This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
(Boomtrain) Artificial Intelligence, machine learning, and bigdata analytics have been around for a while in the B2B world. My Comment: Personalization is becoming one of the best ways to deliver a better customer experience and artificial intelligence (AI) is playing a big role in helping companies deliver that better experience.
The Types of Data for Your Metrics. Peppers says there are two different types of data that feed your metrics: Voice of Customer (VOC) Data: Peppers calls these metrics interactive data, meaning your customer interacts with you through a poll. VOC Data Can Be Deceiving Where Numbers Are Not.
Digital disruption, IOT, AI, bigdata, sophisticated and mysterious algorithms, bots…and the list goes on. This author makes the point with the example of Grab, a digital disrupter to the taxi business in Malaysia (and surrounding countries) that is similar to Uber and Lyft. The new language was scaring the pants off me.
It includes processes for monitoring model performance, managing risks, ensuring data quality, and maintaining transparency and accountability throughout the model’s lifecycle. You can build a use case (or AI system) using existing models, newly built models, or combination of both.
For example, the chat assistant doesnt need all the headers from some HTTP requests, but it does need the host and user agent. Data aggregation: Reducing data size Users only need to know by the minute when a problem occurred, so aggregating data at the minute level helped to reduce the data size.
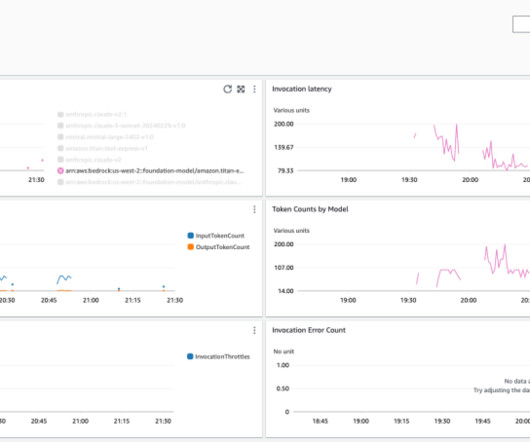
In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda. Overview of solution The first thing to consider is that different metrics require different computation considerations. The function invokes the modules.
Bigdata has been a buzzword in the customer service industry for some time now. As every brand knows, all data—big and small—can be applied in some manner to drive sales and improve customer service. Here are five essential bigdata sources to look at—and how you can use them to create exceptional customer experiences.
In addition, contact center metrics such as average handling time and first contact resolution provide data on how the customer experience is affected by service practices. Here are five ways bigdata can be used to improve the customer experience. Identify the metrics that need improvement in the contact center.
This post focuses on evaluating and interpreting metrics using FMEval for question answering in a generative AI application. FMEval is a comprehensive evaluation suite from Amazon SageMaker Clarify , providing standardized implementations of metrics to assess quality and responsibility. Question Answer Fact Who is Andrew R.
Bigdata is getting bigger with each passing year, but making sense of trends hidden deep in the heap of 1s and 0s is more confounding than ever. As metrics pile up, you may find yourself wondering which data points matter and in what ways they relate to your business’s interests. The properties of your data.
How Can Companies Use All This Data? Unstructured data: Unstructured data can be defined as “information, in many different forms, that doesn’t hew to conventional data models.” An example is voice recordings from callers to a call center. The Process of Using BigData. Get Started Now.
We will use the contextual conversational assistant example in the Amazon Bedrock GitHub repository to provide examples of how you can customize these views to further enhance visibility, tailored to your use case. A new automatic dashboard for Amazon Bedrock was added to provide insights into key metrics for Amazon Bedrock models.
Turning BigData into Big Decisions. In this Opentalk session, Tomasz reveals the biggest mistakes startups make with their metrics and what to do about it to optimize your business. The number one metric mistake. Lagging metrics create long feedback loops — too long. The 411 on Proxy Metrics.
However, at the same time, it is also one of the CX metrics that cannot be measured straightforwardly. Invest in some smart and intuitive online survey maker that comes with survey question examples to compile smart surveys. This metric is called CES or Customer Effort Score, and it should be as low as possible. Let’s find out!
Turning BigData into Big Decisions. In this Opentalk session, Tomasz reveals the biggest mistakes startups make with their metrics and what to do about it to optimize your business. The number one metric mistake. Lagging metrics create long feedback loops — too long. The 411 on Proxy Metrics.
A 2015 Capgemini and EMC study called “Big & Fast Data: The rise of Insight-Driven Business” showed that: 56% of the 1,000 senior decision makers surveyed claim that their investment in bigdata over the next three years will exceed past investment in information management. ” Bold words indeed!
They serve as a bridge between IT and other business functions, making data-driven recommendations that meet business requirements and improve processes while optimizing costs. That requires involvement in process design and improvement, workload planning and metric and KPI analysis. Kirk Chewning. kirkchewning.
