This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
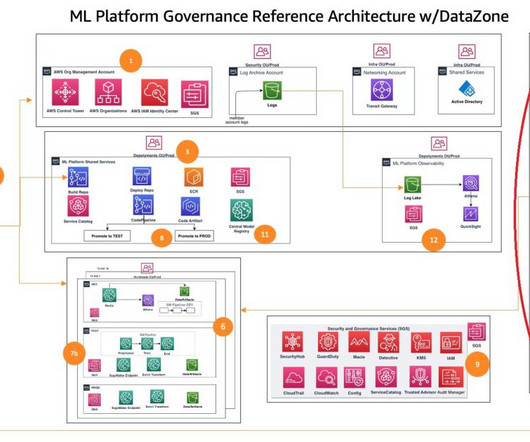
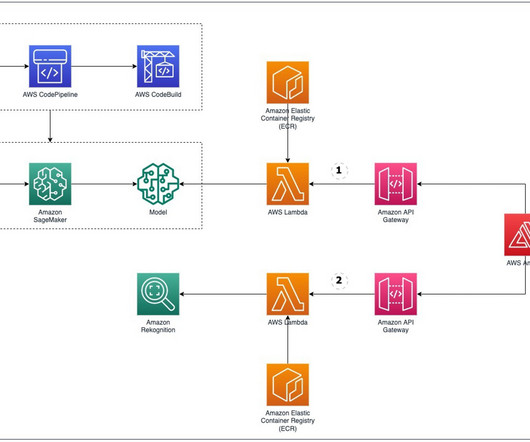
Challenges in data management Traditionally, managing and governing data across multiple systems involved tedious manual processes, custom scripts, and disconnected tools. The data management services function is organized through the data lake accounts (producers) and data science team accounts (consumers).
from time import gmtime, strftime experiment_suffix = strftime('%d-%H-%M-%S', gmtime()) experiment_name = f"credit-risk-model-experiment-{experiment_suffix}" The processing script creates a new MLflow active experiment by calling the mlflow.set_experiment() method with the experiment name above. fit_transform(y). Madhubalasri B.
We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw. For example, to use the RedPajama dataset, use the following command: wget [link] python nemo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py
Build your training script for the Hugging Face SageMaker estimator. script to use with Script Mode and pass hyperparameters for training. Thanks to our custom inference script hosted in a SageMaker endpoint, we can generate several summaries for this review with different text generation parameters. If we use an ml.g4dn.16xlarge
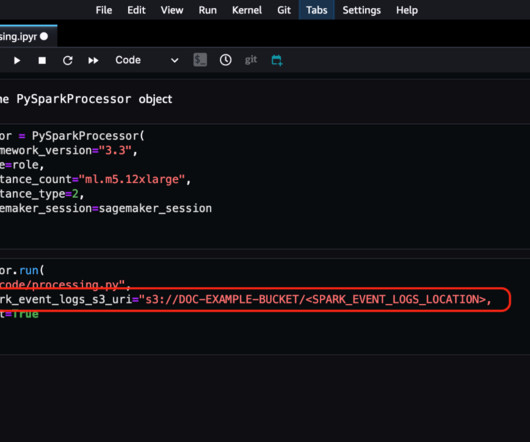
With SageMaker Processing jobs, you can use a simplified, managed experience to run data preprocessing or postprocessing and model evaluation workloads on the SageMaker platform. Twilio needed to implement an MLOps pipeline that queried data from PrestoDB. For more information on processing jobs, see Process data.
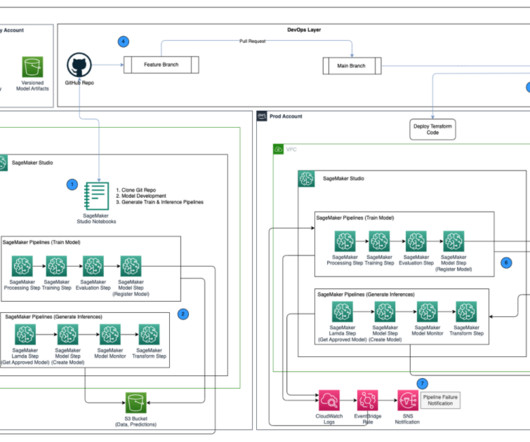
This enables data scientists to quickly build and iterate on ML models, and empowers ML engineers to run through continuous integration and continuous delivery (CI/CD) ML pipelines faster, decreasing time to production for models. You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices.
We use the custom terminology dictionary to compile frequently used terms within video transcription scripts. in Mechanical Engineering from the University of Notre Dame. Max Goff is a data scientist/dataengineer with over 30 years of software development experience. Here’s an example. She received her Ph.D.
