This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
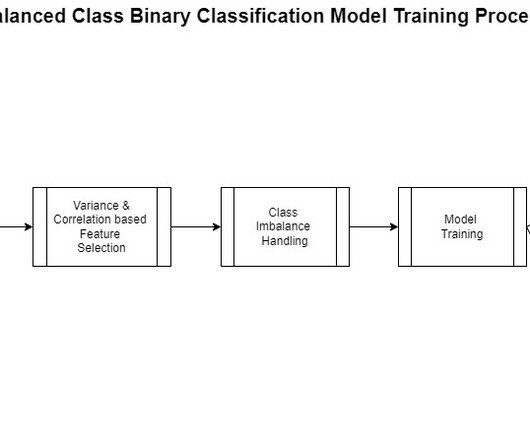
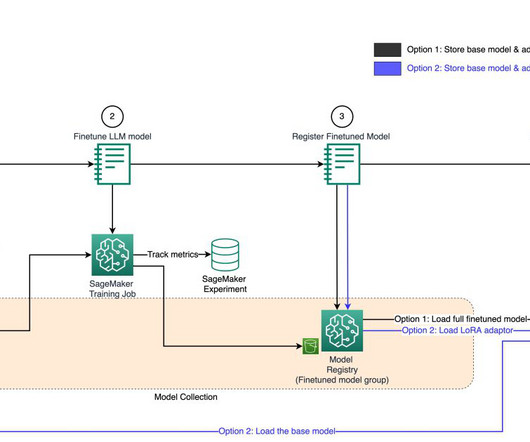
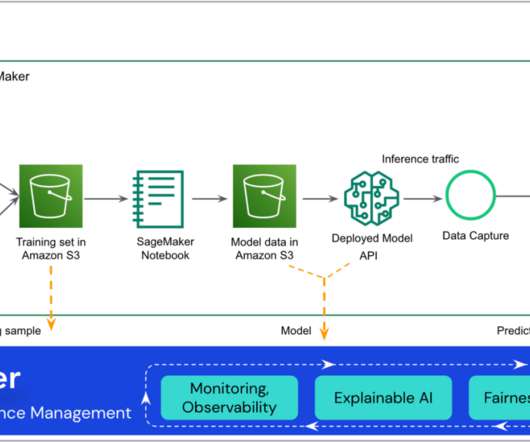
The DS uses SageMaker Training jobs to generate metrics captured by , selects a candidate model, and registers the model version inside the shared model group in their local model registry. After you have completed the data preparation step, it’s time to train the classification model.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
Create experiences that are proactively human-engineered. Within customer-related processes, experiences need to be designed, engineered, or re-engineered, so that authentic humanity is built in. It is employees who are the real, flexible experience engineers.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this data preparation is feature engineering. However, generalizing feature engineering is challenging.
A recent Calabrio research study of more than 1,000 C-Suite executives has revealed leaders are missing a key data stream – voice of the customer data. Download the report to learn how executives can find and use VoC data to make more informed business decisions.
In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda. Overview of solution The first thing to consider is that different metrics require different computation considerations. The function invokes the modules.
Bigdata is getting bigger with each passing year, but making sense of trends hidden deep in the heap of 1s and 0s is more confounding than ever. As metrics pile up, you may find yourself wondering which data points matter and in what ways they relate to your business’s interests.
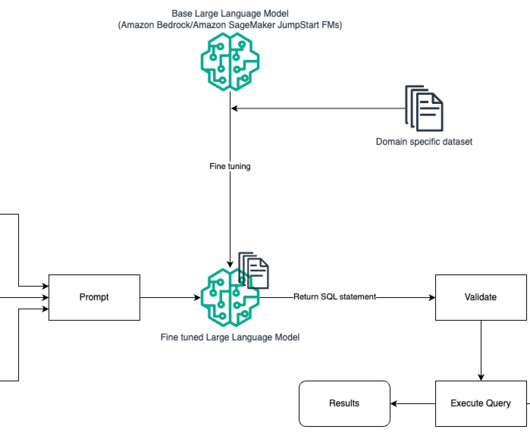
Specifically, we discuss the following: Why do we need Text2SQL Key components for Text to SQL Prompt engineering considerations for natural language or Text to SQL Optimizations and best practices Architecture patterns Why do we need Text2SQL? Effective prompt engineering is key to developing natural language to SQL systems.
