This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For example, a use case that’s been moved from the QA stage to pre-production could be rejected and sent back to the development stage for rework because of missing documentation related to meeting certain regulatory controls. These stages are applicable to both use case and model stages.
After the agent receives documents from the knowledge base and responses from tool APIs, it consolidates the information to feed it to the large language model (LLM) and generate the final response. About the Author Carlos Contreras is a Senior BigData and Generative AI Architect, at Amazon Web Services.
This post focuses on evaluating and interpreting metrics using FMEval for question answering in a generative AI application. FMEval is a comprehensive evaluation suite from Amazon SageMaker Clarify , providing standardized implementations of metrics to assess quality and responsibility. Question Answer Fact Who is Andrew R.
In Part 1 of this series, we discussed intelligent document processing (IDP), and how IDP can accelerate claims processing use cases in the insurance industry. We discussed how we can use AWS AI services to accurately categorize claims documents along with supporting documents. Part 1: Classification and extraction of documents.
A recent Calabrio research study of more than 1,000 C-Suite executives has revealed leaders are missing a key data stream – voice of the customer data. Download the report to learn how executives can find and use VoC data to make more informed business decisions.
In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda. Overview of solution The first thing to consider is that different metrics require different computation considerations. The function invokes the modules.
They serve as a bridge between IT and other business functions, making data-driven recommendations that meet business requirements and improve processes while optimizing costs. That requires involvement in process design and improvement, workload planning and metric and KPI analysis. Kirk Chewning. kirkchewning.
An agile approach brings the full power of bigdata analytics to bear on customer success. An agile approach to CS management can be broken down into seven steps: Document your client’s requirements. Document Your Client’s Requirements. Standardize your documentation approach by developing a requirements template.
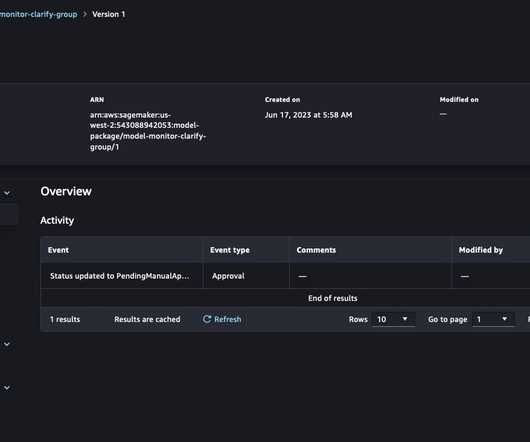
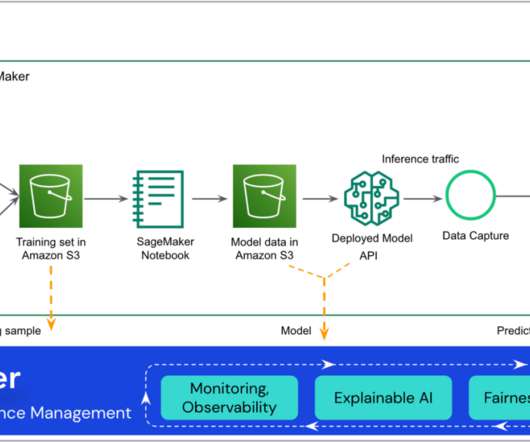
Amazon SageMaker Model Cards enable you to standardize how models are documented, thereby achieving visibility into the lifecycle of a model, from designing, building, training, and evaluation. SageMaker model cards document critical details about your ML models in a single place for streamlined governance and reporting.
