This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Run the script init-script.bash : chmod u+x init-script.bash./init-script.bash init-script.bash This script prompts you for the following: The Amazon Bedrock knowledge base ID to associate with your Google Chat app (refer to the prerequisites section). The script deploys the AWS CDK project in your account.
Build your training script for the Hugging Face SageMaker estimator. script to use with Script Mode and pass hyperparameters for training. Thanks to our custom inference script hosted in a SageMaker endpoint, we can generate several summaries for this review with different text generation parameters. If we use an ml.g4dn.16xlarge
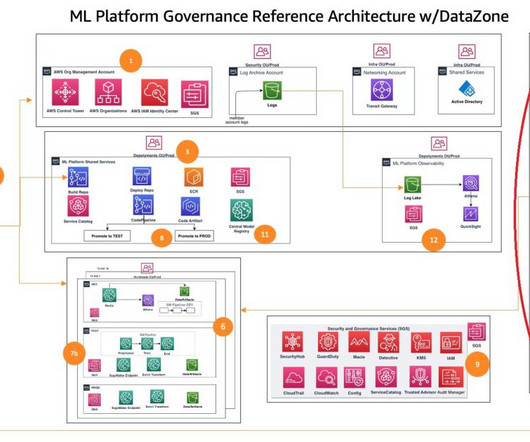
Challenges in data management Traditionally, managing and governing data across multiple systems involved tedious manual processes, custom scripts, and disconnected tools. This approach was not only time-consuming but also prone to errors and difficult to scale.
We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw. For example, to use the RedPajama dataset, use the following command: wget [link] python nemo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py
from time import gmtime, strftime experiment_suffix = strftime('%d-%H-%M-%S', gmtime()) experiment_name = f"credit-risk-model-experiment-{experiment_suffix}" The processing script creates a new MLflow active experiment by calling the mlflow.set_experiment() method with the experiment name above. fit_transform(y).
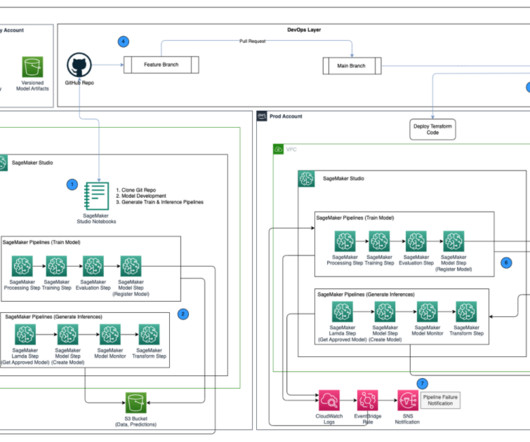
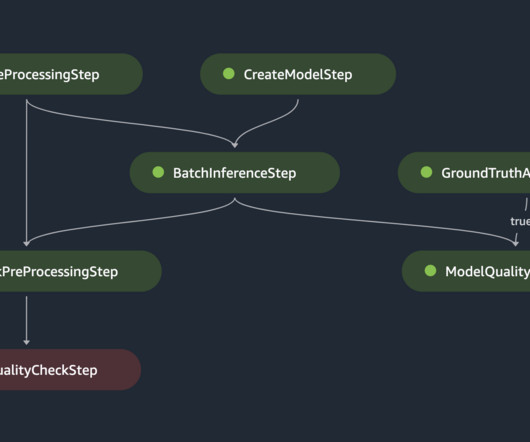
Batch transform The batch transform pipeline consists of the following steps: The pipeline implements a data preparation step that retrieves data from a PrestoDB instance (using a data preprocessing script ) and stores the batch data in Amazon Simple Storage Service (Amazon S3).
