This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. Run the script init-script.bash : chmod u+x init-script.bash./init-script.bash
BERT is pre-trained on masking random words in a sentence; in contrast, during Pegasus’s pre-training, sentences are masked from an input document. The model then generates the missing sentences as a single output sequence using all the unmasked sentences as context, creating an executive summary of the document as a result.
For example, a use case that’s been moved from the QA stage to pre-production could be rejected and sent back to the development stage for rework because of missing documentation related to meeting certain regulatory controls. These stages are applicable to both use case and model stages. To get started, set-up a name for your experiment.
Batch transform The batch transform pipeline consists of the following steps: The pipeline implements a data preparation step that retrieves data from a PrestoDB instance (using a data preprocessing script ) and stores the batch data in Amazon Simple Storage Service (Amazon S3).
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. RAG is a popular technique that combines the use of private data with large language models (LLMs). txt) Markdown (.md)
Amazon Q returns the response as a JSON object (detailed in the Amazon Q documentation ). sourceAttributions – The source documents used to generate the conversation response. In Retrieval Augmentation Generation (RAG), this always refers to one or more documents from enterprise knowledge bases that are indexed in Amazon Q.
We live in an era of bigdata, AI, and automation, and the trends that matter in CX this year begin with the abilities – and pain points – ushered in by this technology. For example, bigdata makes things like hyper-personalized customer service possible, but it also puts enormous stress on data security.
Business analysts are involved in activities such as relationship building, process evaluation, requirements gathering, process improvement, scope definition, requirements documentation, non-technical and technical design, scope management, project support, charting future direction and road mapping.
SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. Customers can also access offline store data using a Spark runtime and perform bigdata processing for ML feature analysis and feature engineering use cases. Table formats provide a way to abstract data files as a table.
Imagine the possibilities: Quick and efficient brainstorming sessions, real-time ideation, and even drafting documents or code snippets—all powered by the latest advancements in AI. About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice.
default_bucket() upload _path = f"training data/fhe train.csv" boto3.Session().resource("s3").Bucket To see more information about natively supported frameworks and script mode, refer to Use Machine Learning Frameworks, Python, and R with Amazon SageMaker. resource("s3").Bucket Bucket (bucket).Object Object (upload path).upload
Amazon SageMaker offers several ways to run distributed data processing jobs with Apache Spark, a popular distributed computing framework for bigdata processing. install-scripts chmod +x install-history-server.sh./install-history-server.sh script and attach it to an existing SageMaker Studio domain.
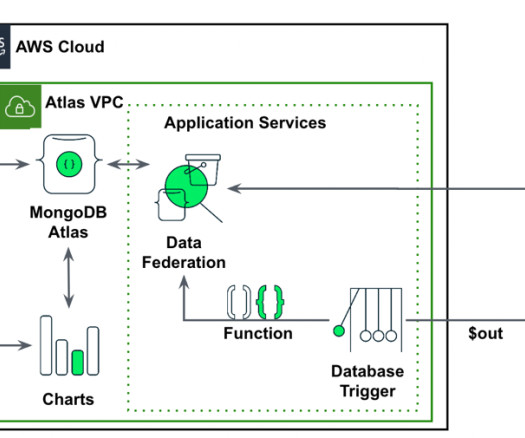
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud.
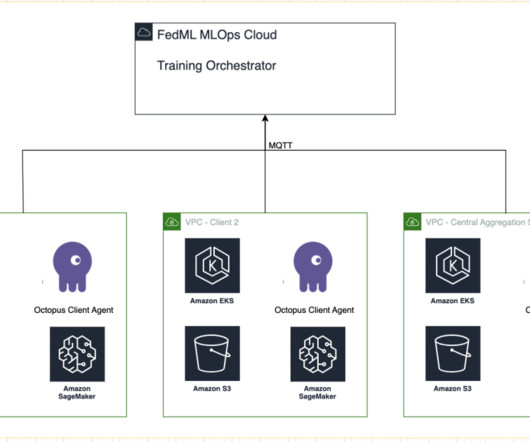
Create an MLOps deployment package As a part of the FedML documentation, we need to create the client and server packages, which the MLOps platform will distribute to the server and clients to begin training. To create these packages, run the following script found in the root directory: /build_mlops_pkg.sh
Register the Data Wrangler application within the IdP Refer to the following documentation for the IdPs that Data Wrangler supports: Azure AD Okta Ping Federate Use the documentation provided by your IdP to register your Data Wrangler application. bin/bash set -eux ## Script Body cat > ~/.snowflake_identity_provider_oauth_config
TechSee’s technology combines AI with deep machine learning, proprietary algorithms, and BigData to deliver a scalable cognitive system that becomes smarter with every customer support interaction. In addition, Product Managers can access reports to help design better products and support documents.
For detailed instructions on how to use the DGL-KE, refer to Training knowledge graph embeddings at scale with the Deep Graph Library and DGL-KE Documentation. SageMaker processing allows you to run a script remotely on a chosen instance type and Docker image without having to worry about resource allocation and data transfer.
Security is a big-data problem. Its widespread use and the general perception that such documents are airtight and static have lulled users into a false sense of security. As soon as a download attempt is made, it triggers the malicious executable script to connect to the attacker’s Command and Control server.
In the artificial intelligence (AI) space, athenahealth uses data science and machine learning (ML) to accelerate business processes and provide recommendations, predictions, and insights across multiple services. Each project maintained detailed documentation that outlined how each script was used to build the final model.
As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). At the start, the process is full of uncertainty and is highly iterative.
More information can be found in the official MLflow documentation. You can use this script add_users_and_groups.py After running the script, if you check the Amazon Cognito user pool on the Amazon Cognito console, you should see the three users created. At this point, the MLflow SDK only needs AWS credentials.
When you meet face-to-face, you can also securely share sensitive documents and information. Top features include screen sharing (for presentations) and on-screen collaboration (for documents). It’s also useful when you need to trace back your conversation with customers and share sensitive information and documents.
And you can look at various specific areas such as data analytics, bigdata, being able to study patterns within data, using artificial intelligence or using machine learning to actually gather up every customer interaction, and remember the original problem and the solution. This kind of thing really helps the agents.
Accelerate your security and AI/ML learning with best practices guidance, training, and certification AWS also curates recommendations from Best Practices for Security, Identity, & Compliance and AWS Security Documentation to help you identify ways to secure your training, development, testing, and operational environments.
Large language models (LLMs) are very large deep-learning models that are pre-trained on vast amounts of data. One model can perform completely different tasks such as answering questions, summarizing documents, translating languages, and completing sentences. Data must be preprocessed to enable semantic search during inference.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content