

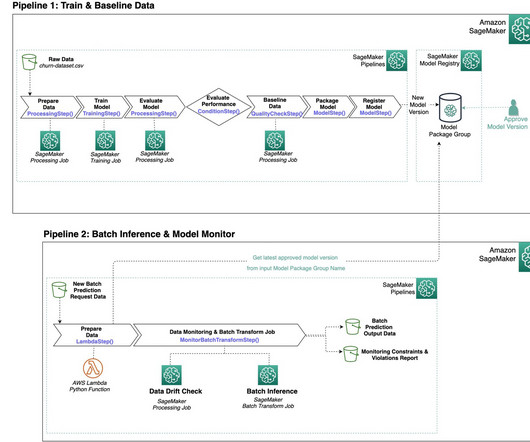
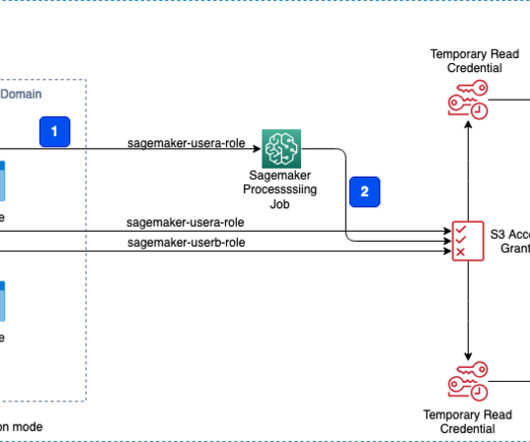
Centralize model governance with SageMaker Model Registry Resource Access Manager sharing
AWS Machine Learning
NOVEMBER 14, 2024
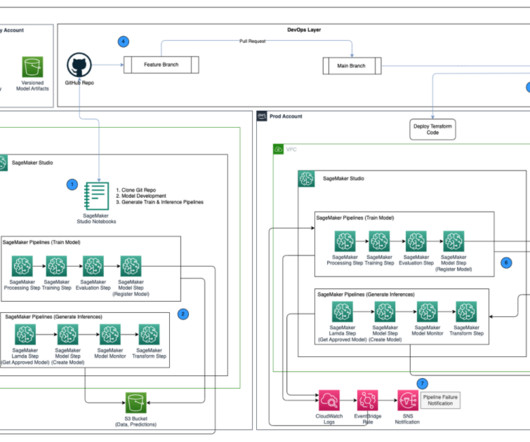
The DS uses SageMaker Training jobs to generate metrics captured by , selects a candidate model, and registers the model version inside the shared model group in their local model registry. Optionally, this model group can also be shared with their test and production accounts if local account access to model versions is needed.





























Let's personalize your content