This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Run the script init-script.bash : chmod u+x init-script.bash./init-script.bash init-script.bash This script prompts you for the following: The Amazon Bedrock knowledge base ID to associate with your Google Chat app (refer to the prerequisites section). The script deploys the AWS CDK project in your account. Choose Save.
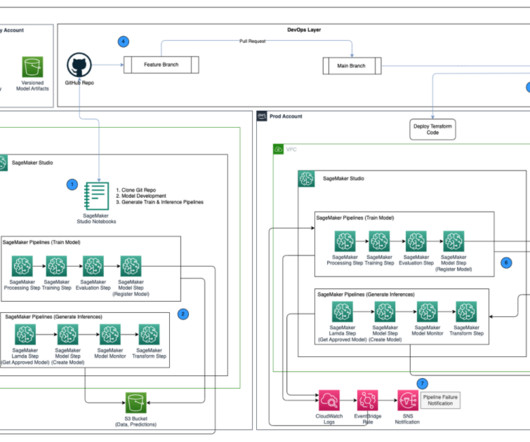
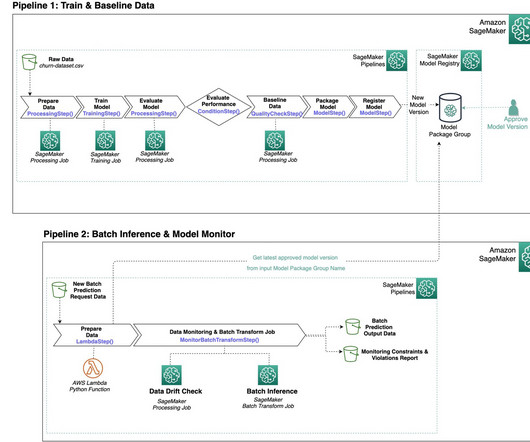
The following diagram depicts an architecture for centralizing model governance using AWS RAM for sharing models using a SageMaker Model Group , a core construct within SageMaker Model Registry where you register your model version. The MLE is notified to set up a model group for new model development.
We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw. Compared to Llama 1, Llama 2 doubles context length from 2,000 to 4,000, and uses grouped-query attention (only for 70B). 4096 2 8 4 1 256 7.4. 4096 4 8 4 1 256 14.6.
You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices. framework/createmodel/ – This directory contains a Python script that creates a SageMaker model object based on model artifacts from a SageMaker Pipelines training step. script is used by pipeline_service.py The model_unit.py
Data preparation and training The data preparation and training pipeline includes the following steps: The training data is read from a PrestoDB instance, and any feature engineering needed is done as part of the SQL queries run in PrestoDB at retrieval time. For more information on processing jobs, see Process data.
Depending on the design of your feature groups and their scale, you can experience training query performance improvements of 10x to 100x by using this new capability. The offline store data is stored in an Amazon Simple Storage Service (Amazon S3) bucket in your AWS account. Creating feature groups using Iceberg table format.
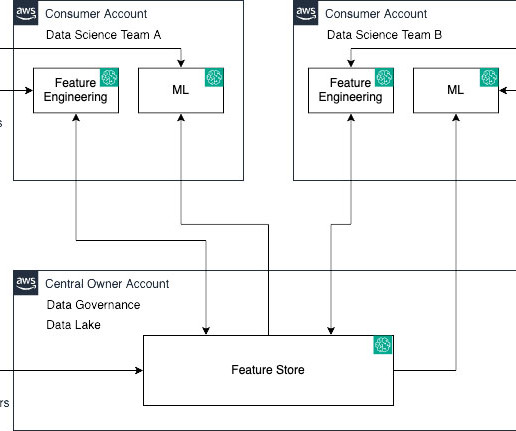
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). For a deep dive, refer to Cross account feature group discoverability and access.
Accordingly, I expect to see a range of new solutions see the light of day in 2018; solutions that bring the old solutions like Interactive Voice Response (cue the robotic ‘press 1 for English’ script) into the 21 st century, on a channel people actually like to use.
You can also find the script on the GitHub repo. After the application is created, go to the application, choose Assign users and groups , and add the users who will have access to the UI application. He helps organizations in achieving specific business outcomes by using data and AI, and accelerating their AWS Cloud adoption journey.
To create these packages, run the following script found in the root directory: /build_mlops_pkg.sh Enter a group name and a project name, then choose OK. He entered the bigdata space in 2013 and continues to explore that area. Choose Create a new project. He also holds an MBA from Colorado State University.
default_bucket() upload _path = f"training data/fhe train.csv" boto3.Session().resource("s3").Bucket To see more information about natively supported frameworks and script mode, refer to Use Machine Learning Frameworks, Python, and R with Amazon SageMaker. resource("s3").Bucket Bucket (bucket).Object Object (upload path).upload
Create a new group and add the app BedrockSlackIntegration. About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice. He helps customers implement bigdata, machine learning, analytics solutions, and generative AI solutions. Choose Save Changes.
Data I/O design SageMaker interacts directly with Amazon S3 for reading inputs and storing outputs of individual steps in the training and inference pipelines. The pipeline will automatically upload Python scripts from the GitLab repository and store output files or model artifacts from each step in the appropriate S3 path.
athenahealth a leading provider of network-enabled software and services for medical groups and health systems nationwide. Each project maintained detailed documentation that outlined how each script was used to build the final model. In many cases, this was an elaborate process involving 5 to 10 scripts with several outputs each.
The Data Analyst Course With the Data Analyst Course, you will be able to become a professional in this area, developing all the necessary skills to succeed in your career. The course also teaches beginner and advanced Python, basics and advanced NumPy and Pandas, and data visualization.
