This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With this solution, you can interact directly with the chat assistant powered by AWS from your Google Chat environment, as shown in the following example. Run the script init-script.bash : chmod u+x init-script.bash./init-script.bash The script deploys the AWS CDK project in your account.
Challenges in data management Traditionally, managing and governing data across multiple systems involved tedious manual processes, custom scripts, and disconnected tools. This approach was not only time-consuming but also prone to errors and difficult to scale.
It includes processes for monitoring model performance, managing risks, ensuring data quality, and maintaining transparency and accountability throughout the model’s lifecycle. Data preparation For this example, you will use the South German Credit dataset open source dataset.
In this post, we walk you through an example of how to build and deploy a custom Hugging Face text summarizer on SageMaker. The map function iterates over the loaded dataset and applies the tokenize function to each example. Build your training script for the Hugging Face SageMaker estimator. return tokenized_dataset.
We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw. For example, to use the RedPajama dataset, use the following command: wget [link] python nemo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py
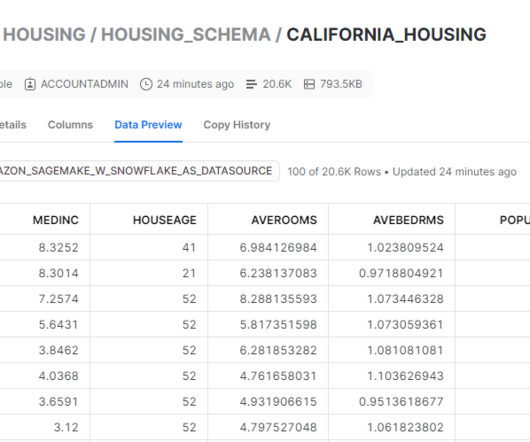
We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket. Select the notebook aws-aiml-blogpost-sagemaker-snowflake-example and choose Open JupyterLab. All code for this post is available in the GitHub repo.
The following code shows an example of how a query is configured within the config.yml file. This query is used at the data processing step of the training pipeline to fetch data from the PrestoDB instance. For more information on processing jobs, see Process data.
The framework code and examples presented here only cover model training pipelines, but can be readily extended to batch inference pipelines as well. You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices. script is used by pipeline_service.py The model_unit.py
For example, companies can ask their call agents to check on their customers concerning the pandemic. An example of this would be doing A/B testing on how long you keep a consumer in an ACD compared to talking to a rep. Examples would be: Selling products. This can improve team performance, thus improving the brand image.
A Harvard Business Review study found that companies using bigdata analytics increased profitability by 8%. While this statistic specifically addresses data-centric strategies, it highlights the broader value of well-structured technical investments. Real-world examples show how they solve problems and adapt to new challenges.
The predictions (inference) use encrypted data and the results are only decrypted by the end consumer (client side). To demonstrate this, we show an example of customizing an Amazon SageMaker Scikit-learn, open sourced, deep learning container to enable a deployed endpoint to accept client-side encrypted inference requests.
Today, CXA encompasses various technologies such as AI, machine learning, and bigdata analytics to provide personalized and efficient customer experiences. One early example were email autoresponders that sent out immediate confirmations of receipt. For example, Klarna has saved $40M annually since implementing AI agents.
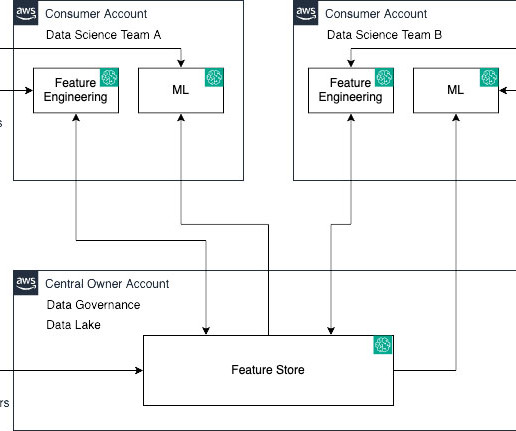
SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. Customers can also access offline store data using a Spark runtime and perform bigdata processing for ML feature analysis and feature engineering use cases. Table formats provide a way to abstract data files as a table.
For example, you can add custom terminology glossaries, while for LLMs, you might need fine-tuning that can be labor-intensive and costly. We use the custom terminology dictionary to compile frequently used terms within video transcription scripts. Here’s an example. Yaoqi Zhang is a Senior BigData Engineer at Mission Cloud.
We live in an era of bigdata, AI, and automation, and the trends that matter in CX this year begin with the abilities – and pain points – ushered in by this technology. For example, bigdata makes things like hyper-personalized customer service possible, but it also puts enormous stress on data security.
