This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
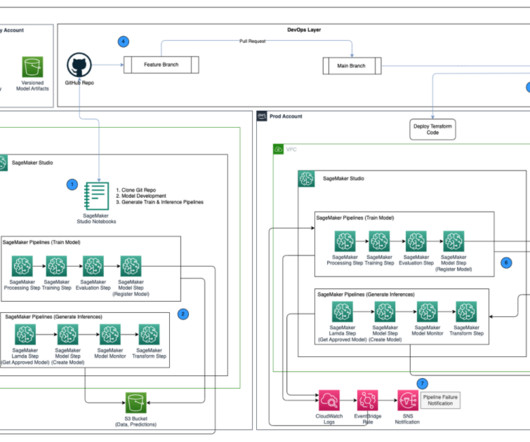
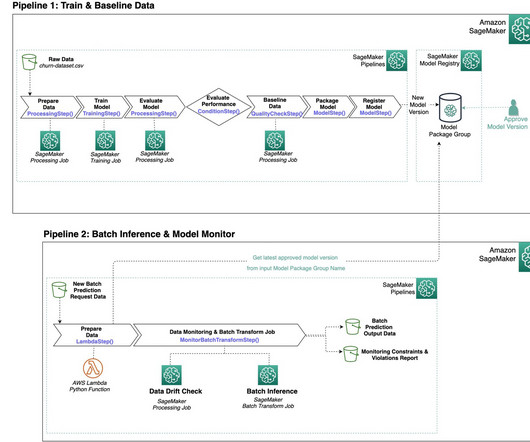
The DS uses SageMaker Training jobs to generate metrics captured by , selects a candidate model, and registers the model version inside the shared model group in their local model registry. Optionally, this model group can also be shared with their test and production accounts if local account access to model versions is needed.
You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices. framework/createmodel/ – This directory contains a Python script that creates a SageMaker model object based on model artifacts from a SageMaker Pipelines training step. script is used by pipeline_service.py The model_unit.py
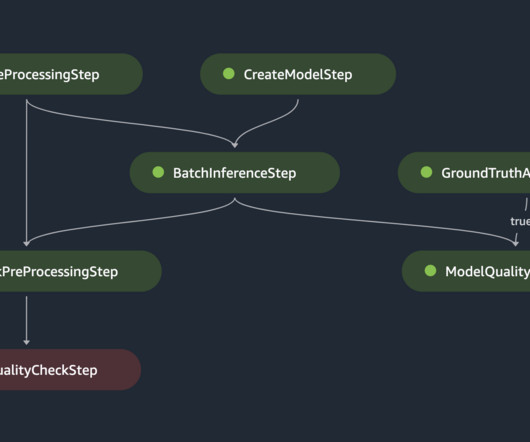
Batch transform The batch transform pipeline consists of the following steps: The pipeline implements a data preparation step that retrieves data from a PrestoDB instance (using a data preprocessing script ) and stores the batch data in Amazon Simple Storage Service (Amazon S3).
They serve as a bridge between IT and other business functions, making data-driven recommendations that meet business requirements and improve processes while optimizing costs. That requires involvement in process design and improvement, workload planning and metric and KPI analysis. Kirk Chewning. kirkchewning.
SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. Customers can also access offline store data using a Spark runtime and perform bigdata processing for ML feature analysis and feature engineering use cases. Table formats provide a way to abstract data files as a table.
Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data. You need data engineering expertise and time to develop the proper scripts and pipelines to wrangle, clean, and transform data. He has a background in AI/ML & bigdata.
Under Advanced Project Options , for Definition , select Pipeline script from SCM. For Script Path , enter Jenkinsfile. upload_file("pipelines/train/scripts/raw_preprocess.py","mammography-severity-model/scripts/raw_preprocess.py") s3_client.Bucket(default_bucket).upload_file("pipelines/train/scripts/evaluate_model.py","mammography-severity-model/scripts/evaluate_model.py")
To create these packages, run the following script found in the root directory: /build_mlops_pkg.sh He entered the bigdata space in 2013 and continues to explore that area. Her specialization is machine learning, and she is actively working on designing solutions using various AWS ML, bigdata, and analytics offerings.