This post focuses on evaluating and interpreting metrics using FMEval for question answering in a generative AI application. FMEval is a comprehensive evaluation suite from Amazon SageMaker Clarify , providing standardized implementations of metrics to assess quality and responsibility. Question Answer Fact Who is Andrew R.
Using BigData to Make Leadership Advances in the Workplace. While surveys that lead to these results are historically what we’ve had to understand engagement metrics, analytics are far more important. According to a recent Gallup poll, 13 percent of employees are actively engaged at work.
This is often referred to as platform engineering and can be neatly summarized by the mantra “You (the developer) build and test, and we (the platform engineering team) do all the rest!” Amazon Bedrock is compatible with robust observability features to monitor and manage ML models and applications.
With SageMaker Processing jobs, you can use a simplified, managed experience to run data preprocessing or postprocessing and model evaluation workloads on the SageMaker platform. Twilio needed to implement an MLOps pipeline that queried data from PrestoDB. The evaluation step uses the evaluation script as a code entry.
There are unique considerations when engineering generative AI workloads through a resilience lens. Make sure to validate prompt input data and prompt input size for allocated character limits that are defined by your model. If you’re performing prompt engineering, you should persist your prompts to a reliable data store.
Randy has held a variety of positions in the technology space, ranging from software engineering to product management. He entered the bigdata space in 2013 and continues to explore that area. Prior to joining AWS, Arnab was a technology leader and previously held architect and engineering leadership roles.
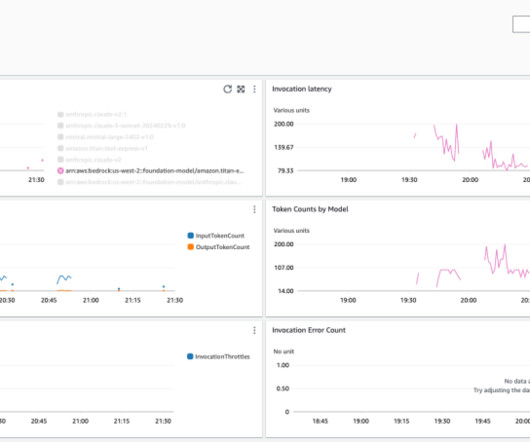
A new automatic dashboard for Amazon Bedrock was added to provide insights into key metrics for Amazon Bedrock models. From here you can gain centralized visibility and insights to key metrics such as latency and invocation metrics. Optionally, you can select a specific model to isolate the metrics to one model.
This enables data scientists to quickly build and iterate on ML models, and empowers ML engineers to run through continuous integration and continuous delivery (CI/CD) ML pipelines faster, decreasing time to production for models. Solution overview The proposed framework code starts by reading the configuration files. The model_unit.py
Before moving to full-scale production, BigBasket tried a pilot on SageMaker to evaluate performance, cost, and convenience metrics. Use SageMaker Distributed Data Parallelism (SMDDP) for accelerated distributed training. Log model training metrics. Use a custom PyTorch Docker container including other open source libraries.
Amazon DataZone allows you to create and manage data zones , which are virtual data lakes that store and process your data, without the need for extensive coding or infrastructure management. The data publisher is responsible for publishing and governing access for the bespoke data in the Amazon DataZone business data catalog.
This is Part 2 of a series on using data analytics and ML for Amp and creating a personalized show recommendation list platform. The platform has shown a 3% boost to customer engagement metrics tracked (liking a show, following a creator, enabling upcoming show notifications) since its launch in May 2022.
Prepare your data As expected in the ML process, your dataset may require transformations to address issues such as missing values, outliers, or perform feature engineering prior to model building. SageMaker Canvas provides ML data transforms to clean, transform, and prepare your data for model building without having to write code.
Use group sharing engines to share documents with strategies and knowledge across departments. Focus employee metrics more on CX enabling behaviors, less on survey ratings. Data can be insightful to all of the roles HR takes on in facilitating the company’s CX goals. Here are ways HR can help: Knowledge Management.