A 2015 Capgemini and EMC study called “Big & Fast Data: The rise of Insight-Driven Business” showed that: 56% of the 1,000 senior decision makers surveyed claim that their investment in bigdata over the next three years will exceed past investment in information management. ” Bold words indeed!
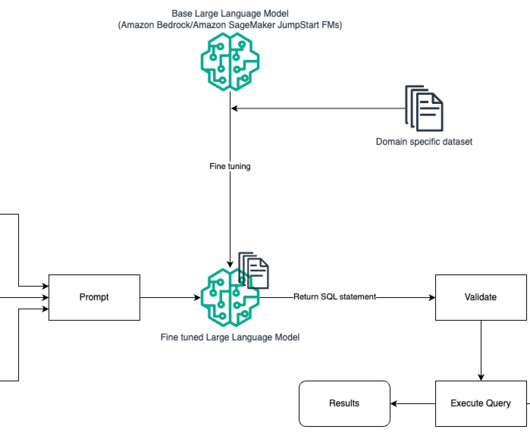
Including a few annotated examples of natural language prompts and corresponding SQL queries helps guide the model to produce syntax-compliant output. Additionally, incorporating Retrieval Augmented Generation (RAG), where the model retrieves similar examples during processing, further improves the mapping accuracy. gymnast_id = t2.
With a data flow, you can prepare data using generative AI, over 300 built-in transforms, or custom Spark commands. Complete the following steps: Choose Prepare and analyze data. For Data flow name , enter a name (for example, AssessingMentalHealthFlow ). SageMaker Data Wrangler will open. Choose Create.
The framework code and examples presented here only cover model training pipelines, but can be readily extended to batch inference pipelines as well. Each modeling unit is a sequence of up to six steps for training an ML model: process, train, create model, transform, metrics, and register model. The model_unit.py The pipeline_service.py
A Harvard Business Review study found that companies using bigdata analytics increased profitability by 8%. While this statistic specifically addresses data-centric strategies, it highlights the broader value of well-structured technical investments. Real-world examples show how they solve problems and adapt to new challenges.
Today, CXA encompasses various technologies such as AI, machine learning, and bigdata analytics to provide personalized and efficient customer experiences. One early example were email autoresponders that sent out immediate confirmations of receipt. For example, Klarna has saved $40M annually since implementing AI agents.
Provide control through transparency of models, guardrails, and costs using metrics, logs, and traces The control pillar of the generative AI framework focuses on observability, cost management, and governance, making sure enterprises can deploy and operate their generative AI solutions securely and efficiently.
The following code shows an example of how a query is configured within the config.yml file. This query is used at the data processing step of the training pipeline to fetch data from the PrestoDB instance. This step registers the model only if the given user-defined metric threshold is met.
Distributed training is a technique that allows for the parallel processing of large amounts of data across multiple machines or devices. By splitting the data and training multiple models in parallel, distributed training can significantly reduce training time and improve the performance of models on bigdata.
In the era of bigdata and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. At the core of these cutting-edge solutions lies a foundation model (FM), a highly advanced machine learning model that is pre-trained on vast amounts of data. Python 3.10
According to Forbes, call center metrics are the data harvested from all the solutions used to operate a call center, such as call center management (CCM) and customer relationship management (CRM) platforms. By analyzing this data in real-time, they can quickly identify patterns or trends that may indicate areas for improvement.
With the use of cloud computing, bigdata and machine learning (ML) tools like Amazon Athena or Amazon SageMaker have become available and useable by anyone without much effort in creation and maintenance. For instance, you can extract or filter specific dates or timestamps from the data that are not relevant.
This is Part 2 of a series on using data analytics and ML for Amp and creating a personalized show recommendation list platform. The platform has shown a 3% boost to customer engagement metrics tracked (liking a show, following a creator, enabling upcoming show notifications) since its launch in May 2022.
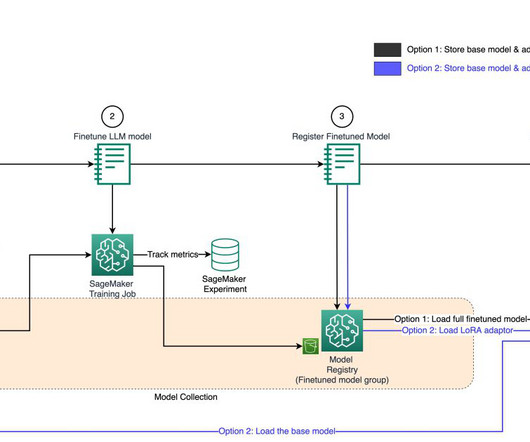
Build, train, evaluate, and register the first version of the model package version (for example, Customer Churn V1). As you iterate on new model package version, clone the model card from the previous version and link to the new model package version (for example, Customer Churn V2). Model cards have versions associated with them.
to run a test on local data after updating the model weights. He entered the bigdata space in 2013 and continues to explore that area. Her specialization is machine learning, and she is actively working on designing solutions using various AWS ML, bigdata, and analytics offerings.