A Harvard Business Review study found that companies using bigdata analytics increased profitability by 8%. While this statistic specifically addresses data-centric strategies, it highlights the broader value of well-structured technical investments.
Today, CXA encompasses various technologies such as AI, machine learning, and bigdata analytics to provide personalized and efficient customer experiences. Moreover, advanced analytics capabilities built into these platforms allow businesses to monitor customer sentiment and track performance metrics in real time.
As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). We also illustrate how you can track your pipeline workflow and generate metrics and comparison charts.
If the model quality metric (for example, RMSE for regression and F1 score for classification) doesn’t meet a pre-specified criterion, the model quality check step is marked as failed. Data I/O design SageMaker interacts directly with Amazon S3 for reading inputs and storing outputs of individual steps in the training and inference pipelines.
Before moving to full-scale production, BigBasket tried a pilot on SageMaker to evaluate performance, cost, and convenience metrics. Use SageMaker Distributed Data Parallelism (SMDDP) for accelerated distributed training. Log model training metrics. Use a custom PyTorch Docker container including other open source libraries.
We found that we didn’t need to separate data preparation, model training, and prediction, and it was convenient to package the whole pipeline as a single script and use SageMaker processing. This was simple and cost-effective for us, because the GPU instance is only used and paid for during the 15 minutes needed for the script to run.
Amp wanted a scalable data and analytics platform to enable easy access to data and perform machine leaning (ML) experiments for live audio transcription, content moderation, feature engineering, and a personal show recommendation service, and to inspect or measure business KPIs and metrics. Data Engineer for Amp on Amazon.
We have also seen an uplift in almost all of our success metrics along the customer journey.”. Founded in 2015 and based in the US and Moldova, Retently helps businesses understand and interact with their customers using Net Promoter Score® (NPS®), a customer satisfaction metric and an alternative to traditional loyalty surveys.
The triggers need to be scheduled to write the data to S3 at a period frequency based on the business need for training the models. When the model is ready, select the model and click on the latest version Review the model metrics and column impact and if you are satisfied with the model performance, click Predict.
Security is a big-data problem. As soon as a download attempt is made, it triggers the malicious executable script to connect to the attacker’s Command and Control server. With the built-in algorithm for XGBoost , you can do this without any additional custom script.
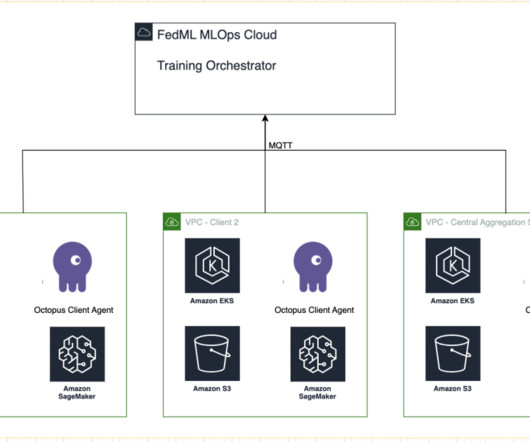
The notebook instance client starts a SageMaker training job that runs a custom script to trigger the instantiation of the Flower client, which deserializes and reads the server configuration, triggers the training job, and sends the parameters response. script and a utils.py The client.py We use utility functions in the utils.py
How to Revolutionize Customer Employee Engagement with BigData and Gamification by Rajat Paharia. focuses on how to use bigdata and gamification to engage your customers more than ever before. Price and Jaffe promote the practice of using the right metrics to identify company points of weaknesses. Loyalty 3.0:
Add a custom transformation to detect and remove image outliers With image preparation in Data Wrangler, we can also invoke another endpoint for another model. You can find some sample scripts with boilerplate code in the Search example snippets section. Lu Huang is a Senior Product Manager on Data Wrangler. alias("emb")).toPandas()
Each project maintained detailed documentation that outlined how each script was used to build the final model. In many cases, this was an elaborate process involving 5 to 10 scripts with several outputs each. For logging, we utilize FluentD to push all our container logs to Amazon OpenSearch Service and system metrics to Prometheus.