How to Improve the Data Science and LLM Development Process Anyone who has worked in data science will recognize this familiar scene: a clever data scientist copies code from a Git repository to a Jupyter notebook , makes some tweaks, and then pastes it back to push it towards production. and “It cannot be happening!”
Amp wanted a scalable data and analytics platform to enable easy access to data and perform machine leaning (ML) experiments for live audio transcription, content moderation, feature engineering, and a personal show recommendation service, and to inspect or measure business KPIs and metrics. Solution overview.
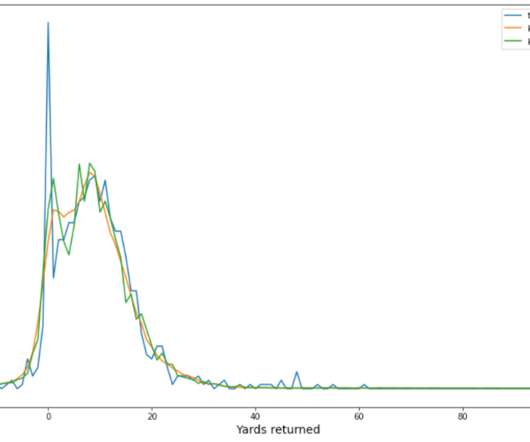
The data distribution for punt and kickoff are different. Data preprocessing and feature engineering First, the tracking data was filtered for just the data related to punts and kickoff returns. As a baseline, we used the model that won our NFL BigData Bowl competition on Kaggle.
As feature data grows in size and complexity, data scientists need to be able to efficiently query these feature stores to extract datasets for experimentation, model training, and batch scoring. SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation.
With the SageMaker Python SDK, you can seamlessly update the Model card with evaluation metrics. Model cards provide model risk managers, data scientists, and ML engineers the ability to perform the following tasks: Document model requirements such as risk rating, intended usage, limitations, and expected performance.
In their answers to the following questions, they should be addressing chatbots, self-service, machine learning, bigdata, and more. AI can be a powerful tool, but it is just one cog in the customer care engine. 5 What KPIs/metrics do you measure in tracking the effectiveness of your escalations from AI to live agent?
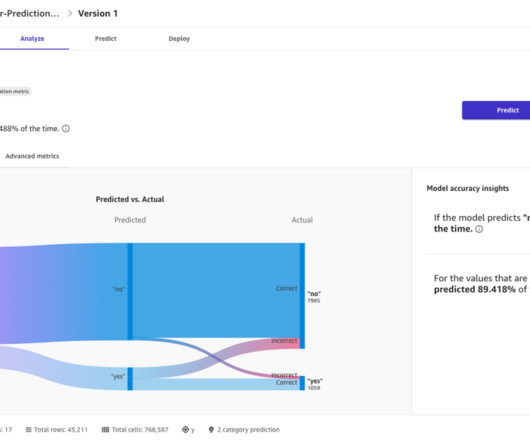
When the model is ready, select the model and click on the latest version Review the model metrics and column impact and if you are satisfied with the model performance, click Predict. Prior joining AWS, as a Data/Solution Architect he implemented many projects in BigData domain, including several data lakes in Hadoop ecosystem.
To overcome this, enterprises needs to shape a clear operating model defining how multiple personas, such as data scientists, dataengineers, ML engineers, IT, and business stakeholders, should collaborate and interact; how to separate the concerns, responsibilities, and skills; and how to use AWS services optimally.
One of the most confounding challenges for modern contact center leaders is reporting on any performance metric that requires information from more than one system or application, each of which is a self-contained silo of data. Traditionally contact centers have been dealing with two main data challenges. Real-time data.
Companies use advanced technologies like AI, machine learning, and bigdata to anticipate customer needs, optimize operations, and deliver customized experiences. Creating robust data governance frameworks and employing tools like machine learning, businesses tend derive actionable insights to achieve a competitive edge.
With the use of cloud computing, bigdata and machine learning (ML) tools like Amazon Athena or Amazon SageMaker have become available and useable by anyone without much effort in creation and maintenance. The predicted value indicates the expected value for our target metric based on the training data.