Some hints: bigdata, omnichannel, personalisation, AI and organizational culture. In my opinion, three things that are essential for CX in 2018 include: Restoring trust – 2017 has seen more examples of organizations continuing to fail to meet basic customer expectations. data security, gig economy, AI, machine learning).”
Strategy for customer success growth has changed as commerce has gone digital and bigdata has made marketing and sales customer-centric. Start by implementing a customer feedback program to gather important data and identify unhappy customers. In the old days, growing your business was easy.
As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). We also illustrate how you can track your pipeline workflow and generate metrics and comparison charts.
Companies use advanced technologies like AI, machine learning, and bigdata to anticipate customer needs, optimize operations, and deliver customized experiences. Scope Limited to data and documents. Example Scanning paper files into PDFs. Now, think beyond travelthis same principle applies to every industry.
In their answers to the following questions, they should be addressing chatbots, self-service, machine learning, bigdata, and more. 5 What KPIs/metrics do you measure in tracking the effectiveness of your escalations from AI to live agent? 8 What KPIs or other metrics do you use to assess the performance of your AI tools? #9
To achieve this, companies want to understand industry trends and customer behavior, and optimize internal processes and data analyses on a routine basis. When looking at these metrics, business analysts often identify patterns in customer behavior, in order to determine whether the company risks losing the customer.
For example, a model predicting direct mail propensity is quite different from a model predicting discount coupon sensitivity of the customers of a Vericast client. The managed cluster, instances, and containers report metrics to Amazon CloudWatch , including usage of GPU, CPU, memory, GPU memory, disk metrics, and event logging.
For example, model builders need to proactively record model specifications such as intended use for a model, risk rating, and performance criteria a model should be measured against. With the SageMaker Python SDK, you can seamlessly update the Model card with evaluation metrics. intended_uses="Not used except this test.",
Furthermore, the integration of digital technologies, including artificial intelligence, blockchain, and bigdata, augments these ESG capabilities. Panel Data Models: These incorporate both time-series and cross-sectional elements, allowing for the examination of changes within entities over time.
For example, when financial institutions use ML models to perform fraud detection analysis, they can use low-code and no-code solutions to enable rapid iteration of fraud detection models to improve efficiency and accuracy. Enter a name for the dataset (for example, Banking-Customer-DataSet), then choose Export. Choose Create.
Amp wanted a scalable data and analytics platform to enable easy access to data and perform machine leaning (ML) experiments for live audio transcription, content moderation, feature engineering, and a personal show recommendation service, and to inspect or measure business KPIs and metrics. Data Engineer for Amp on Amazon.
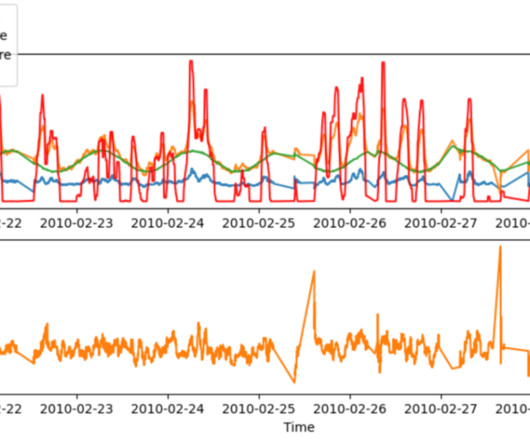
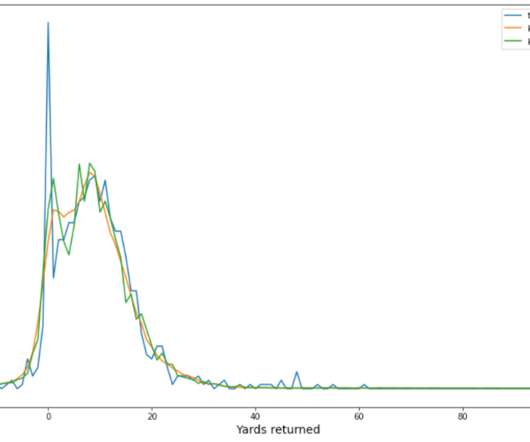
The data distribution for punt and kickoff are different. For example, the true yardage distribution for kickoff and punts are similar but shifted, as shown in the following figure. Data preprocessing and feature engineering First, the tracking data was filtered for just the data related to punts and kickoff returns.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content