This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A Business or Enterprise Google Workspace account with access to Google Chat. Run the script init-script.bash : chmod u+x init-script.bash./init-script.bash init-script.bash This script prompts you for the following: The Amazon Bedrock knowledge base ID to associate with your Google Chat app (refer to the prerequisites section).
The data mesh architecture aims to increase the return on investments in data teams, processes, and technology, ultimately driving business value through innovative analytics and ML projects across the enterprise. This approach was not only time-consuming but also prone to errors and difficult to scale.
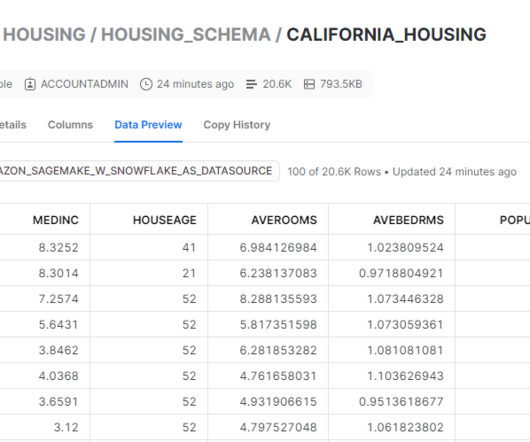
We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket. 1 with the following additions: The Snowflake Connector for Python to download the data from the Snowflake table to the training instance.
from time import gmtime, strftime experiment_suffix = strftime('%d-%H-%M-%S', gmtime()) experiment_name = f"credit-risk-model-experiment-{experiment_suffix}" The processing script creates a new MLflow active experiment by calling the mlflow.set_experiment() method with the experiment name above. fit_transform(y).
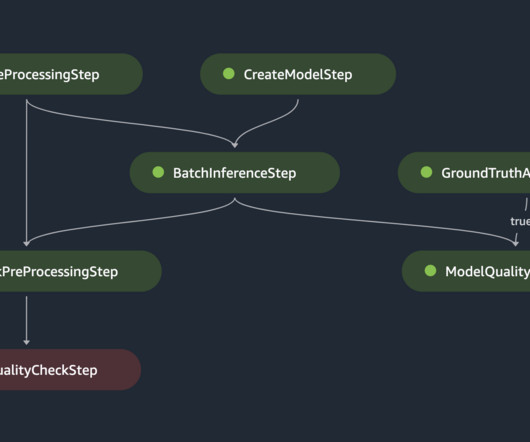
Batch transform The batch transform pipeline consists of the following steps: The pipeline implements a data preparation step that retrieves data from a PrestoDB instance (using a data preprocessing script ) and stores the batch data in Amazon Simple Storage Service (Amazon S3).
You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices. framework/createmodel/ – This directory contains a Python script that creates a SageMaker model object based on model artifacts from a SageMaker Pipelines training step. script is used by pipeline_service.py The model_unit.py
Learn more about how speech analytics can benefit your call center operation by downloading our white paper, 10 Ways Speech Analytics Empowers the Entire Enterprise. They can assess how current scripts are performing and change them as needed. There would be no operations without customers. Jesse Silkoff.
My focus is customer service within the enterprise, and both are places where emerging technologies aren’t rushed, but are eventually embraced fully once investment decisions have been made. But it’s still early – very early. Adoption of most consumer-facing innovation starts in Marketing Departments.
According to Gartner, 75% of enterprises will shift from piloting AI to operationalizing it by 2025. In the same spirit, cloud computing is often the backbone of AI applications, advanced analytics, and data-heavy systems. A Harvard Business Review study found that companies using bigdata analytics increased profitability by 8%.
Today, CXA encompasses various technologies such as AI, machine learning, and bigdata analytics to provide personalized and efficient customer experiences. Seamless integration with existing CRM tools and other enterprise systems is a critical feature of leading CX platforms.
Amazon Q can help you get fast, relevant answers to pressing questions, solve problems, generate content, and take actions using the data and expertise found in your company’s information repositories and enterprise systems. You can also find the script on the GitHub repo. A VPC where you will deploy the solution.