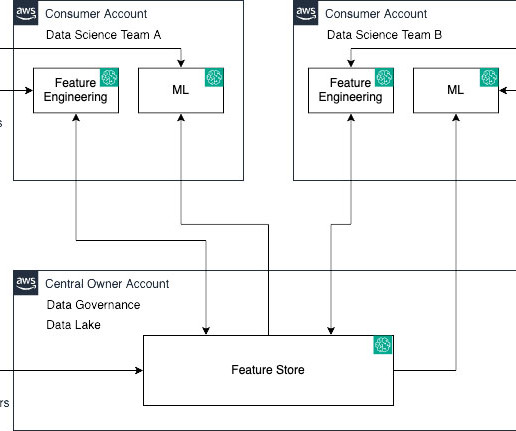
As feature data grows in size and complexity, data scientists need to be able to efficiently query these feature stores to extract datasets for experimentation, model training, and batch scoring. SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. AWS Glue Job setup.
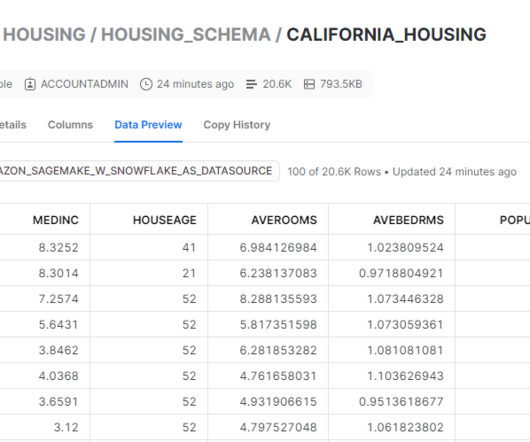
We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket. 1 with the following additions: The Snowflake Connector for Python to download the data from the Snowflake table to the training instance.
To create these packages, run the following script found in the root directory: /build_mlops_pkg.sh Randy has held a variety of positions in the technology space, ranging from software engineering to product management. He entered the bigdata space in 2013 and continues to explore that area.
After downloading the latest Neuron NeMo package, use the provided neox and pythia pre-training and fine-tuning scripts with optimized hyper-parameters and execute the following for a four node training. Amith (R) Mamidala is the senior machine learning application engineering at AWS Annapurna Labs. He founded StylingAI Inc.,
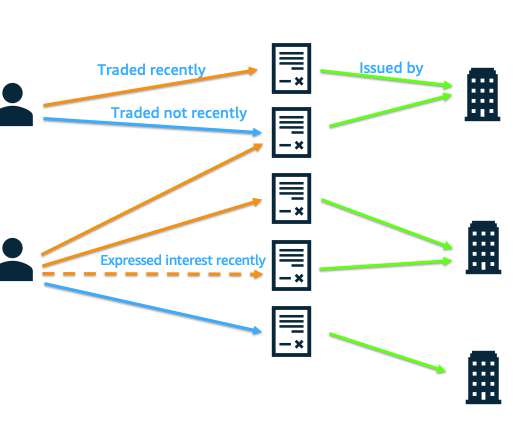
Let’s demystify this using the following personas and a real-world analogy: Data and ML engineers (owners and producers) – They lay the groundwork by feeding data into the feature store Data scientists (consumers) – They extract and utilize this data to craft their models Dataengineers serve as architects sketching the initial blueprint.
Amazon SageMaker offers several ways to run distributed data processing jobs with Apache Spark, a popular distributed computing framework for bigdata processing. install-scripts chmod +x install-history-server.sh./install-history-server.sh script and attach it to an existing SageMaker Studio domain.
Under Advanced Project Options , for Definition , select Pipeline script from SCM. For Script Path , enter Jenkinsfile. upload_file("pipelines/train/scripts/raw_preprocess.py","mammography-severity-model/scripts/raw_preprocess.py") s3_client.Bucket(default_bucket).upload_file("pipelines/train/scripts/evaluate_model.py","mammography-severity-model/scripts/evaluate_model.py")
About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice. He helps customers implement bigdata, machine learning, analytics solutions, and generative AI solutions. Outside of work, he enjoys spending time with family, reading, running, and playing golf.
Developers usually test their processing and training scripts locally, but the pipelines themselves are typically tested in the cloud. From a very high level, the ML lifecycle consists of many different parts, but the building of an ML model usually consists of the following general steps: Data cleansing and preparation (feature engineering).
During each training iteration, the global data batch is divided into pieces (batch shards) and a piece is distributed to each worker. Each worker then proceeds with the forward and backward pass defined in your training script on each GPU.
