This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What began as an exploration of contact center reporting, soon became a bigger exercise in the ever-expanding world of BigData, and that has inevitably taken me into the adjacent galaxy of BI – business intelligence. The cloud has changed everything, and that brings us to BigData. The mind boggles.
The Types of Data for Your Metrics. Peppers says there are two different types of data that feed your metrics: Voice of Customer (VOC) Data: Peppers calls these metrics interactive data, meaning your customer interacts with you through a poll. VOC Data Can Be Deceiving Where Numbers Are Not.
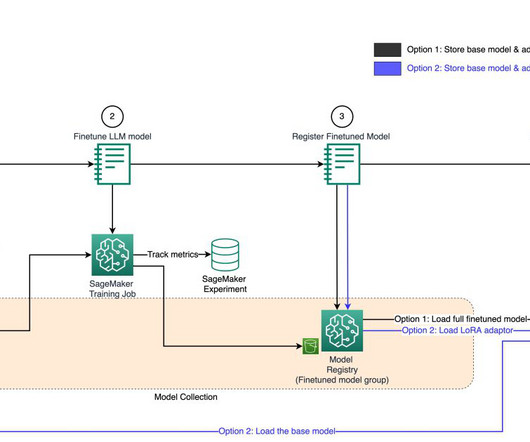
The DS uses SageMaker Training jobs to generate metrics captured by , selects a candidate model, and registers the model version inside the shared model group in their local model registry. You can use the method mlflow.autolog() to log metrics, parameters, and models without the need for explicit log statements.
Bigdata is getting bigger with each passing year, but making sense of trends hidden deep in the heap of 1s and 0s is more confounding than ever. As metrics pile up, you may find yourself wondering which data points matter and in what ways they relate to your business’s interests. The properties of your data.
A recent Calabrio research study of more than 1,000 C-Suite executives has revealed leaders are missing a key data stream – voice of the customer data. Download the report to learn how executives can find and use VoC data to make more informed business decisions.
This post focuses on evaluating and interpreting metrics using FMEval for question answering in a generative AI application. FMEval is a comprehensive evaluation suite from Amazon SageMaker Clarify , providing standardized implementations of metrics to assess quality and responsibility. Question Answer Fact Who is Andrew R.
To evaluate the system health of RCA, the agent runs a series of checks, such as AWS Boto3 API calls (for example, boto3_client.describe_security_groups , to determine if an IP address is allowed to access system) or database SQL queries (SQL: sys.dm_os_schedulers , to query the database system metrics such as CPU, memory or user locks).
Many are actively collecting Voice of Customer (VOC) data through surveys, feedback management, analytics and market research relating to customer retention, loyalty, brand equity and satisfaction. As a result, they are able to create enormous streams and bases of data – known, collectively, as “BigData”.
A 2015 Capgemini and EMC study called “Big & Fast Data: The rise of Insight-Driven Business” showed that: 56% of the 1,000 senior decision makers surveyed claim that their investment in bigdata over the next three years will exceed past investment in information management. ” Bold words indeed!
A 2015 Capgemini and EMC study called “Big & Fast Data: The rise of Insight-Driven Business” showed that: 56% of the 1,000 senior decision makers surveyed claim that their investment in bigdata over the next three years will exceed past investment in information management. ” Bold words indeed!
In this post, we present a framework for automating the creation of a directed acyclic graph (DAG) for Amazon SageMaker Pipelines based on simple configuration files. The framework code and examples presented here only cover model training pipelines, but can be readily extended to batch inference pipelines as well. The model_unit.py
We begin by understanding the feature columns, presented in the following table. To learn more about importing data to SageMaker Canvas, see Import data into Canvas. Choose Import data , then choose Tabular. After a successful import, you will be presented with a preview of the data, which you can browse.
Some hints: bigdata, omnichannel, personalisation, AI and organizational culture. Many organizations are currently enamoured with the promise of technology and bigdata. data security, gig economy, AI, machine learning).” Also, companies really need to transform their structures to reflect customer centricity.
He entered the bigdata space in 2013 and continues to explore that area. He is actively working on projects in the ML space and has presented at numerous conferences, including Strata and GlueCon. Randy has held a variety of positions in the technology space, ranging from software engineering to product management.