Amazon SageMaker Canvas now empowers enterprises to harness the full potential of their data by enabling support of petabyte-scale datasets. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data. He has a background in AI/ML & bigdata.
Under Advanced Project Options , for Definition , select Pipeline script from SCM. For Script Path , enter Jenkinsfile. upload_file("pipelines/train/scripts/raw_preprocess.py","mammography-severity-model/scripts/raw_preprocess.py") s3_client.Bucket(default_bucket).upload_file("pipelines/train/scripts/evaluate_model.py","mammography-severity-model/scripts/evaluate_model.py")
We’ve compiled a short list of innovative customer service technologies developed by talented companies that are dedicated to helping enterprises improve their customer experience at scale and successfully compete in today’s ever-changing business environment. 1. Casengo. Servicefriend.
Amazon CodeWhisperer currently supports Python, Java, JavaScript, TypeScript, C#, Go, Rust, PHP, Ruby, Kotlin, C, C++, Shell scripting, SQL, and Scala. times more energy efficient than the median of surveyed US enterprisedata centers and up to 5 times more energy efficient than the average European enterprisedata center.
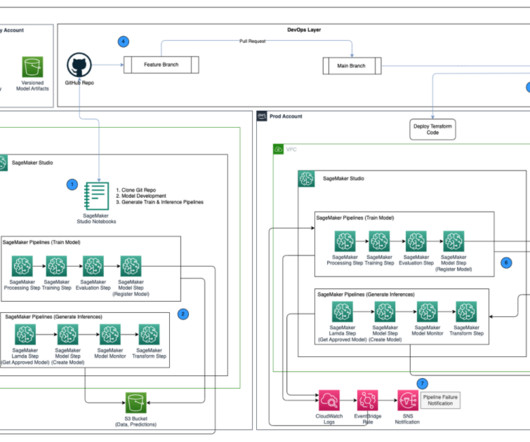
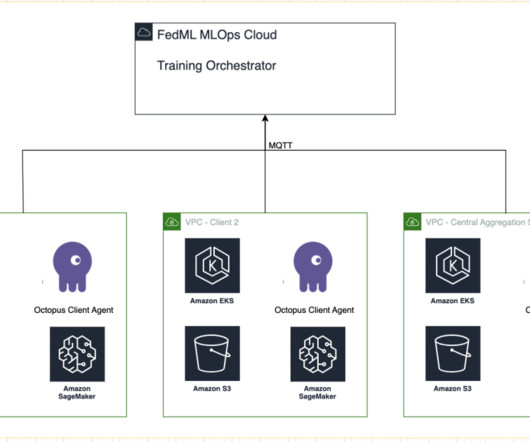
Solution overview The following figure illustrates the proposed target MLOps architecture for enterprise batch inference for organizations who use GitLab CI/CD and Terraform infrastructure as code (IaC) in conjunction with AWS tools and services. The data scientist can review and approve the new version of the model independently.
JumpStart accepts custom VPC settings and AWS Key Management Service (AWS KMS) encryption keys, so you can use the available models and solutions securely within your enterprise environment. We first fetch any additional packages, as well as scripts to handle training and inference for the selected task.
SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. Customers can also access offline store data using a Spark runtime and perform bigdata processing for ML feature analysis and feature engineering use cases. Table formats provide a way to abstract data files as a table.
To create these packages, run the following script found in the root directory: /build_mlops_pkg.sh He entered the bigdata space in 2013 and continues to explore that area. Her specialization is machine learning, and she is actively working on designing solutions using various AWS ML, bigdata, and analytics offerings.
You can further empower your team by deploying a Slack gateway for Amazon Q Business , the generative AI assistant that empowers employees based on knowledge and data in your enterprise systems. About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice.
JumpStart accepts custom VPC settings and AWS Key Management Service (AWS KMS) encryption keys, so you can use the available models and solutions securely within your enterprise environment. We first fetch any additional packages, as well as scripts to handle training and inference for the selected task.