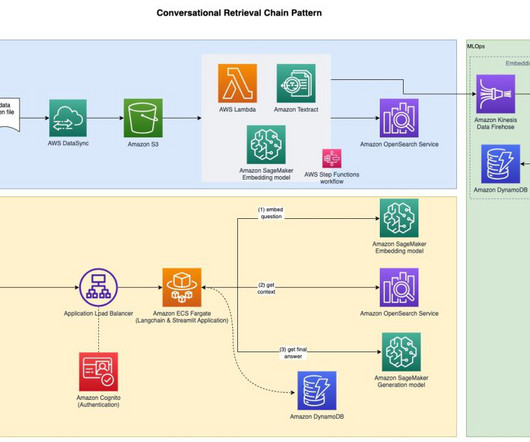
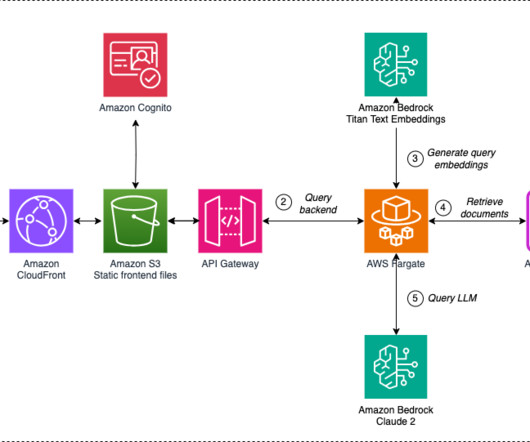
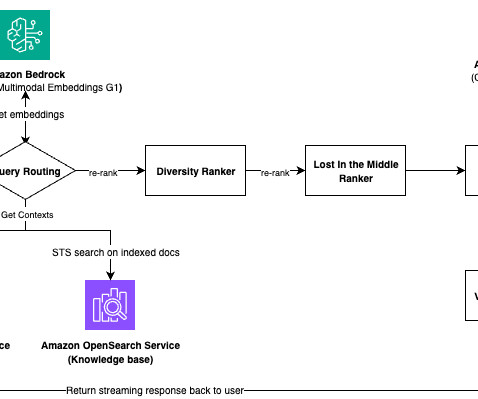
Overview of RAG The RAG pattern lets you retrieve knowledge from external sources, such as PDF documents, wiki articles, or call transcripts, and then use that knowledge to augment the instruction prompt sent to the LLM. Before you can start question and answering, embed the reference documents, as shown in the next section.
Use group sharing engines to share documents with strategies and knowledge across departments. Focus employee metrics more on CX enabling behaviors, less on survey ratings. Data can be insightful to all of the roles HR takes on in facilitating the company’s CX goals. —@tcrawford. —@EngageGXD.
The configuration tests include objective metrics such as F1 scores and Precision, and tune algorithm hyperparameters to produce optimal scores for these metrics. With faster model training times, you can focus on understanding your data and analyzing the impact of the data, and achieve effective business outcomes.
In this post, we explore how companies can improve visibility into their models with centralized dashboards and detailed documentation of their models using two new features: SageMaker Model Cards and the SageMaker Model Dashboard. With the SageMaker Python SDK, you can seamlessly update the Model card with evaluation metrics.
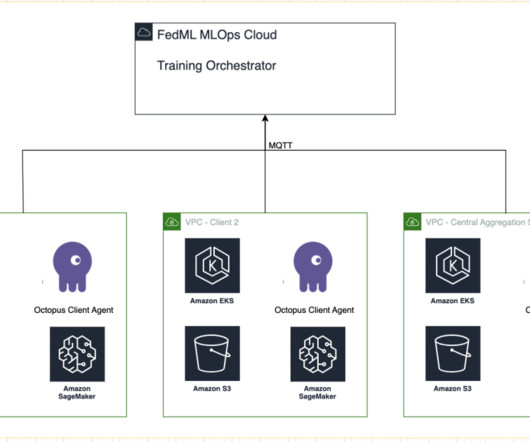
Create an MLOps deployment package As a part of the FedML documentation, we need to create the client and server packages, which the MLOps platform will distribute to the server and clients to begin training. He entered the bigdata space in 2013 and continues to explore that area.
This pipeline could be a batch pipeline if you prepare contextual data in advance, or a low-latency pipeline if you’re incorporating new contextual data on the fly. In the batch case, there are a couple challenges compared to typical data pipelines. He entered the bigdata space in 2013 and continues to explore that area.
We have also seen an uplift in almost all of our success metrics along the customer journey.”. Founded in 2015 and based in the US and Moldova, Retently helps businesses understand and interact with their customers using Net Promoter Score® (NPS®), a customer satisfaction metric and an alternative to traditional loyalty surveys.
Ask any contact center leader for data and you’ll likely end up with a hefty pile of metrics and analytics. Most companies can pull up copious documents, spreadsheets and reports with endless data and analytics. But too often, that data just sits there, gathering digital dust.