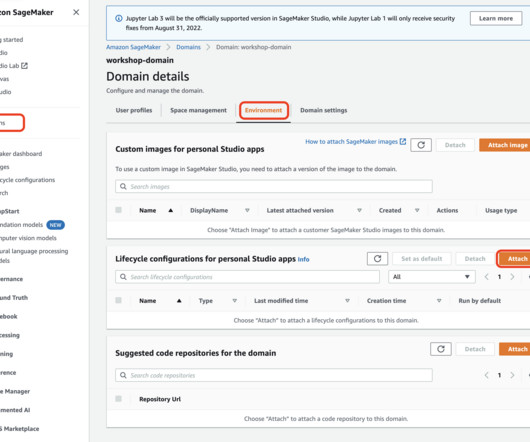
A public GitHub repo provides hands-on examples for each of the presented approaches. When you open a notebook in Studio, you are prompted to set up your environment by choosing a SageMaker image, a kernel, an instance type, and, optionally, a lifecycle configuration script that runs on image startup. Define a Dockerfile.
uses ROPE with partial rotation, for example, rotating 25% of the head dimensions and keeping the rest unrotated. After downloading the latest Neuron NeMo package, use the provided neox and pythia pre-training and fine-tuning scripts with optimized hyper-parameters and execute the following for a four node training.
Refer to notebook examples for SageMaker algorithms – SageMaker provides a suite of built-in algorithms to help data scientists and ML practitioners get started with training and deploying ML models quickly. For example, with the input “Garden painted in impressionist style,” we get the following output image.
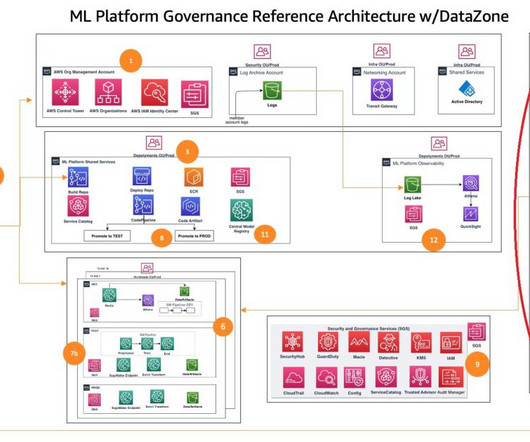
For example, in an application that recommends a music playlist, features could include song ratings, listening duration, and listener demographics. For example, the analytics team may curate features like customer profile, transaction history, and product catalogs in a central management account.
Terraform is used to create additional resources such as EventBridge rules, Lambda functions, and SNS topics for monitoring SageMaker pipelines and sending notifications (for example, when a pipeline step fails or succeeds). SageMaker Pipelines serves as the orchestrator for ML model training and inference workflows.
Refer to notebook examples for SageMaker algorithms – SageMaker provides a suite of built-in algorithms to help data scientists and ML practitioners get started with training and deploying ML models quickly. We now go over a quick example of how you can replicate the preceding process. Fine-tune the pre-trained model.
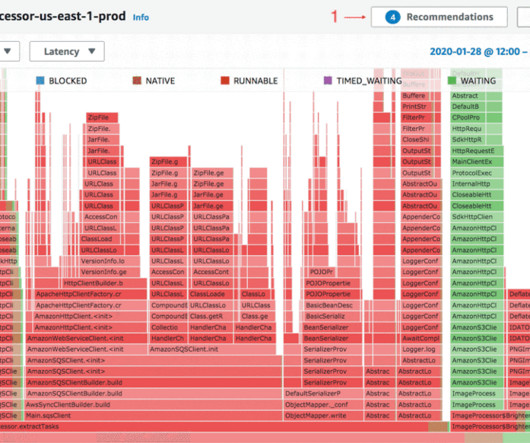
Amazon SageMaker offers several ways to run distributed data processing jobs with Apache Spark, a popular distributed computing framework for bigdata processing. install-scripts chmod +x install-history-server.sh./install-history-server.sh The following screenshot shows an example of the Spark UI.
Developers usually test their processing and training scripts locally, but the pipelines themselves are typically tested in the cloud. One of the main drivers for new innovations and applications in ML is the availability and amount of data along with cheaper compute options.
Refer to notebook examples for SageMaker algorithms – SageMaker provides a suite of built-in algorithms to help data scientists and ML practitioners get started with training and deploying ML models quickly. In this section, we go over a quick example of how you can replicate the preceding process with the SageMaker SDK.
