This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
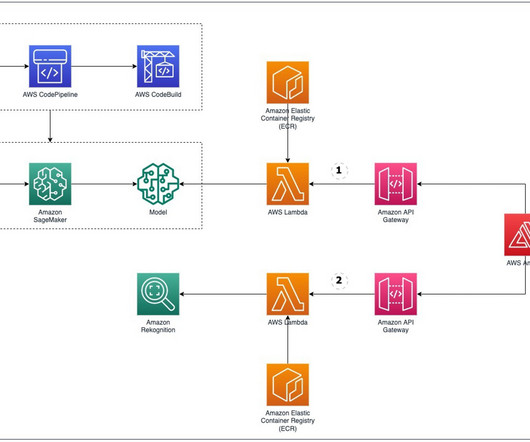
Run the script init-script.bash : chmod u+x init-script.bash./init-script.bash init-script.bash This script prompts you for the following: The Amazon Bedrock knowledge base ID to associate with your Google Chat app (refer to the prerequisites section). The script deploys the AWS CDK project in your account.
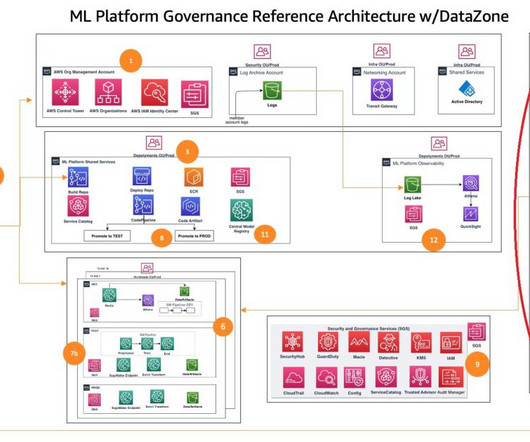
The data mesh architecture aims to increase the return on investments in data teams, processes, and technology, ultimately driving business value through innovative analytics and ML projects across the enterprise. However, as data volumes and complexity continue to grow, effective data governance becomes a critical challenge.
Large language models (LLMs) have captured the imagination and attention of developers, scientists, technologists, entrepreneurs, and executives across several industries. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
This file includes the necessary AWS and PrestoDB credentials to connect to the PrestoDB instance, information on the training hyperparameters and SQL queries that are run at training, and inference steps to read data from PrestoDB. For more information on processing jobs, see Process data.
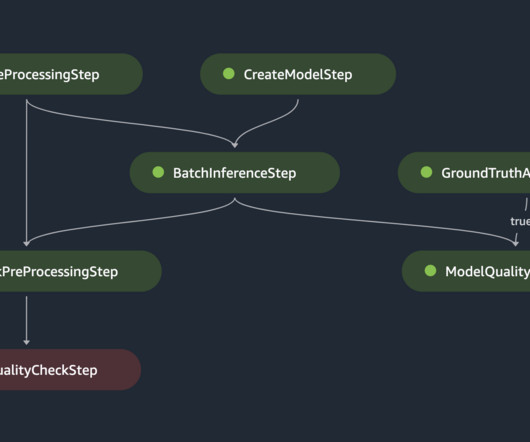
You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices. framework/createmodel/ – This directory contains a Python script that creates a SageMaker model object based on model artifacts from a SageMaker Pipelines training step. script is used by pipeline_service.py The model_unit.py
SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. Customers can also access offline store data using a Spark runtime and perform bigdata processing for ML feature analysis and feature engineering use cases. Table formats provide a way to abstract data files as a table.
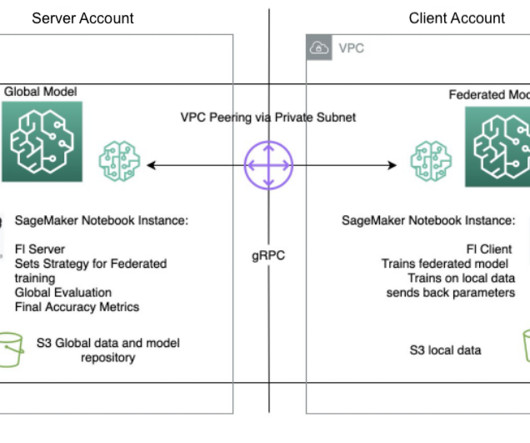
With increased access to data, ML has the potential to provide unparalleled business insights and opportunities. However, the sharing of raw, non-sanitized sensitive information across different locations poses significant security and privacy risks, especially in regulated industries such as healthcare.
We live in an era of bigdata, AI, and automation, and the trends that matter in CX this year begin with the abilities – and pain points – ushered in by this technology. For example, bigdata makes things like hyper-personalized customer service possible, but it also puts enormous stress on data security.