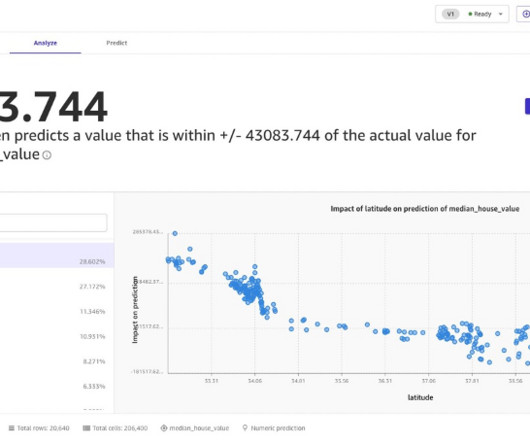
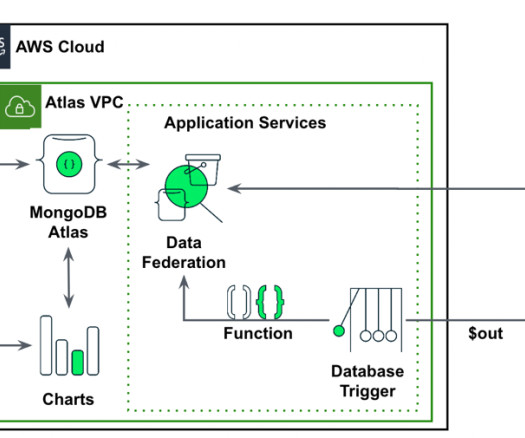
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. Next, choose Batch prediction, and click Select dataset.
The HyperparameterTuner class is used for running automatic model tuning to determine the set of hyperparameters that provide the best performance based on a user-defined metric threshold (for example, maximizing the AUC metric). This step registers the model only if the given user-defined metric threshold is met.
Real-time payments have well-documented advantages for both banks and customers, plus this type of technology is already a standard in many financial institutions. . Improving Products and Services Through BigData. In the past, the biggest challenge wasn’t the collection, but the analysis and interpretation of this data.
As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). We also illustrate how you can track your pipeline workflow and generate metrics and comparison charts.
The notebook also provides a sample dataset to run Fiddler’s explainability algorithms and as a baseline for monitoring metrics. To simplify this further, the code for this Lambda function is publicly available from Fiddler’s documentation site. He founded his own bigdata analytics consulting company, Branchbird, in 2012.
This includes unit tests for data preprocessing steps, integration tests for model training pipelines, and performance tests for evaluating model accuracy. Version Control for Data and Models : Use tools that support version control not just for code, but also for datasets and models.
In addition, products included in this document meet the threshold criteria for this category as determined by Constellation Research. Bigdata monitoring and data visualization . Tweet Digital Performance Management provides companies with the analytics to determine if their customer experience is optimized.
SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. Customers can also access offline store data using a Spark runtime and perform bigdata processing for ML feature analysis and feature engineering use cases. Table formats provide a way to abstract data files as a table.
Companies use advanced technologies like AI, machine learning, and bigdata to anticipate customer needs, optimize operations, and deliver customized experiences. Objective Data conversion for storage and retrieval. Scope Limited to data and documents. Efficiency and automation of existing workflows.
Gone went giant, word-packed binders of documents, and the faceless training, and mindless programming. Using BigData to Make Leadership Advances in the Workplace. While surveys that lead to these results are historically what we’ve had to understand engagement metrics, analytics are far more important.
Security is a big-data problem. Its widespread use and the general perception that such documents are airtight and static have lulled users into a false sense of security. It then chooses the hyperparameter values that result in a model that performs the best, as measured by a metric for the given ML task.
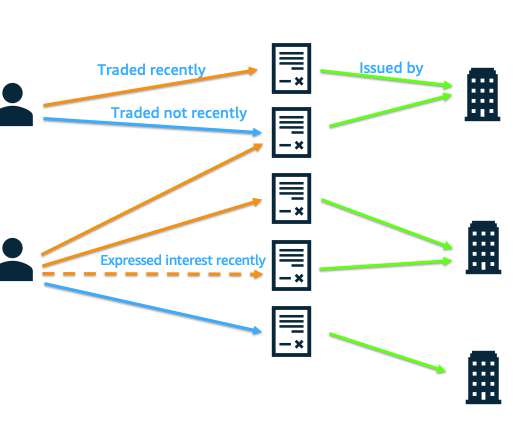
For detailed instructions on how to use the DGL-KE, refer to Training knowledge graph embeddings at scale with the Deep Graph Library and DGL-KE Documentation. With other standard metrics, the improvement ranged from 50–130%. Compute the top 100 highest scores for each trader. Packaging the solution as a scalable workflow.
” How about full endpoint documentation for all our products. But that’s not all… 2018 is going to be The Year of Data Analysis! Bigdata is here and we have plenty of it. We do this across PSTN, Mobile and SIP into and out of 63 countries worldwide, and as for bigdata… we have it!
In the artificial intelligence (AI) space, athenahealth uses data science and machine learning (ML) to accelerate business processes and provide recommendations, predictions, and insights across multiple services. Each project maintained detailed documentation that outlined how each script was used to build the final model.
