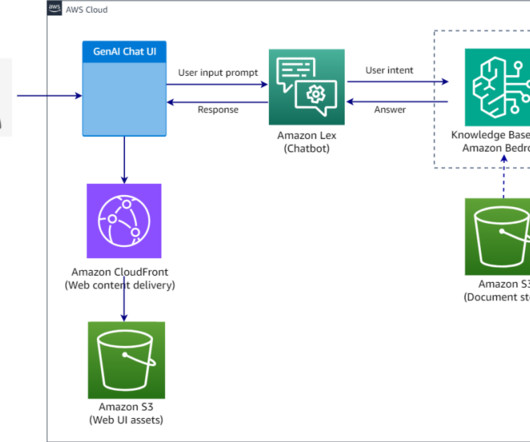
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. There might also be costs associated with using Google services.
It aims to boost team efficiency by answering complex technical queries across the machine learning operations (MLOps) lifecycle, drawing from a comprehensive knowledge base that includes environment documentation, AI and data science expertise, and Python code generation.
In Part 1 of this series, we discussed intelligent document processing (IDP), and how IDP can accelerate claims processing use cases in the insurance industry. We discussed how we can use AWS AI services to accurately categorize claims documents along with supporting documents. Part 1: Classification and extraction of documents.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
The Product Stewardship department is responsible for managing a large collection of regulatory compliance documents. Example questions might be “What are the restrictions for CMR substances?”, “How long do I need to keep the documents related to a toluene sale?”, or “What is the reach characterization ratio and how do I calculate it?”
After the agent receives documents from the knowledge base and responses from tool APIs, it consolidates the information to feed it to the large language model (LLM) and generate the final response. About the Author Carlos Contreras is a Senior BigData and Generative AI Architect, at Amazon Web Services.
Organizations are similarly challenged by the overflow of BigData from transactions, social media, records, interactions, documents, and sensors. But the ability to correlate and link all of this data, and derive meaningful insights, can offer a great opportunity.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
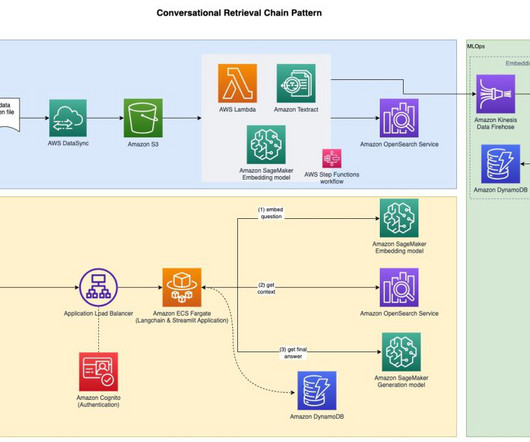
Overview of RAG The RAG pattern lets you retrieve knowledge from external sources, such as PDF documents, wiki articles, or call transcripts, and then use that knowledge to augment the instruction prompt sent to the LLM. Before you can start question and answering, embed the reference documents, as shown in the next section.
Keep the data source location as the same AWS account and choose Browse S3. Select the S3 bucket where you uploaded the Amazon shareholder documents and choose Choose. Select the embedding model to vectorize the documents. Choose Sync to index the documents. Choose Next. Choose Create bot.
Refer to the Python documentation for an example. He helps customers implement bigdata and analytics solutions. Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice. He helps customers implement bigdata, machine learning, and analytics solutions.
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. RAG is a popular technique that combines the use of private data with large language models (LLMs). txt) Markdown (.md)
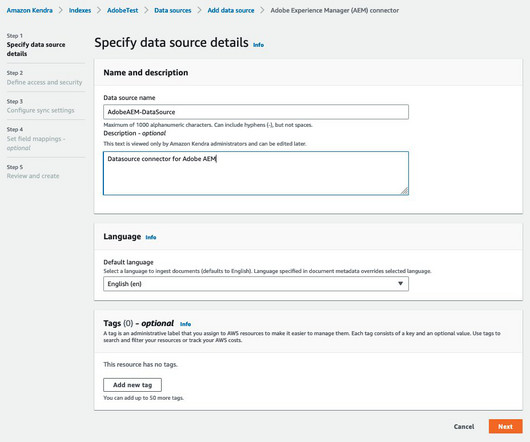
The connector also ingests the access control list (ACL) information for each document. Solution overview In our solution, we configure AEM as a data source for an Amazon Kendra search index using the Amazon Kendra AEM connector. The connector also indexes the Access Control List (ACL) information for each message and document.