After downloading the latest Neuron NeMo package, use the provided neox and pythia pre-training and fine-tuning scripts with optimized hyper-parameters and execute the following for a four node training. Before joining AWS, he worked at Baidu research as a distinguished scientist and the head of Baidu BigData Laboratory.
Business analysts play an integral role in any industry, but they’re especially vital in call center operations. The business analyst’s role is to evaluate the customer experience and then identify how to improve the customer experience either with software changes or call center script changes.
Much like in 2016, this year I’ve had countless conversations about chatbot needs with numerous customers, prospects, and partners around the globe, and it’s clear to me that as an industry we have made progress. But it’s still early – very early. The result will be more personalized and productive interactions.
Use pre-built solutions – JumpStart provides a set of 17 solutions for common ML use cases, such as demand forecasting and industrial and financial applications, which you can deploy with just a few clicks. We first fetch any additional packages, as well as scripts to handle training and inference for the selected task.
As industries evolve in today’s fast-paced business landscape, the inability to have real-time forecasts poses significant challenges for industries heavily reliant on accurate and timely insights. The triggers need to be scheduled to write the data to S3 at a period frequency based on the business need for training the models.
However, traditional dubbing methods are costly ( about $20 per minute with human review effort ) and time consuming, making them a common challenge for companies in the Media & Entertainment (M&E) industry. We use the custom terminology dictionary to compile frequently used terms within video transcription scripts.
Leaders across industries recognize the growing role of cloud solutions in shaping business strategies. A Harvard Business Review study found that companies using bigdata analytics increased profitability by 8%. Provide a short assignment, such as setting up a test environment or writing scripts to automate deployments.
Like many industries, the corporate bond market doesn’t lend itself to a one-size-fits-all approach. We found that we didn’t need to separate data preparation, model training, and prediction, and it was convenient to package the whole pipeline as a single script and use SageMaker processing.
You can also find the script on the GitHub repo. He has extensive experience across bigdata, data science, and IoT, across consulting and industrials. He is an advocate of cloud-centered data and ML platforms and the value they can drive for customers across industries.
Use pre-built solutions – JumpStart provides a set of 17 solutions for common ML use cases, such as demand forecasting and industrial and financial applications, which you can deploy with just a few clicks. We first fetch any additional packages, as well as scripts to handle training and inference for the selected task.
Data I/O design SageMaker interacts directly with Amazon S3 for reading inputs and storing outputs of individual steps in the training and inference pipelines. The pipeline will automatically upload Python scripts from the GitLab repository and store output files or model artifacts from each step in the appropriate S3 path.
Use pre-built solutions – JumpStart provides a set of 17 solutions for common ML use cases, such as demand forecasting and industrial and financial applications, which you can deploy with just a few clicks. We fetch any additional packages, as well as scripts to handle training and inference for the selected task.
Amazon CodeWhisperer currently supports Python, Java, JavaScript, TypeScript, C#, Go, Rust, PHP, Ruby, Kotlin, C, C++, Shell scripting, SQL, and Scala. times more energy efficient than the median of surveyed US enterprise data centers and up to 5 times more energy efficient than the average European enterprise data center.
During each training iteration, the global data batch is divided into pieces (batch shards) and a piece is distributed to each worker. Each worker then proceeds with the forward and backward pass defined in your training script on each GPU. He has been a thought leader and speaker, and has been in the industry for nearly 25 years.
How to Revolutionize Customer Employee Engagement with BigData and Gamification by Rajat Paharia. focuses on how to use bigdata and gamification to engage your customers more than ever before. With The Customer Service Revolution, you might just be able to make that kind of presence within your industry.
The 2000s hit the CRM industry as hard as any other software-based industry due to the dot-com bubble bursting so epically. We are also seeing the influx of bigdata and the switch to mobile. There are companies that are working on analytic methods which can work with copious amounts of data. Human biology.
You have a unique view on the CX industry as a former technology director. Normally the work that I’m doing, yeah, it does sort of split between my own personal pet sort of projects, the latest book I’m working on or something, and the kind of working with industry leaders. Thanks for joining me.
Machine learning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed. script and a utils.py
Before you can write scripts that use the Amazon Bedrock API, you’ll need to install the appropriate version of the AWS SDK in your environment. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Nihir Chadderwala is a Sr.
Teradata Listener is intelligent, self-service software with real-time “listening ” capabilities to follow multiple streams of sensor and IoT data wherever it exists globally, and then propagate the data into multiple platforms in an analytical ecosystem. Teradata Integrated BigData Platform 1800.
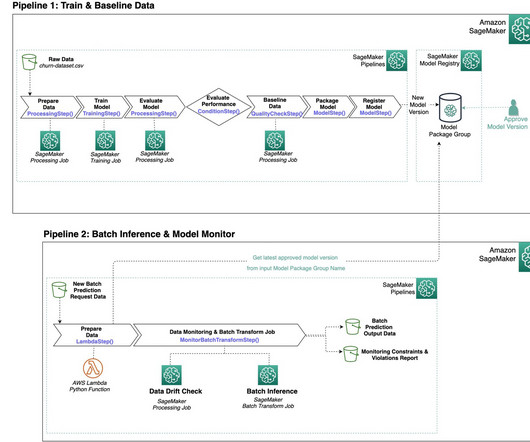
As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). At the start, the process is full of uncertainty and is highly iterative.