1', base_job_name='mlflow', environment=environment ) Visualize runs and experiments from the MLflow UI After the first deployment is complete, let’s populate the Amazon Cognito user pool with three users, each belonging to a different group, to test the permissions we have implemented. You can use this script add_users_and_groups.py
The Sophos Artificial Intelligence (AI) group (SophosAI) oversees the development and maintenance of Sophos’s major ML security technology. Security is a big-data problem. This translates into colossal threat datasets that the group must work with to best defend customers.
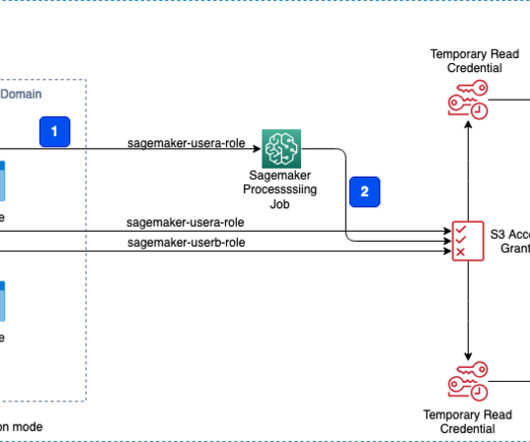
Enterprise customers have multiple lines of businesses (LOBs) and groups and teams within them. These customers need to balance governance, security, and compliance against the need for machine learning (ML) teams to quickly access their data science environments in a secure manner.
As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). Track experiments – Experiments allows data scientists to track experiments.
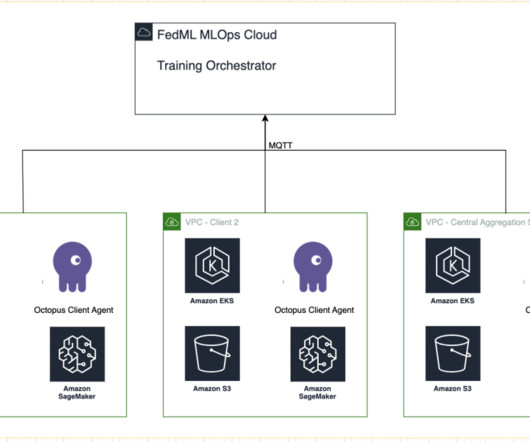
The pipeline allowed Amp data engineers to easily deploy Airflow DAGs or PySpark scripts across multiple environments. Amp used Amazon EMR on Amazon Elastic Kubernetes Service (Amazon EKS) to configure and manage containers for their data processing and transformation jobs. Data Engineer for Amp on Amazon.
But modern analytics goes beyond basic metricsit leverages technologies like call center data science, machine learning models, and bigdata to provide deeper insights. Predictive Analytics: Uses historical data to forecast future events like call volumes or customer churn. angry, confused).
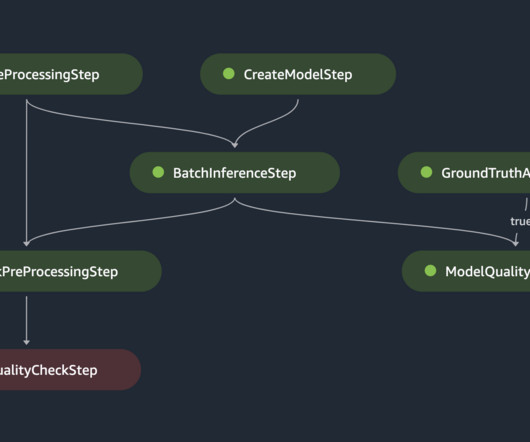
The code sets up the S3 paths for pipeline inputs, outputs, and model artifacts, and uploads scripts used within the pipeline steps. After the train and baseline pipeline run successfully, it registers the trained model as part of the model group in the model registry. Repeat the same for the second custom policy.
It’s also the main type of communication channel that people use to get in touch with customer service representatives across all age groups and countries. Businesses now have the option to create a community or group to send out mass targeted messages. Do you want to gather and record customer data from this interaction?
S3 Access Grants allows data owners or permission administrators to set permissions, such as read-only, write-only, or read/write access, at various levels of Amazon S3, such as at the bucket, prefix, or object level. This will open a new Python notebook, which we use to run the PySpark script. preprocess.py
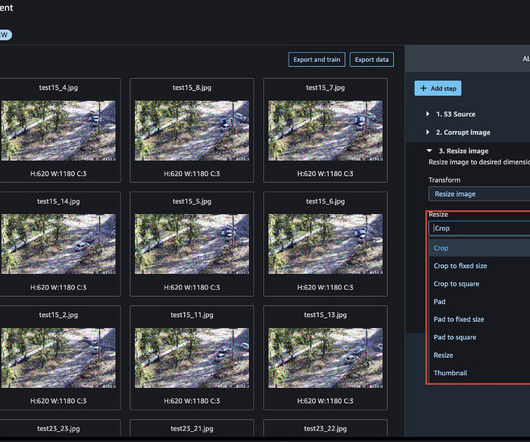
Add a custom transformation to detect and remove image outliers With image preparation in Data Wrangler, we can also invoke another endpoint for another model. You can find some sample scripts with boilerplate code in the Search example snippets section. Lu Huang is a Senior Product Manager on Data Wrangler.
The new SOASTA mPulse enhancements make BigData insights easy to visualize, access and share. Instead of siloing information within groups, SOASTA mPulse with embedded Data Science Workbench reports help enterprises isolate issues, triage performance problems, and make decisions based on a better understanding of the customer. .
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content