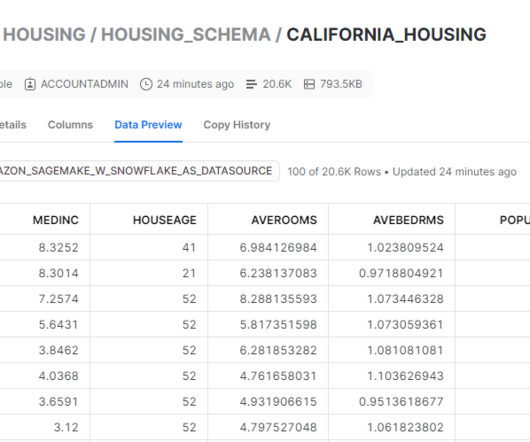
We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket. 1 with the following additions: The Snowflake Connector for Python to download the data from the Snowflake table to the training instance.
You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices. framework/createmodel/ – This directory contains a Python script that creates a SageMaker model object based on model artifacts from a SageMaker Pipelines training step. script is used by pipeline_service.py The model_unit.py
Under Advanced Project Options , for Definition , select Pipeline script from SCM. For Script Path , enter Jenkinsfile. upload_file("pipelines/train/scripts/raw_preprocess.py","mammography-severity-model/scripts/raw_preprocess.py") s3_client.Bucket(default_bucket).upload_file("pipelines/train/scripts/evaluate_model.py","mammography-severity-model/scripts/evaluate_model.py")
SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. Customers can also access offline store data using a Spark runtime and perform bigdata processing for ML feature analysis and feature engineering use cases. Table formats provide a way to abstract data files as a table.
The business analyst’s role is to evaluate the customer experience and then identify how to improve the customer experience either with software changes or call center script changes. They can assess how current scripts are performing and change them as needed. There would be no operations without customers.
After downloading the latest Neuron NeMo package, use the provided neox and pythia pre-training and fine-tuning scripts with optimized hyper-parameters and execute the following for a four node training. Before joining AWS, he worked at Baidu research as a distinguished scientist and the head of Baidu BigData Laboratory.
A Harvard Business Review study found that companies using bigdata analytics increased profitability by 8%. While this statistic specifically addresses data-centric strategies, it highlights the broader value of well-structured technical investments.
We live in an era of bigdata, AI, and automation, and the trends that matter in CX this year begin with the abilities – and pain points – ushered in by this technology. For example, bigdata makes things like hyper-personalized customer service possible, but it also puts enormous stress on data security.
default_bucket() upload _path = f"training data/fhe train.csv" boto3.Session().resource("s3").Bucket To see more information about natively supported frameworks and script mode, refer to Use Machine Learning Frameworks, Python, and R with Amazon SageMaker. resource("s3").Bucket Bucket (bucket).Object Object (upload path).upload
Today, CXA encompasses various technologies such as AI, machine learning, and bigdata analytics to provide personalized and efficient customer experiences. The development of chatbots, automated email responses, and AI-driven customer support tools marked a new era in customer service automation.
We first fetch any additional packages, as well as scripts to handle training and inference for the selected task. You can use any number of models pre-trained on the same task with a single inference script. Finally, the pre-trained model artifacts are separately fetched with model_uris , which provides flexibility to the platform.
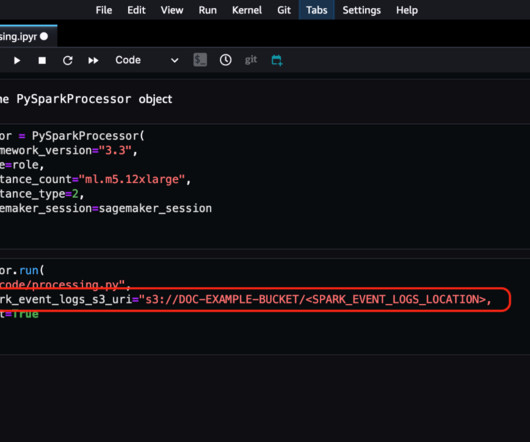
Amazon SageMaker offers several ways to run distributed data processing jobs with Apache Spark, a popular distributed computing framework for bigdata processing. install-scripts chmod +x install-history-server.sh./install-history-server.sh script and attach it to an existing SageMaker Studio domain.