Amazon Q returns the response as a JSON object (detailed in the Amazon Q documentation ). sourceAttributions – The source documents used to generate the conversation response. In Retrieval Augmentation Generation (RAG), this always refers to one or more documents from enterprise knowledge bases that are indexed in Amazon Q.
An agile approach brings the full power of bigdata analytics to bear on customer success. An agile approach to CS management can be broken down into seven steps: Document your client’s requirements. Document Your Client’s Requirements. Standardize your documentation approach by developing a requirements template.
Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured data accounts for over 80% of all business data today. This includes formats like emails, PDFs, scanned documents, images, audio, video, and more.
Use group sharing engines to share documents with strategies and knowledge across departments. Data can be insightful to all of the roles HR takes on in facilitating the company’s CX goals. 60% of companies are now investing in bigdata and analytics to make HR more data driven. —@tcrawford.
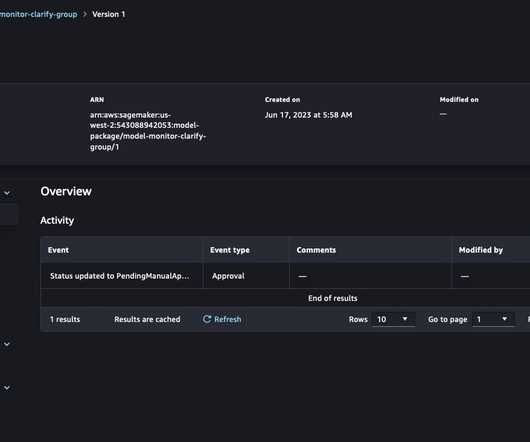
Amazon SageMaker Model Cards enable you to standardize how models are documented, thereby achieving visibility into the lifecycle of a model, from designing, building, training, and evaluation. SageMaker model cards document critical details about your ML models in a single place for streamlined governance and reporting.
With faster model training times, you can focus on understanding your data and analyzing the impact of the data, and achieve effective business outcomes. You can learn more on the SageMaker Canvas product page and the documentation. His knowledge ranges from application architecture to bigdata, analytics, and machine learning.
One of the tools available as part of the ML governance is Amazon SageMaker Model Cards , which has the capability to create a single source of truth for model information by centralizing and standardizing documentation throughout the model lifecycle. They provide a fact sheet of the model that is important for model governance.
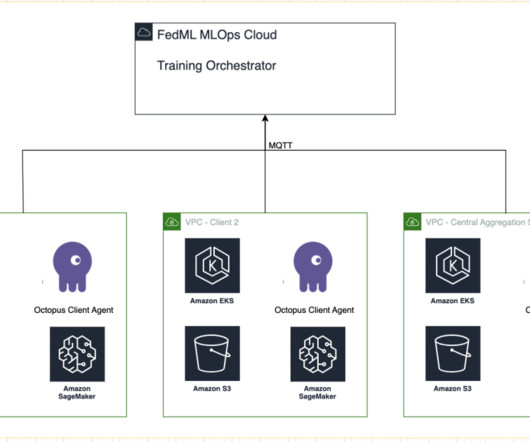
Create an MLOps deployment package As a part of the FedML documentation, we need to create the client and server packages, which the MLOps platform will distribute to the server and clients to begin training. He entered the bigdata space in 2013 and continues to explore that area.
View this document on the publisher’s website. Advancements in artificial intelligence (AI), machine learning, BigData analytics, and mobility are all driving contact center innovation. This BigData application is intended to track, evaluate, and measure activities and sentiment at every step of the customer journey.
Amazon Kendra supports a variety of document formats , such as Microsoft Word, PDF, and text from various data sources. In this post, we focus on extending the document support in Amazon Kendra to make images searchable by their displayed content. This means you can manipulate and ingest your data as needed.
You can create a support page with FAQs, guides, product documentation, video tutorials, and more. She writes about B2B Marketing, BigData, Artificial Intelligence, and other technological innovations. It assists you to re-prioritize your support tickets based on the severity of customer issues, and their complexity.
For example, a use case that’s been moved from the QA stage to pre-production could be rejected and sent back to the development stage for rework because of missing documentation related to meeting certain regulatory controls. These stages are applicable to both use case and model stages.