Today, CXA encompasses various technologies such as AI, machine learning, and bigdata analytics to provide personalized and efficient customer experiences. This lack of integration can result in data silos, where valuable customer information is not shared across departments, hindering the ability to provide a cohesive service.
However, because multiple teams might use your ML platform in the cloud, monitoring large ML workloads across a scaling multi-account environment presents challenges in setting up and monitoring telemetry data that is scattered across multiple accounts. Consolidate metrics across source accounts and build unified dashboards.
Distributed training is a technique that allows for the parallel processing of large amounts of data across multiple machines or devices. By splitting the data and training multiple models in parallel, distributed training can significantly reduce training time and improve the performance of models on bigdata.
The absence of real-time forecasts in various industries presents pressing business challenges that can significantly impact decision-making and operational efficiency. Amazon SageMaker Canvas access the data to build models and create forecasts. The results of the forecasting are stored in an S3 bucket.
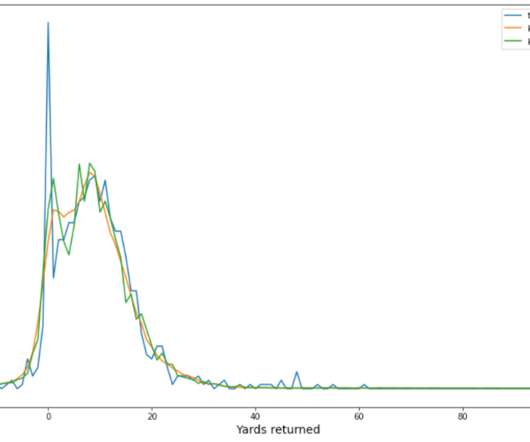
Next, we present the data preprocessing and other transformation methods applied to the dataset. Finally, we present the model performance results. The data preprocessing and feature engineering was adapted from the winner of the NFL BigData Bowl competition on Kaggle. We first describe the dataset used.
Before moving to full-scale production, BigBasket tried a pilot on SageMaker to evaluate performance, cost, and convenience metrics. Use SageMaker Distributed Data Parallelism (SMDDP) for accelerated distributed training. Log model training metrics. Use a custom PyTorch Docker container including other open source libraries.
Observability Besides the resource metrics you typically collect, like CPU and RAM utilization, you need to closely monitor GPU utilization if you host a model on Amazon SageMaker or Amazon Elastic Compute Cloud (Amazon EC2). He entered the bigdata space in 2013 and continues to explore that area.
Monitoring – Logs and metrics around query parsing, prompt recognition, SQL generation, and SQL results should be collected to monitor the text-to-SQL LLM system. In entered the BigData space in 2013 and continues to explore that area. This avoids reprocessing repeated queries. Nitin Eusebius is a Sr. Arghya Banerjee is a Sr.
It provides a unified interface for logging parameters, code versions, metrics, and artifacts, making it easier to compare experiments and manage the model lifecycle. This interface could provide simplified workflows, automating routine tasks and presenting a cohesive view of the entire ML lifecycle.
Textbook knowledge, learning from presentations or listening to co-workers presents limitations when training agents. The contact centre industry is no different from any other and analysing bigdata allows managers to refine output more accurately than ever before. Metrics include: • First call resolution.
Yet, I know that this paradigm shift can present formidable challenges that many organisations struggle to overcome. From reshaping ingrained company cultures to harnessing the power of bigdata, I’ll explore how industry leaders like Toyota, Salesforce, Target and Netflix have successfully navigated these challenges.
In the era of bigdata and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. At the core of these cutting-edge solutions lies a foundation model (FM), a highly advanced machine learning model that is pre-trained on vast amounts of data.
As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). We also illustrate how you can track your pipeline workflow and generate metrics and comparison charts.
Ernest is the Group Product Manager of Data & Analytics at Talkdesk and a session host at the Opentalk 2017 in SF. . The origins of customer satisfaction (or CSAT), as a metric, date back to the 1970s — an era in which the business world was much more obsessed with supply chains and pricing than customers or service.
Ernest is the Group Product Manager of Data & Analytics at Talkdesk and a session host at the Opentalk 2017 in SF. . The origins of customer satisfaction (or CSAT), as a metric, date back to the 1970s — an era in which the business world was much more obsessed with supply chains and pricing than customers or service.