When you open a notebook in Studio, you are prompted to set up your environment by choosing a SageMaker image, a kernel, an instance type, and, optionally, a lifecycle configuration script that runs on image startup. The main benefit is that a data scientist can choose which script to run to customize the container with new packages.
default_bucket() upload _path = f"training data/fhe train.csv" boto3.Session().resource("s3").Bucket To see more information about natively supported frameworks and script mode, refer to Use Machine Learning Frameworks, Python, and R with Amazon SageMaker. resource("s3").Bucket Bucket (bucket).Object Object (upload path).upload
JumpStart accepts custom VPC settings and AWS Key Management Service (AWS KMS) encryption keys, so you can use the available models and solutions securely within your enterprise environment. We fetch any additional packages, as well as scripts to handle training and inference for the selected task. Semantic segmentation.
Knowledge Bases for Amazon Bedrock supports multiple vector databases, including Amazon OpenSearch Serverless , Amazon Aurora , Pinecone, and Redis Enterprise Cloud. For enterprise implementations, Knowledge Bases supports AWS Key Management Service (AWS KMS) encryption, AWS CloudTrail integration, and more. Nihir Chadderwala is a Sr.
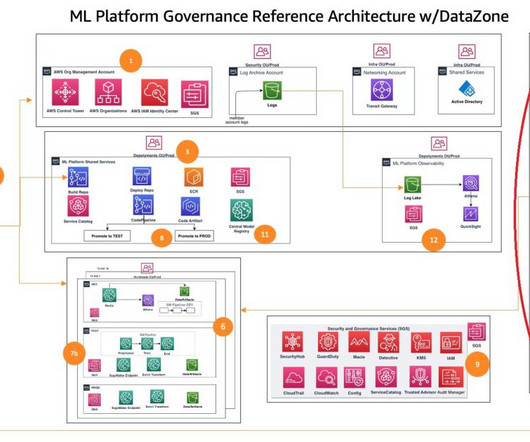
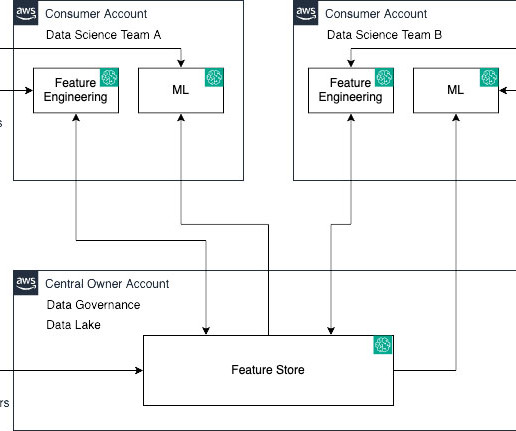
Enterprise customers have multiple lines of businesses (LOBs) and groups and teams within them. These customers need to balance governance, security, and compliance against the need for machine learning (ML) teams to quickly access their data science environments in a secure manner. We’d love to hear your feedback!
This new capability promotes collaboration and minimizes duplicate work for teams involved in ML model and application development, particularly in enterprise environments with multiple accounts spanning different business units or functions. You need to provide your consumer AWS account ID before running the notebook.
During each training iteration, the global data batch is divided into pieces (batch shards) and a piece is distributed to each worker. Each worker then proceeds with the forward and backward pass defined in your training script on each GPU.
As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). He works with enterprise customers and partners deploying AI solutions in the cloud.
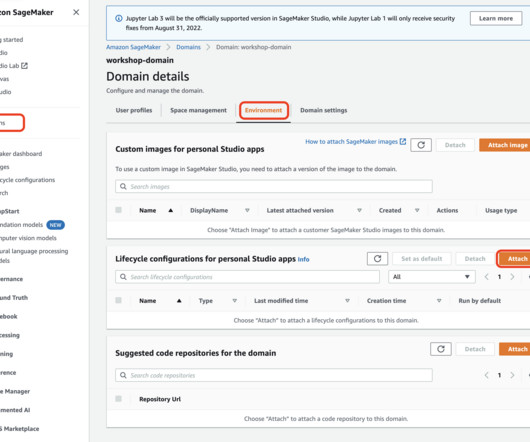
Configure SageMaker Studio You store the fields and values in a Secrets Manager secret and add it to the Studio Lifecycle Configuration that you’re using for Data Wrangler. A Lifecycle Configuration is a shell script that automatically loads the credentials stored in the secret when the user logs into Studio. Choose Jupyter server app.
