This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
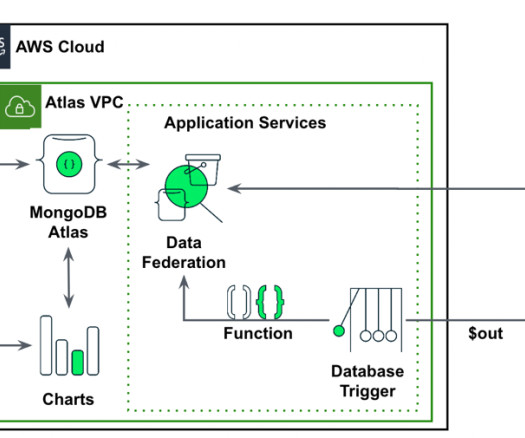
Deploy the solution The application presented in this post is available in the accompanying GitHub repository and provided as an AWS Cloud Development Kit (AWS CDK) project. Run the script init-script.bash : chmod u+x init-script.bash./init-script.bash The script deploys the AWS CDK project in your account.
We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw. For example, to use the RedPajama dataset, use the following command: wget [link] python nemo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py
from time import gmtime, strftime experiment_suffix = strftime('%d-%H-%M-%S', gmtime()) experiment_name = f"credit-risk-model-experiment-{experiment_suffix}" The processing script creates a new MLflow active experiment by calling the mlflow.set_experiment() method with the experiment name above. fit_transform(y).
In this post, we present a framework for automating the creation of a directed acyclic graph (DAG) for Amazon SageMaker Pipelines based on simple configuration files. The framework code and examples presented here only cover model training pipelines, but can be readily extended to batch inference pipelines as well. The model_unit.py
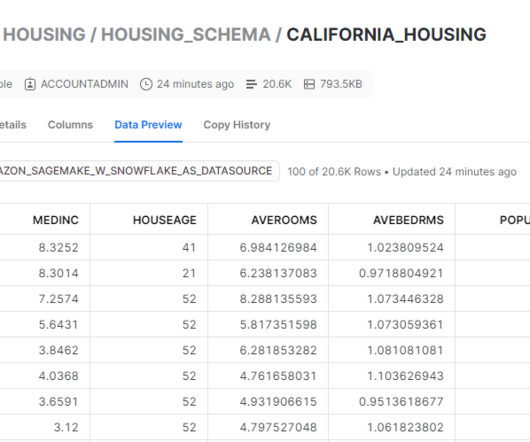
It also provides common ML algorithms that are optimized to run efficiently against extremely large data in a distributed environment. We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket.
Today, CXA encompasses various technologies such as AI, machine learning, and bigdata analytics to provide personalized and efficient customer experiences. This lack of integration can result in data silos, where valuable customer information is not shared across departments, hindering the ability to provide a cohesive service.
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. A public GitHub repo provides hands-on examples for each of the presented approaches. In the Scripts section, define the script to be run when the kernel starts.
We first fetch any additional packages, as well as scripts to handle training and inference for the selected task. You can use any number of models pre-trained on the same task with a single inference script. Finally, the pre-trained model artifacts are separately fetched with model_uris , which provides flexibility to the platform.
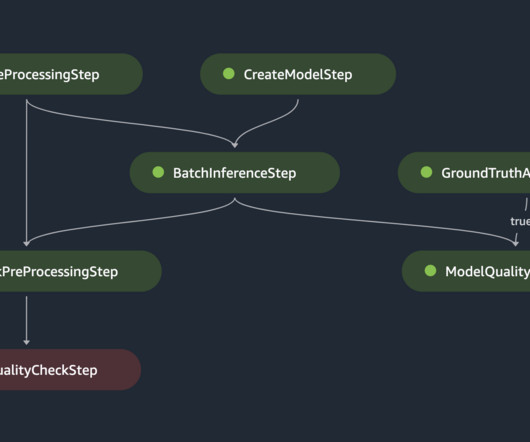
The presented MLOps workflow provides a reusable template for managing the ML lifecycle through automation, monitoring, auditability, and scalability, thereby reducing the complexities and costs of maintaining batch inference workloads in production. Arrows have been color-coded based on pipeline step type to make them easier to read.