We perform data exploration and feature engineering using a SageMaker notebook, and then perform model training using a SageMaker training job. At this stage, you may also need to do additional feature engineering of your dataset or integrate with different offline feature stores. resource("s3").Bucket Bucket (bucket).Object
Data I/O design SageMaker interacts directly with Amazon S3 for reading inputs and storing outputs of individual steps in the training and inference pipelines. The pipeline will automatically upload Python scripts from the GitLab repository and store output files or model artifacts from each step in the appropriate S3 path.
We found that we didn’t need to separate data preparation, model training, and prediction, and it was convenient to package the whole pipeline as a single script and use SageMaker processing. This was simple and cost-effective for us, because the GPU instance is only used and paid for during the 15 minutes needed for the script to run.
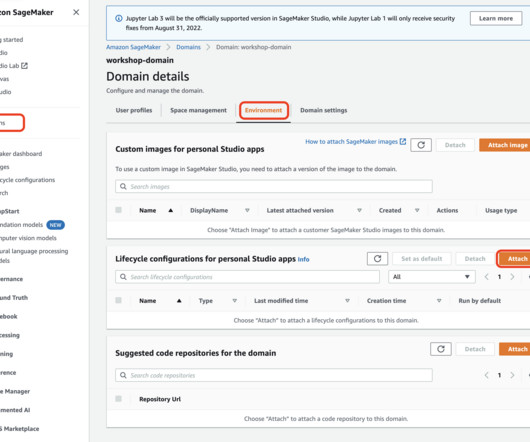
When you open a notebook in Studio, you are prompted to set up your environment by choosing a SageMaker image, a kernel, an instance type, and, optionally, a lifecycle configuration script that runs on image startup. The main benefit is that a data scientist can choose which script to run to customize the container with new packages.
Accordingly, I expect to see a range of new solutions see the light of day in 2018; solutions that bring the old solutions like Interactive Voice Response (cue the robotic ‘press 1 for English’ script) into the 21 st century, on a channel people actually like to use.
Amp wanted a scalable data and analytics platform to enable easy access to data and perform machine leaning (ML) experiments for live audio transcription, content moderation, feature engineering, and a personal show recommendation service, and to inspect or measure business KPIs and metrics. DataEngineer for Amp on Amazon.
With over 50 connectors, an intuitive Chat for data prep interface, and petabyte support, SageMaker Canvas provides a scalable, low-code/no-code (LCNC) ML solution for handling real-world, enterprise use cases. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
The triggers need to be scheduled to write the data to S3 at a period frequency based on the business need for training the models. Prior joining AWS, as a Data/Solution Architect he implemented many projects in BigData domain, including several data lakes in Hadoop ecosystem.
Each project maintained detailed documentation that outlined how each script was used to build the final model. In many cases, this was an elaborate process involving 5 to 10 scripts with several outputs each. Consequently, maintaining and augmenting older projects required more engineering time and effort.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. Configure SageMaker Studio You store the fields and values in a Secrets Manager secret and add it to the Studio Lifecycle Configuration that you’re using for Data Wrangler.
Populate the data Run the following script to populate the DynamoDB tables and Amazon Cognito user pool with the required information: /scripts/setup/fill-data.sh The script performs the required API calls using the AWS Command Line Interface (AWS CLI) and the previously configured parameters and profiles.
Security is a big-data problem. As soon as a download attempt is made, it triggers the malicious executable script to connect to the attacker’s Command and Control server. With the built-in algorithm for XGBoost , you can do this without any additional custom script.
How to Build Your Customer-Driven Growth Engine by Jeanne Bliss. How to Revolutionize Customer Employee Engagement with BigData and Gamification by Rajat Paharia. focuses on how to use bigdata and gamification to engage your customers more than ever before. Free Download] Live Chat Scripts to Make Stellar Agents.
In the following sections, we demonstrate how to build a RAG workflow using Knowledge Bases for Amazon Bedrock, backed by the OpenSearch Serverless vector engine, to analyze an unstructured clinical trial dataset for a drug discovery use case. This data is information rich but can be vastly heterogenous. Nihir Chadderwala is a Sr.
Data Wrangler reduces the time it takes to aggregate and prepare data for ML from weeks to minutes. Add a custom transformation to detect and remove image outliers With image preparation in Data Wrangler, we can also invoke another endpoint for another model. Lu Huang is a Senior Product Manager on Data Wrangler.
Two components need to be configured in our inference script : model loading and model serving. On top, he likes thinking big with customers to innovate and invent new ideas for them. Aamna Najmi is a Data Scientist with AWS Professional Services. Ahmed Mansour is a Data Scientist at AWS Professional Services.
You can use this script add_users_and_groups.py After running the script, if you check the Amazon Cognito user pool on the Amazon Cognito console, you should see the three users created. import boto3 # Session using the SageMaker Execution Role in the Data Science Account session = boto3.Session() large', framework_version='1.0-1',
As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). He has experience in the telecommunications and software engineering. About the authors.