You can also find the script on the GitHub repo. Provide the following parameters for the stack: Stack name – The name of the CloudFormation stack (for example, AmazonQ-UI-Demo ). For example, you could introduce custom feedback handling features. AuthName – A globally unique name to assign to the Amazon Cognito user pool.
Amazon CodeWhisperer currently supports Python, Java, JavaScript, TypeScript, C#, Go, Rust, PHP, Ruby, Kotlin, C, C++, Shell scripting, SQL, and Scala. times more energy efficient than the median of surveyed US enterprise data centers and up to 5 times more energy efficient than the average European enterprise data center.
To create these packages, run the following script found in the root directory: /build_mlops_pkg.sh to run a test on local data after updating the model weights. He entered the bigdata space in 2013 and continues to explore that area. You can update this to any value of your choice.
Real-world data is complex and interconnected, and often contains network structures. Examples include molecules in nature, social networks, the internet, roadways, and financial trading platforms. An end-to-end solution with Amazon SageMaker was also deployed. Benefits of graph machine learning.
Security is a big-data problem. One notable example is the detection and elimination of files that were cunningly laced with malware, where the datasets are in terabytes. As soon as a download attempt is made, it triggers the malicious executable script to connect to the attacker’s Command and Control server.
For example, in Great Britain, a self-serving Sainsbury's opened in 1950. We are also seeing the influx of bigdata and the switch to mobile. For example, the latest research from Accenture showed that 83% of US consumers prefer dealing with humans. More Recent Milestones. Human biology.
Usually, if the dataset or model is too large to be trained on a single instance, distributed training allows for multiple instances within a cluster to be used and distribute either data or model partitions across those instances during the training process. We use a VPC peering configuration within the Region in this example.
For example, to allow SageMaker to call Amazon Elastic Container Registry (Amazon ECR), the Amazon ECR interface VPC endpoint can be provisioned in the shared services account VPC, and a forwarding rule is shared with the SageMaker accounts that need to consume it. He helps customers migrate bigdata and AL/ML workloads to AWS.
For example, if a user has systems administrator as the default role in their Snowflake profile, the connection from Data Wrangler to Snowflake uses systems administrator as the role. A Lifecycle Configuration is a shell script that automatically loads the credentials stored in the secret when the user logs into Studio.
As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). An experiment owned by the data science team regarding marketing analytics, for example.
Before you can write scripts that use the Amazon Bedrock API, you’ll need to install the appropriate version of the AWS SDK in your environment. His expertise is in building BigData and AI-powered solutions to customer problems especially in biomedical, life sciences and healthcare domain. Nihir Chadderwala is a Sr.
We provide examples demonstrating experiment tracking and using the model registry with MLflow from SageMaker training jobs and Studio, respectively, in the provided notebook. The following code is an example of the buildspec.yaml file: version: "1.0" How to use MLflow as a centralized repository in a multi-account setup.
There is where data analysis comes in, you can use the data your company has, and key performance indicators (KPIs) to indicate what path you should follow. For example, a company is about to launch a new product and the marketing is developing an email marketing campaign for that.
Prior to our adoption of Kubeflow on AWS, our data scientists used a standardized set of tools and a process that allowed flexibility in the technology and workflow used to train a given model. Each project maintained detailed documentation that outlined how each script was used to build the final model.
While 8 different teams are listed above, let’s take just one example in the area of CX design. Here is a call into emergency roadside assistance prior to the CX design work from Hollywood script writers. In fact, once you “go live,” you’ve only started. Here is that same call after it went through our CX design team.
Data propagated to the recently-released Teradata Integrated BigData Platform 1800 provides access to large volumes of data with its native support of JSON (Java Script Object Notation) data. Data propagated to Hadoop® can be analyzed at scale with Teradata Aster Analytics on Hadoop.
Amp stakeholders require this data to power ML processes or predictive models, content moderation tools, and product and program dashboards (for example, trending shows). Streaming data enables Amp customers to conduct and measure experimentation. Data Engineer for Amp on Amazon. Key benefits. Jeff Christophersen is a Sr.
” As an internet-based retailer, Amazon provides a great example for e-commerce professionals who want to know how they can provide customer service in mold-breaking ways. How to Revolutionize Customer Employee Engagement with BigData and Gamification by Rajat Paharia. Loyalty 3.0:
But modern analytics goes beyond basic metricsit leverages technologies like call center data science, machine learning models, and bigdata to provide deeper insights. Predictive Analytics: Uses historical data to forecast future events like call volumes or customer churn. angry, confused).
For example, on online shopping platforms, the angle at which products are shown in images has an effect on the rate of buying this product. It can be used for further postprocessing on the image, for example, to crop out the whole car. Two components need to be configured in our inference script : model loading and model serving.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content