We first fetch any additional packages, as well as scripts to handle training and inference for the selected task. You can use any number of models pre-trained on the same task with a single inference script. Finally, the pre-trained model artifacts are separately fetched with model_uris , which provides flexibility to the platform.
To create these packages, run the following script found in the root directory: /build_mlops_pkg.sh He entered the bigdata space in 2013 and continues to explore that area. He is actively working on projects in the ML space and has presented at numerous conferences, including Strata and GlueCon.
The absence of real-time forecasts in various industries presents pressing business challenges that can significantly impact decision-making and operational efficiency. Amazon SageMaker Canvas access the data to build models and create forecasts. The results of the forecasting are stored in an S3 bucket.
We fetch any additional packages, as well as scripts to handle training and inference for the selected task. You can use any number of models pre-trained for the same task with a single training or inference script. Fine-tune the pre-trained model.
Developers usually test their processing and training scripts locally, but the pipelines themselves are typically tested in the cloud. One of the main drivers for new innovations and applications in ML is the availability and amount of data along with cheaper compute options.
Instead of coercing these graph datasets into tables or sequences, you can use graph ML algorithms to both represent and learn from the data as presented in its graph form, including information about constituent nodes, edges, and other features.
During each training iteration, the global data batch is divided into pieces (batch shards) and a piece is distributed to each worker. Each worker then proceeds with the forward and backward pass defined in your training script on each GPU. He has been a thought leader and speaker, and has been in the industry for nearly 25 years.
Saunders' self-serving store enabled customers to browse the items themselves, present them to a cashier and pay for them. We are also seeing the influx of bigdata and the switch to mobile. There are companies that are working on analytic methods which can work with copious amounts of data. Human biology.
The Data Analyst Course With the Data Analyst Course, you will be able to become a professional in this area, developing all the necessary skills to succeed in your career. The course also teaches beginner and advanced Python, basics and advanced NumPy and Pandas, and data visualization.
As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). At the start, the process is full of uncertainty and is highly iterative.
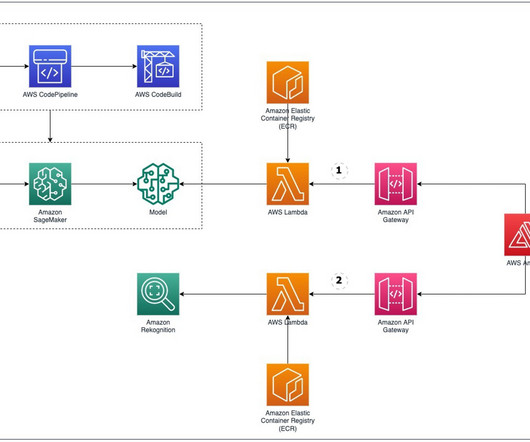
Training ML algorithms for pose estimation requires a lot of expertise and custom training data. Therefore, we present two options: one that doesn’t require any ML expertise and uses Amazon Rekognition, and another that uses Amazon SageMaker to train and deploy a custom ML model. We use deep learning models to solve this problem.
Each project maintained detailed documentation that outlined how each script was used to build the final model. In many cases, this was an elaborate process involving 5 to 10 scripts with several outputs each. These had to be manually tracked with detailed instructions on how each output would be used in subsequent processes.
As a solution, organizations continue to turn to AI, machine learning, NLP and ultimately the production of bigdata to monitor and analyze performance. These results are then delivered straight into the customer’s preferred BI platform, making way for the consolidation of disparate enterprise data for heightened insights.
It’s not that consumers won’t give brands the time of day, it’s that the presentation doesn’t always reach them where it counts. “We Just as bigdata allows marketers to segment their audience by interest and appeal to those interests separately, adaptive selling allows sales people to tailor their approach too.