We live in an era of bigdata, AI, and automation, and the trends that matter in CX this year begin with the abilities – and pain points – ushered in by this technology. For example, bigdata makes things like hyper-personalized customer service possible, but it also puts enormous stress on data security.
Large language models (LLMs) can be used to analyze complex documents and provide summaries and answers to questions. The post Domain-adaptation Fine-tuning of Foundation Models in Amazon SageMaker JumpStart on Financial data describes how to fine-tune an LLM using your own dataset.
Enhancing documentation and support: Provide comprehensive documentation and support resources to guide external clients through the BYOM process, including best practices for model preparation, integration, and optimization. He is passionate about machine learning engineering, distributed systems, and big-data technologies.
Complete the following steps to set up the solution: Create the knowledge base in OpenSearch Service for the RAG framework: def add_documnets(self,index_name: str,file_name:str): documents = JSONLoader(file_path=file_name, jq_schema='.', About the Authors Sanjeeb Panda is a Data and ML engineer at Amazon.
Imagine the possibilities: Quick and efficient brainstorming sessions, real-time ideation, and even drafting documents or code snippets—all powered by the latest advancements in AI. About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice.
document signing. Looking back on a year in review, we’ve made four new patent submissions beyond the seven current patents we hold in the CX technologies, Visual Computing, Augmented Reality, and BigData space. product or service demos , and. A Year of Consideration for the Environment. Our world, our home is important to us.
View this document on the publisher’s website. BigData solutions: Data repositories are an essential component of all AI and machine learning initiatives. In some cases, BigData solutions are new applications that were created or enhanced to collect and deliver the information needed to power an AI initiative.
In this post, we explore how companies can improve visibility into their models with centralized dashboards and detailed documentation of their models using two new features: SageMaker Model Cards and the SageMaker Model Dashboard. Both these features are available at no additional charge to SageMaker customers.
This pipeline could be a batch pipeline if you prepare contextual data in advance, or a low-latency pipeline if you’re incorporating new contextual data on the fly. In the batch case, there are a couple challenges compared to typical data pipelines. He entered the bigdata space in 2013 and continues to explore that area.
Real-time payments have well-documented advantages for both banks and customers, plus this type of technology is already a standard in many financial institutions. . Improving Products and Services Through BigData. In the past, the biggest challenge wasn’t the collection, but the analysis and interpretation of this data.
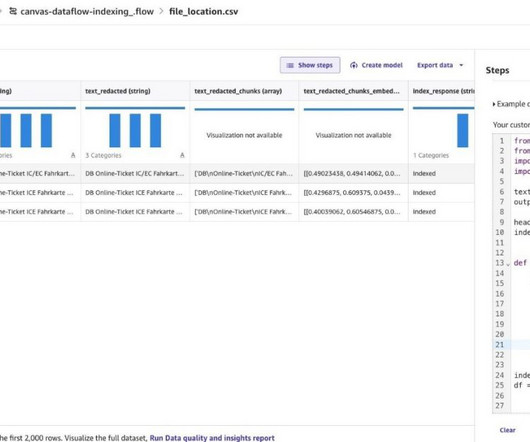
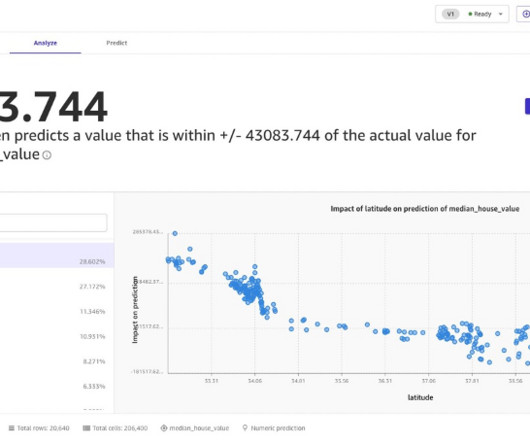
For the dataset in this use case, you should expect a “Very low quick-model score” high priority warning, and very low model efficacy on minority classes (charged off and current), indicating the need to clean up and balance the data. Refer to Canvas documentation to learn more about the data insights report.
Last Wednesday I was trying to look for a specific slide in one of the many PowerPoint presentations I have on my laptop, and kept stumbling across new presentations that I had completely forgotten I had there…well, there are tactics that I developed in the past years on how to organize my documents better, however I still from time to time get lost (..)
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content