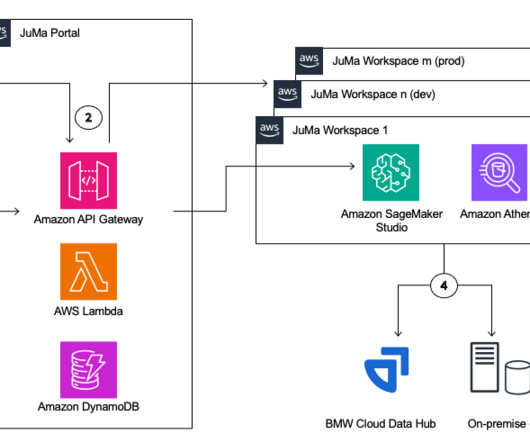
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. JuMa is now available to all data scientists, ML engineers, and data analysts at BMW Group.
In the era of bigdata and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. At the core of these cutting-edge solutions lies a foundation model (FM), a highly advanced machine learning model that is pre-trained on vast amounts of data.
The notebook also provides a sample dataset to run Fiddler’s explainability algorithms and as a baseline for monitoring metrics. Danny Brock is a Sr Solutions Engineer at Fiddler AI. He founded his own bigdata analytics consulting company, Branchbird, in 2012. Rajeev Govindan is a Sr Solutions Engineer at Fiddler AI.
As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). We also illustrate how you can track your pipeline workflow and generate metrics and comparison charts.
BigData and CX. The Myth: In order to improve customer experience, you have to invest in bigdata processing. You’ve probably already heard quite a lot about bigdata. That is why most companies hire specialized bigdataengineers who are able to go through it and obtain useful information.
Security is a big-data problem. It then chooses the hyperparameter values that result in a model that performs the best, as measured by a metric for the given ML task. 24xlarge and x1.32xlarge) to train the model on as large of a sample of the data as possible. The following diagram illustrates the solution architecture.
Consequently, maintaining and augmenting older projects required more engineering time and effort. In addition, as new data scientists joined the team, knowledge transfers and onboarding took more time, because synchronizing local environments included many undocumented dependencies. Logging and monitoring. Kubeflow Logging.
Customer satisfaction is a potent metric that directly influences the profitability of an organization. Node.js > 16 – Open-source JavaScript backend engine for application development and deployment. Vamshi is focused on Language AI and innovates in building world-class recommender engines. on an Amazon EC2 Instance.
DPM vendors help both the business and engineering teams to not only define conversion and revenue goals but also make sure they are reached. Bigdata monitoring and data visualization . When DPM is optimized, companies can deliver an engaging digital experience, maximize revenue and improve brand loyalty.
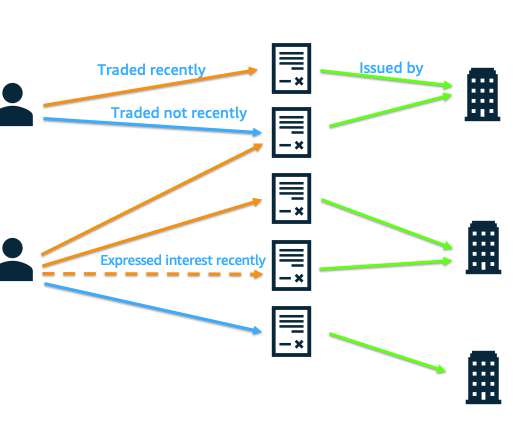
With other standard metrics, the improvement ranged from 50–130%. This performance enabled us to better match traders and bonds, indicating an enhanced trader experience within the model, with machine learning delivering a big step forward from hard-coded rules, which can be difficult to scale.
In an AI exercise, if the vendor keeps asking for more and more data, that is a red flag. It basically means that the lab-version of their model, with your data, is not seeing results. Start asking for model validation graphs on contact center performance metrics. Be wary of “statistics-speak”. Keep perspective.
BigData and CX. The Myth: In order to improve customer experience, you have to invest in bigdata processing. You’ve probably already heard quite a lot about bigdata. That is why most companies hire specialized bigdataengineers who are able to go through it and obtain useful information.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content