But modern analytics goes beyond basic metricsit leverages technologies like call center data science, machine learning models, and bigdata to provide deeper insights. Predictive Analytics: Uses historical data to forecast future events like call volumes or customer churn.
The MLflow Python SDK provides a convenient way to log metrics, runs, and artifacts, and it interfaces with the API resources hosted under the namespace /api/. You can use this script add_users_and_groups.py import boto3 # Session using the SageMaker Execution Role in the Data Science Account session = boto3.Session()
The code sets up the S3 paths for pipeline inputs, outputs, and model artifacts, and uploads scripts used within the pipeline steps. This step uses the built-in ProcessingStep with the provided code, evaluation.py , to evaluate performance metrics (accuracy, area under curve). Repeat the same for the second custom policy.
Then, with the shift towards creating digital experiences in the 2000s, contact centers started implementing simple chatbots that use predefined scripts to help guide the customer and resolve their issues. Nowadays, most customers prefer buying from businesses that cater to their unique needs and priorities.
With in-depth training sessions through e-learning, virtual assistance, and scripting tools, clearly establish company goals and expectations and provide your agents the confidence to tackle any initiative. Call centers have to constantly work to improve their key performance metrics. Bring top-performing agents to training.
mPulse real user monitoring (RUM) collects and analyzes 100% of the front-end performance data from every web and mobile user and correlates this data with critical business metrics – all in real time. The new SOASTA mPulse enhancements make BigData insights easy to visualize, access and share.
Likewise, call centers must strive with this critical metric. Use BigData Analytics to Your Advantage. The best power of data is across all information sources. Sometimes data itself will make recommendations for call routing. Besides, the customer reps and matches, scripts selling. Stitch It All Together.
And you can look at various specific areas such as data analytics, bigdata, being able to study patterns within data, using artificial intelligence or using machine learning to actually gather up every customer interaction, and remember the original problem and the solution.
As the focus of contact center turns to creating value rather than reducing expenses, KPIs like customer satisfaction and service level will become increasingly favored over metrics like Average Handling Time. FCR is the Most Important Metric. 2016: 50% of Global 1000 companies will have stored customer-sensitive data in the cloud.
Amazon SageMaker Studio provides a single web-based visual interface where different personas like data scientists, machine learning (ML) engineers, and developers can build, train, debug, deploy, and monitor their ML models. This will open a new Python notebook, which we use to run the PySpark script. preprocess.py
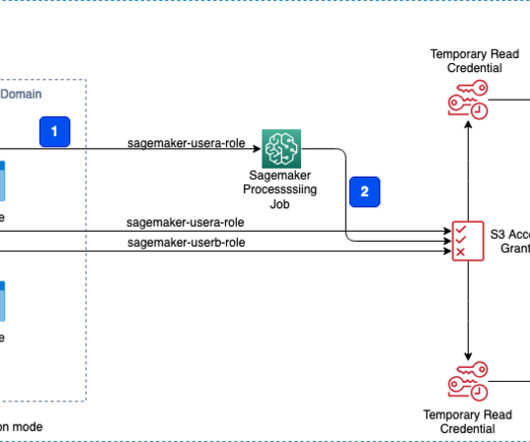
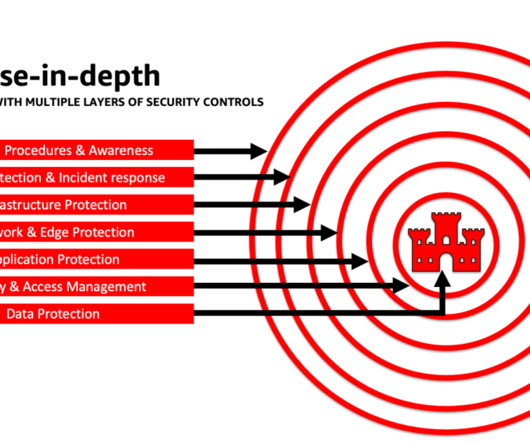
Define strict data ingress and egress rules to help protect against manipulation and exfiltration using VPCs with AWS Network Firewall policies. He is passionate about building secure and scalable AI/ML and bigdata solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes.