Configure SageMaker Studio You store the fields and values in a Secrets Manager secret and add it to the Studio Lifecycle Configuration that you’re using for Data Wrangler. A Lifecycle Configuration is a shell script that automatically loads the credentials stored in the secret when the user logs into Studio. Choose Jupyter server app.
This can be a challenge for enterprises in regulated industries that need to keep strong model governance for audit purposes. You can use this script add_users_and_groups.py After running the script, if you check the Amazon Cognito user pool on the Amazon Cognito console, you should see the three users created.
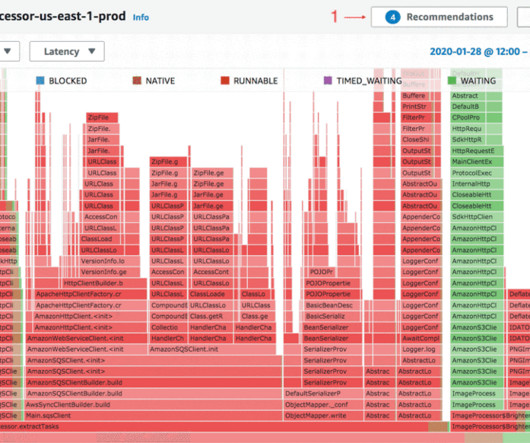
Each project maintained detailed documentation that outlined how each script was used to build the final model. In many cases, this was an elaborate process involving 5 to 10 scripts with several outputs each. These had to be manually tracked with detailed instructions on how each output would be used in subsequent processes.
Two components need to be configured in our inference script : model loading and model serving. On top, he likes thinking big with customers to innovate and invent new ideas for them. Aamna Najmi is a Data Scientist with AWS Professional Services. Ahmed Mansour is a Data Scientist at AWS Professional Services.
But modern analytics goes beyond basic metricsit leverages technologies like call center data science, machine learning models, and bigdata to provide deeper insights. Predictive Analytics: Uses historical data to forecast future events like call volumes or customer churn. Use Cases of Call Center Analytics 1.
This preference spans across all industries. Just as bigdata allows marketers to segment their audience by interest and appeal to those interests separately, adaptive selling allows sales people to tailor their approach too. 80% of consumers surveyed said they would rather buy from a brand that offered personalized experiences.
The modern call center is facing unprecedented challenges, especially with rising customer expectations, increased market competitiveness in many industries, and potential hires seeking a healthy work environment that encourages growth. Nowadays, most customers prefer buying from businesses that cater to their unique needs and priorities.
The code sets up the S3 paths for pipeline inputs, outputs, and model artifacts, and uploads scripts used within the pipeline steps. She has been in technology for 24 years spanning multiple industries, technologies, and roles. Shelbee is a co-creator and instructor of the Practical Data Science specialization on Coursera.
To maintain your customers’ and prospects’ confidence, personalize your scripts by piquing their interests. The bulk gathering and fine-tuning of consumer data (bigdata) can open up new possibilities in the field of predictive analysis, allowing smart data to intelligently anticipate the client’s next requirements.
Telus International Based in Canada, Telus International provides IT and customer service outsourcing support to customers in industries such as technology, media, games, e-commerce, and healthcare. Its incorporating more artificial intelligence solutions for companies interested in benefiting from bigdata and AI insights.
Interestingly, it’s the communication channel least favored by e-commerce consumers, according to our latest industry surveys. . If you’ve ever encountered a customer support agent who’s been using a script, then you know how frustrated your customers will feel if your agents do the same. Leverage Digital Programs and Tools.
Meanwhile, customer to interact with industries a variety of different channels. Use BigData Analytics to Your Advantage. The best power of data is across all information sources. Sometimes data itself will make recommendations for call routing. Besides, the customer reps and matches, scripts selling.
For example, conversation intelligence tools can automatically scan conversations and detect whether any agents are deviating from the script. The disruption that AI caused in sales enablement and other industries paved the way for the introduction of revenue intelligence as a separate class of tech solutions.
With the customer service industry is no exception, as technological advancement. Huge Data Analytics. With today trend towards a bigdata analytics is also helping thing to automate. Utilize the complex data sets from different sources. It gives an impression automation is everywhere these days.
For long, call centers have been performance-based, depending on a combination of well-thought scripting and close supervision to reduce call times and maximize first-call resolution. Additionally, there are several other ways the healthcare industry can advance and accelerate productivity. Sign up for our newsletter. contact-form-7].
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content