The new SOASTA mPulse enhancements make BigData insights easy to visualize, access and share. Instead of siloing information within groups, SOASTA mPulse with embedded Data Science Workbench reports help enterprises isolate issues, triage performance problems, and make decisions based on a better understanding of the customer. .
Begin straight away with your name and the company’s presentations. To maintain your customers’ and prospects’ confidence, personalize your scripts by piquing their interests. This is essential for effective customer communication. Also, agents should avoid the classical “Hello,” which immediately freezes discussion.
Top features include screen sharing (for presentations) and on-screen collaboration (for documents). If you’ve ever encountered a customer support agent who’s been using a script, then you know how frustrated your customers will feel if your agents do the same. Leverage Digital Programs and Tools.
For example, conversation intelligence tools can automatically scan conversations and detect whether any agents are deviating from the script. This results in data blind spots and gaps that will remain there indefinitely, unless you do something about them.
Where I’m helping the leader themselves to sort of present their views in a better way. So, instead of presenting the technology as a solution that adds value, it’s quite often just being presented as a sort of cost reduction strategy because we can deflect away from having to pay for contact center agents.
And when we look at the present, it seems ages since we have started using these cutting-edge technologies in our day-to-day lives. For long, call centers have been performance-based, depending on a combination of well-thought scripting and close supervision to reduce call times and maximize first-call resolution. contact-form-7].
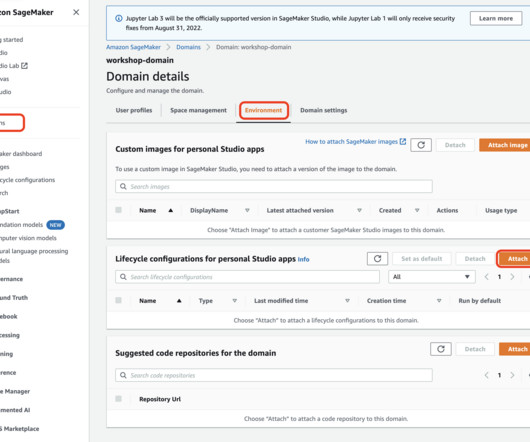
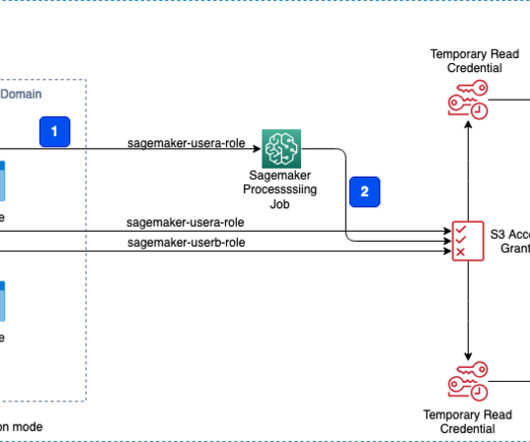
In the User profiles section, verify that the userA and userB profiles are present. This will open a new Python notebook, which we use to run the PySpark script. SageMaker Processing jobs allow you to run distributed data processing workloads while using the access grants you set up earlier. preprocess.py
That’s why customer service agents need to be present, active, and alert on these channels. A properly scripted menu leads customers to the answers they need, provides them with the opportunity to navigate to a live agent, and decreases the overall call volume that reaches the call center. BigData is Getting Bigger.
Create slide decks, presentations, digital material, weekly blogs, and scripts for animations and videos. Highly developed organizational, time management, presentation, and planning skills. Experience and/or knowledge of AI, BigData, Tech. Preferred Skills & Experience. Social Horsepower, gaggleamp).
Deploying these models in real-world scenarios presents significant challenges, particularly in ensuring accuracy, fairness, relevance, and mitigating hallucinations. We then present a typical evaluation workflow, followed by our AWS-based solution that facilitates this process. To start, open the UI in your browser.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content