With the SageMaker Python SDK, you can seamlessly update the Model card with evaluation metrics. Model cards provide model risk managers, data scientists, and ML engineers the ability to perform the following tasks: Document model requirements such as risk rating, intended usage, limitations, and expected performance.
Customer Data Platform Benefits. Your customer data platform should be the foundation of all your customer success engagements. To maximize its dynamic data collection and presentation potential, however, you have to customize it according to your enterprise’s priorities. Cause and Effect.
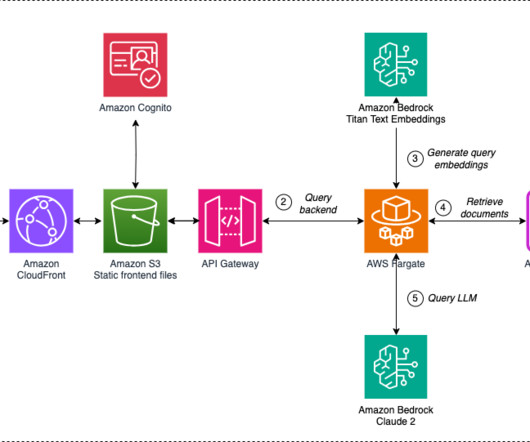
To overcome this limitation and provide dynamism and adaptability to knowledge base changes, we decided to follow a Retrieval Augmented Generation (RAG) approach, in which the LLMs are presented with relevant information extracted from external data sources to provide up-to-date data without the need to retrain the models.
We also demonstrate how to use the generative AI capabilities of SageMaker Canvas to speed up your data exploration and help you build better ML models. Use case overview In this example, a health-tech company offering remote patient monitoring is collecting operational data from wearables using Splunk.
With this high turnover presenting a significant challenge to contact centers in terms of cost, productivity and morale, it is not surprising that there’s an ongoing global trend towards fostering agent development and enhancing their day-to-day activities. Gamification.
This evolution has been driven by advancements in machine learning, natural language processing, and bigdata analytics. Predictive Analytics This technology leverages data, statistical algorithms, and machine learning techniques to identify the likelihood of future outcomes based on historical data.
Instead of coercing these graph datasets into tables or sequences, you can use graph ML algorithms to both represent and learn from the data as presented in its graph form, including information about constituent nodes, edges, and other features. With other standard metrics, the improvement ranged from 50–130%.
This evolution has been driven by advancements in machine learning, natural language processing, and bigdata analytics. Predictive Analytics This technology leverages data, statistical algorithms, and machine learning techniques to identify the likelihood of future outcomes based on historical data.
The Constellation ShortList presents vendors in different categories of the market relevant to early adopters. They make sure the application’s performance doesn’t become a roadblock to optimal customer experiences and reaching business metrics, including conversion rates, high availability and high user experience indexes.
Companies use advanced technologies like AI, machine learning, and bigdata to anticipate customer needs, optimize operations, and deliver customized experiences. Creating robust data governance frameworks and employing tools like machine learning, businesses tend derive actionable insights to achieve a competitive edge.
Using BigData to Make Leadership Advances in the Workplace. While surveys that lead to these results are historically what we’ve had to understand engagement metrics, analytics are far more important. According to a recent Gallup poll, 13 percent of employees are actively engaged at work.
Customer satisfaction is a potent metric that directly influences the profitability of an organization. As shown in the screenshot, the information provided by the caller has been preserved and presented to the agent. This call can be answered on the web client to establish two-way audio between the caller and the agent.
Data science uses various metrics like precision, recall, rank, log likelihood, and information gain. These metrics don’t always align with each other or with user experience. Especially in unsupervised learning, useful metrics are rare. Because ML systems aren’t just coded; they’re trained.
SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously. SIMT describes processors that are able to operate on data vectors and arrays (as opposed to just scalars), and therefore handle bigdata workloads efficiently. Tick 2 trade.
A/B testing is used in scenarios where closed loop feedback can directly tie model outputs to downstream business metrics. Shadow testing is used in situations where there is no closed loop feedback mapping a business metric back to a model’s predictions. She is also the Co-Director of Women In BigData (WiBD), Denver chapter.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content