The solution can integrate multiple LLMs, use customized evaluation metrics, and enable businesses to continuously monitor model performance. We also provide LLM-as-a-judge evaluation metrics using the newly released Amazon Nova models. The importance of each metric might vary depending on the specific application.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










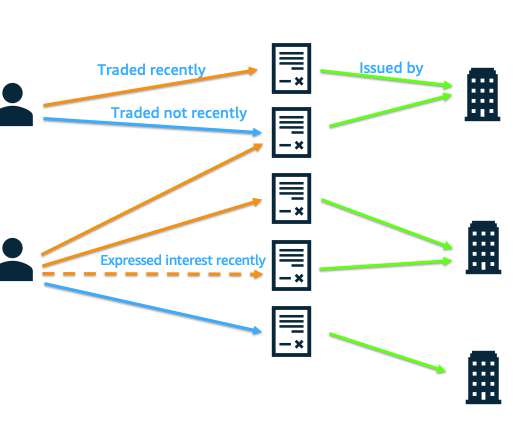


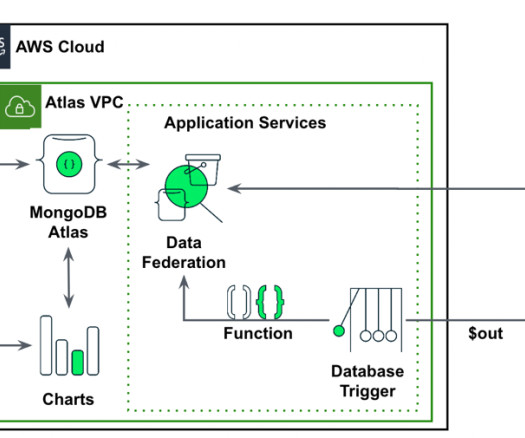

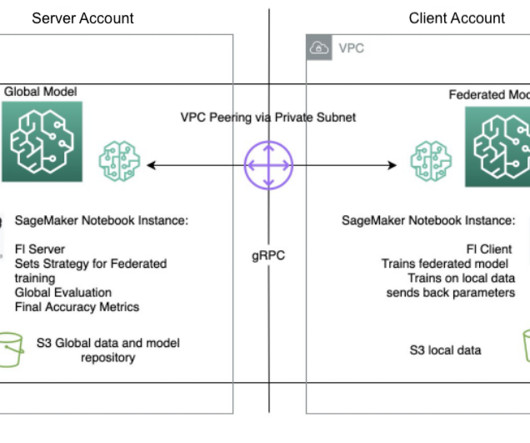

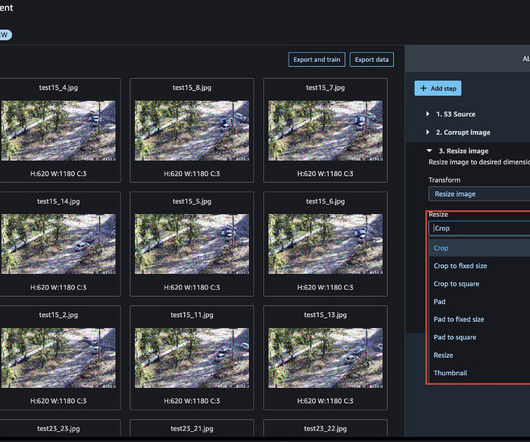

















Let's personalize your content