The rapid adoption of smart phones and other mobile platforms has generated an enormous amount of image data. According to Gartner , unstructured data now represents 80–90% of all new enterprisedata, but just 18% of organizations are taking advantage of this data.
Each project maintained detailed documentation that outlined how each script was used to build the final model. In many cases, this was an elaborate process involving 5 to 10 scripts with several outputs each. These had to be manually tracked with detailed instructions on how each output would be used in subsequent processes.
Security is a big-data problem. As soon as a download attempt is made, it triggers the malicious executable script to connect to the attacker’s Command and Control server. With the built-in algorithm for XGBoost , you can do this without any additional custom script. Digant Patel is an Enterprise Support Lead at AWS.
A digital transformation must be an enterprise-wide strategic initiative that addresses all aspects of a corporation: its strategy, technology, systems, operations, processes, policies, organization, people and culture. In other situations, the technology may be current but the script and voice user interface (VUI) is old and ineffective.
This can be a challenge for enterprises in regulated industries that need to keep strong model governance for audit purposes. You can use this script add_users_and_groups.py After running the script, if you check the Amazon Cognito user pool on the Amazon Cognito console, you should see the three users created.
AI is revolutionising the customer experience through the analysis of bigdata, the use of bots to answer doubts or queries in the client’s psyche, and upgraded customer relationship management (CRM). Robotic Process Automation.
As a solution, organizations continue to turn to AI, machine learning, NLP and ultimately the production of bigdata to monitor and analyze performance. These results are then delivered straight into the customer’s preferred BI platform, making way for the consolidation of disparate enterprisedata for heightened insights.
AI is revolutionising the customer experience through the analysis of bigdata, the use of bots to answer clients’ doubts or queries, and upgraded customer relationship management (CRM). One technology that is driving the advances in customer service is Artificial intelligence (AI). Robotic Process Automation.
The new SOASTA mPulse enhancements make BigData insights easy to visualize, access and share. Instead of siloing information within groups, SOASTA mPulse with embedded Data Science Workbench reports help enterprises isolate issues, triage performance problems, and make decisions based on a better understanding of the customer. .
Whether youre a small business struggling to handle customer calls or a large enterprise looking to reduce operational costs, ROI CX has a solution. Its incorporating more artificial intelligence solutions for companies interested in benefiting from bigdata and AI insights. However, its not a one-to-one correlation.
With in-depth training sessions through e-learning, virtual assistance, and scripting tools, clearly establish company goals and expectations and provide your agents the confidence to tackle any initiative. Wikibon predicted that enterprise cloud spending is growing at a 16% compound annual growth (CAGR) run rate between 2016 and 2026.
Data Security & Privacy in AI Chatbot Communication for Enterprise Business Data security and privacy are critical considerations for any enterprise business using AI chatbots to communicate with customers or employees. Here’s a step-by-step guide to getting started with chatbot scripts.
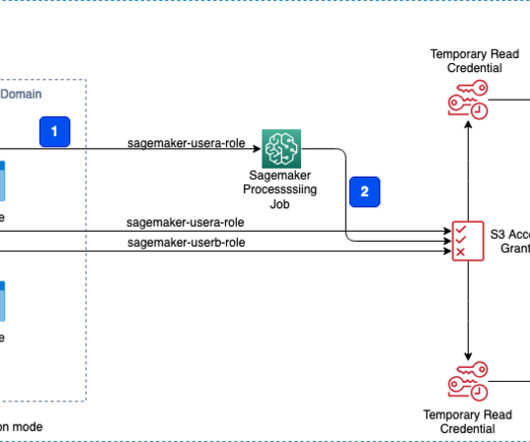
This will open a new Python notebook, which we use to run the PySpark script. Let’s validate the access grants by running a distributed job using SageMaker Processing jobs to process data, because we often need to process data before it can be used for training ML models. On the Launcher page, choose Python 3 under Notebook.
Reviews can be performed using tools like the AWS Well-Architected Tool , or with the help of your AWS team through AWS Enterprise Support. Define strict data ingress and egress rules to help protect against manipulation and exfiltration using VPCs with AWS Network Firewall policies.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content