This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
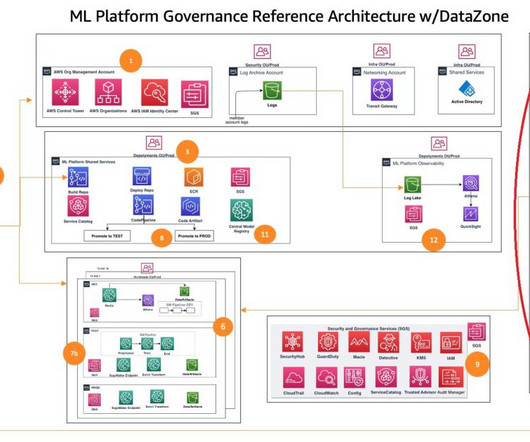
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up datagovernance at scale using Amazon DataZone for the data mesh. However, as data volumes and complexity continue to grow, effective datagovernance becomes a critical challenge.
This streamlines the ML workflows, enables better visibility and governance, and accelerates the adoption of ML models across the organization. Before we dive into the details of the architecture for sharing models, let’s review what use case and model governance is and why it’s needed.
Model governance – The Amazon SageMaker Model Registry integration allows for tracking model versions, and therefore promoting them to production with confidence. You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices. script is used by pipeline_service.py The model_unit.py
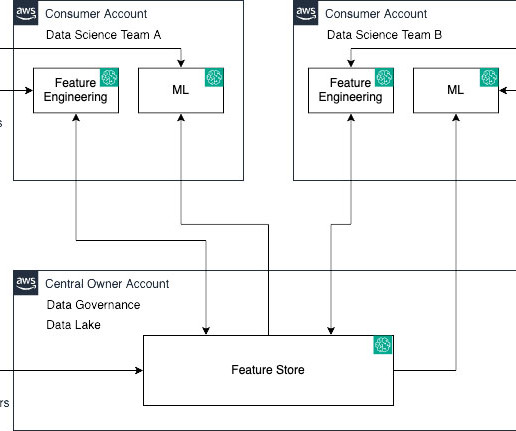
Who needs a cross-account feature store Organizations need to securely share features across teams to build accurate ML models, while preventing unauthorized access to sensitive data. SageMaker Feature Store now allows granular sharing of features across accounts via AWS RAM, enabling collaborative model development with governance.
Customers can also access offline store data using a Spark runtime and perform bigdata processing for ML feature analysis and feature engineering use cases. Table formats provide a way to abstract data files as a table. Next, you need to create a Python script to run the Iceberg procedures. AWS Glue Job setup.
default_bucket() upload _path = f"training data/fhe train.csv" boto3.Session().resource("s3").Bucket To see more information about natively supported frameworks and script mode, refer to Use Machine Learning Frameworks, Python, and R with Amazon SageMaker. resource("s3").Bucket Bucket (bucket).Object Object (upload path).upload
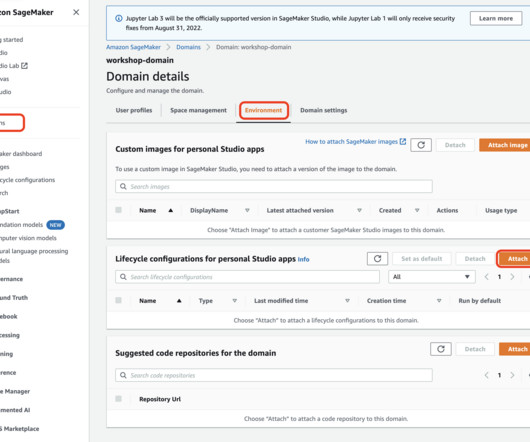
When you open a notebook in Studio, you are prompted to set up your environment by choosing a SageMaker image, a kernel, an instance type, and, optionally, a lifecycle configuration script that runs on image startup. You can implement comprehensive tests, governance, security guardrails, and CI/CD automation to produce custom app images.
RFPs for chatbots have arisen in verticals as diverse as banking, government, healthcare, and retail. In 2018, we should see much better integration with customer data and analytics, bringing customer history, behavioral patterns, and bigdata into chatbot interactions.
These customers need to balance governance, security, and compliance against the need for machine learning (ML) teams to quickly access their data science environments in a secure manner. We also introduce a logical construct of a shared services account that plays a key role in governance, administration, and orchestration.
It offers many native capabilities to help manage ML workflows aspects, such as experiment tracking, and model governance via the model registry. This can be a challenge for enterprises in regulated industries that need to keep strong model governance for audit purposes. You can use this script add_users_and_groups.py
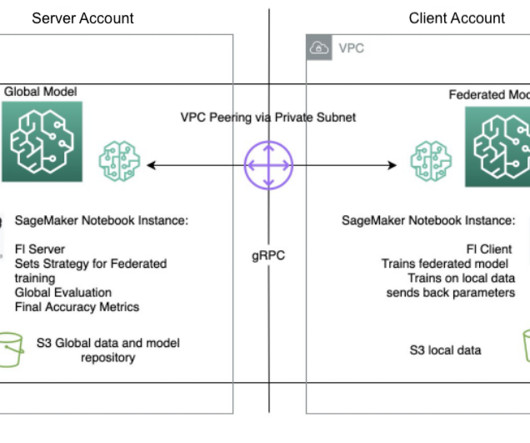
The notebook instance client starts a SageMaker training job that runs a custom script to trigger the instantiation of the Flower client, which deserializes and reads the server configuration, triggers the training job, and sends the parameters response. script and a utils.py The client.py We use utility functions in the utils.py
Before you can write scripts that use the Amazon Bedrock API, you’ll need to install the appropriate version of the AWS SDK in your environment. Information that identifies you may be shared with doctors responsible for your care or for audits and evaluations by government agencies, but talks and papers about the study will not identify you.
Each project maintained detailed documentation that outlined how each script was used to build the final model. In many cases, this was an elaborate process involving 5 to 10 scripts with several outputs each. These had to be manually tracked with detailed instructions on how each output would be used in subsequent processes.
But modern analytics goes beyond basic metricsit leverages technologies like call center data science, machine learning models, and bigdata to provide deeper insights. Predictive Analytics: Uses historical data to forecast future events like call volumes or customer churn. What is contact center bigdata analytics?
Its incorporating more artificial intelligence solutions for companies interested in benefiting from bigdata and AI insights. With its live answering option, you set up a customized script and forward your calls to Answerforce. Telus Internationals expanding services are reflected in its upcoming name change Telus Digital.
Access Controls: Limit access to sensitive data to only those who need it, and implement appropriate access controls to prevent unauthorized access. Data Retention Policies: Establish clear data retention policies to govern how long data is stored, and how it is securely disposed of once it is no longer needed.
Consider your security posture, governance, and operational excellence when assessing overall readiness to develop generative AI with LLMs and your organizational resiliency to any potential impacts. Define strict data ingress and egress rules to help protect against manipulation and exfiltration using VPCs with AWS Network Firewall policies.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content