It’s also why these same transcription-based engines like a Google or Amazon don’t deliver a good enough customer experience at the contact center level, because they are now 50% less accurate. Here is a call into emergency roadside assistance prior to the CX design work from Hollywood script writers.
Teradata Listener is intelligent, self-service software with real-time “listening ” capabilities to follow multiple streams of sensor and IoT data wherever it exists globally, and then propagate the data into multiple platforms in an analytical ecosystem. Teradata Integrated BigData Platform 1800.
As a solution, organizations continue to turn to AI, machine learning, NLP and ultimately the production of bigdata to monitor and analyze performance. These results are then delivered straight into the customer’s preferred BI platform, making way for the consolidation of disparate enterprise data for heightened insights.
And you can look at various specific areas such as data analytics, bigdata, being able to study patterns within data, using artificial intelligence or using machine learning to actually gather up every customer interaction, and remember the original problem and the solution.
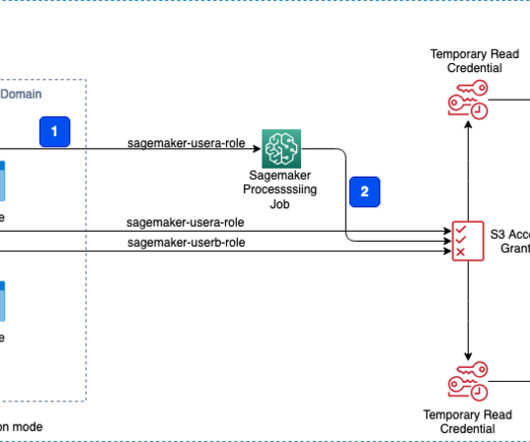
Amazon SageMaker Studio provides a single web-based visual interface where different personas like data scientists, machine learning (ML) engineers, and developers can build, train, debug, deploy, and monitor their ML models. ML engineers require access to intermediate model artifacts stored in Amazon S3 from past training jobs.
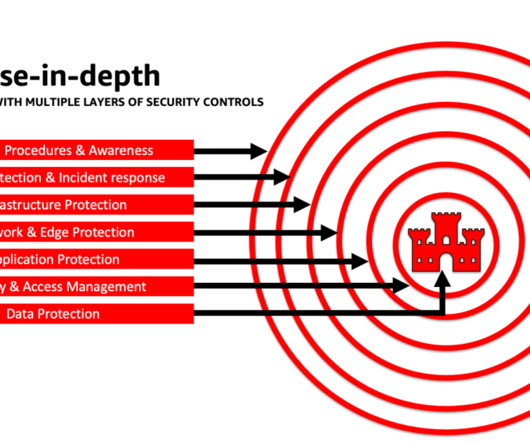
The goal of this post is to empower AI and machine learning (ML) engineers, data scientists, solutions architects, security teams, and other stakeholders to have a common mental model and framework to apply security best practices, allowing AI/ML teams to move fast without trading off security for speed.
In this role you will work collaboratively with our Sales, Engineering, and Leadership team to develop meaningful content across multiple channels that drives brand awareness through effective messaging. Create slide decks, presentations, digital material, weekly blogs, and scripts for animations and videos.
LLMs have the potential to revolutionize content creation and the way people use search engines and virtual assistants. Retrieval Augmented Generation (RAG) is the process of optimizing the output of an LLM, so it references an authoritative knowledge base outside of its training data sources before generating a response.
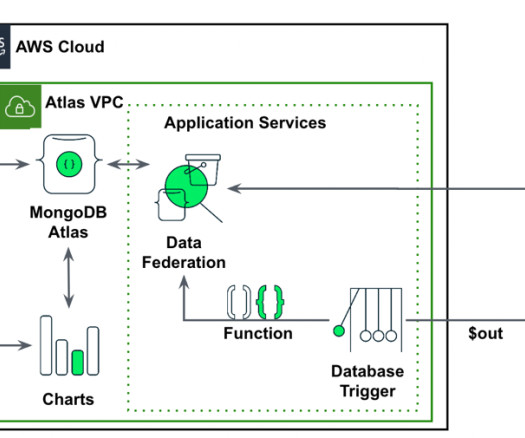
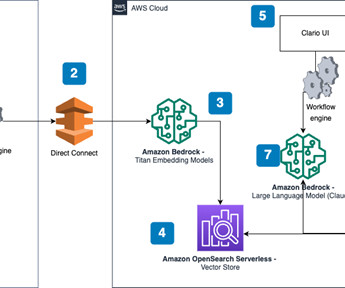
The solution is shown in the following figure: Architecture walkthrough Charter-derived documents are processed in an on-premises script in preparation for uploading. The script chunks the documents and calls an embedding model to produce the document embeddings. Files are sent to AWS using AWS Direct Connect.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content