Exploring, analyzing, interpreting, and finding trends in data is essential for businesses to achieve successful outcomes. Business analysts play a pivotal role in facilitating data-driven business decisions through activities such as the visualization of business metrics and the prediction of future events.
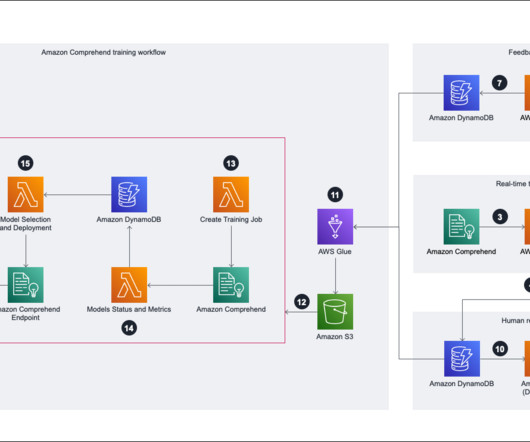
Amazon Comprehend is a fully managed and continuously trained natural language processing (NLP) service that can extract insight about the content of a document or text. We invoke a Lambda function to validate that the training data path exists, and then trigger an Amazon Comprehend training job.
SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously. SIMT describes processors that are able to operate on data vectors and arrays (as opposed to just scalars), and therefore handle bigdata workloads efficiently.
Despite significant advancements in bigdata and open source tools, niche Contact Center Business Intelligence providers are still wed to their own proprietary tools leaving them saddled with technical debt and an inability to innovate from within. or "Does Service Level include Calls abandoned?").
The MLflow Python SDK provides a convenient way to log metrics, runs, and artifacts, and it interfaces with the API resources hosted under the namespace /api/. More information can be found in the official MLflow documentation. At this point, the MLflow SDK only needs AWS credentials.
And you can look at various specific areas such as data analytics, bigdata, being able to study patterns within data, using artificial intelligence or using machine learning to actually gather up every customer interaction, and remember the original problem and the solution. This kind of thing really helps the agents.
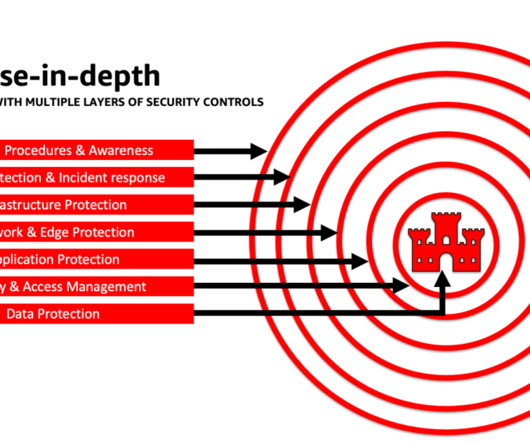
Accelerate your security and AI/ML learning with best practices guidance, training, and certification AWS also curates recommendations from Best Practices for Security, Identity, & Compliance and AWS Security Documentation to help you identify ways to secure your training, development, testing, and operational environments.
It provides a unified interface for logging parameters, code versions, metrics, and artifacts, making it easier to compare experiments and manage the model lifecycle. He is passionate about machine learning engineering, distributed systems, and big-data technologies. Similarly to Airflow, MLflow is also used just partially.
The Product Stewardship department is responsible for managing a large collection of regulatory compliance documents. Example questions might be “What are the restrictions for CMR substances?”, “How long do I need to keep the documents related to a toluene sale?”, or “What is the reach characterization ratio and how do I calculate it?”
When a query arises, analysts must engage in a time-consuming process of reaching out to subject matter experts (SMEs) and go through multiple policy documents containing standard operating procedures (SOPs) relevant to the query. They spend hours consulting SMEs and reviewing extensive policy documents.
The Need for Understanding Customer Desires in Customer Experience Management A predictive analytics solution collects huge amounts of data across different customer touchpoints and calculates relevant metrics from your customers’ interactions, such as handling time, agent behavior, queue length, and other relevant call center metrics and KPIs.
With deterministic evaluation processes such as the Factual Knowledge and QA Accuracy metrics of FMEval , ground truth generation and evaluation metric implementation are tightly coupled. To convert the source document excerpt into ground truth, we provide a base LLM prompt template.
Model cards are an essential component for registered ML models, providing a standardized way to document and communicate key model metadata, including intended use, performance, risks, and business information. Train your ML model with the prepared data and register the candidate model package version with training metrics.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content