The one-size-fit-all script no longer cuts it. Technology is also creating new opportunities for contact centers to not only better serve customers but also gain deep insights through BigData. With analytics, contact centers can leverage their data to see trends, understand preferences and even predict future requirements.
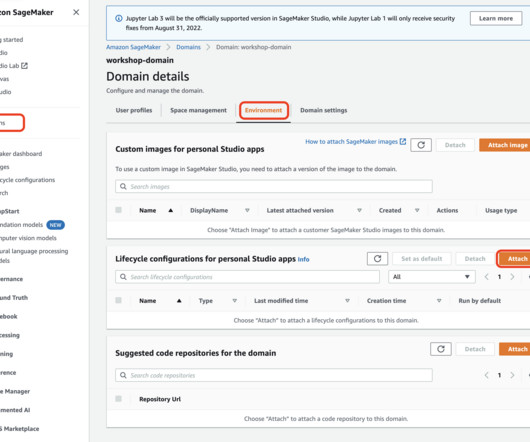
When you open a notebook in Studio, you are prompted to set up your environment by choosing a SageMaker image, a kernel, an instance type, and, optionally, a lifecycle configuration script that runs on image startup. The main benefit is that a data scientist can choose which script to run to customize the container with new packages.
We use the custom terminology dictionary to compile frequently used terms within video transcription scripts. Yaoqi Zhang is a Senior BigData Engineer at Mission Cloud. Adrian Martin is a BigData/Machine Learning Lead Engineer at Mission Cloud. Here’s an example.
Developers usually test their processing and training scripts locally, but the pipelines themselves are typically tested in the cloud. One of the main drivers for new innovations and applications in ML is the availability and amount of data along with cheaper compute options. Build your pipeline.
Data I/O design SageMaker interacts directly with Amazon S3 for reading inputs and storing outputs of individual steps in the training and inference pipelines. The pipeline will automatically upload Python scripts from the GitLab repository and store output files or model artifacts from each step in the appropriate S3 path.
About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice. He helps customers implement bigdata, machine learning, analytics solutions, and generative AI solutions. To learn more about how to use generative AI with AWS services, see Generative AI on AWS.
Accordingly, I expect to see a range of new solutions see the light of day in 2018; solutions that bring the old solutions like Interactive Voice Response (cue the robotic ‘press 1 for English’ script) into the 21 st century, on a channel people actually like to use.
To create these packages, run the following script found in the root directory: /build_mlops_pkg.sh He entered the bigdata space in 2013 and continues to explore that area. Her specialization is machine learning, and she is actively working on designing solutions using various AWS ML, bigdata, and analytics offerings.
We fetch any additional packages, as well as scripts to handle training and inference for the selected task. You can use any number of models pre-trained for the same task with a single training or inference script. Fine-tune the pre-trained model. He’s passionate about building AI services for computer vision.
We first fetch any additional packages, as well as scripts to handle training and inference for the selected task. You can use any number of models pre-trained on the same task with a single inference script. Finally, the pre-trained model artifacts are separately fetched with model_uris , which provides flexibility to the platform.
We found that we didn’t need to separate data preparation, model training, and prediction, and it was convenient to package the whole pipeline as a single script and use SageMaker processing.
Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data. You need data engineering expertise and time to develop the proper scripts and pipelines to wrangle, clean, and transform data. He has a background in AI/ML & bigdata.
The triggers need to be scheduled to write the data to S3 at a period frequency based on the business need for training the models. Prior joining AWS, as a Data/Solution Architect he implemented many projects in BigData domain, including several data lakes in Hadoop ecosystem.
Amazon CodeWhisperer currently supports Python, Java, JavaScript, TypeScript, C#, Go, Rust, PHP, Ruby, Kotlin, C, C++, Shell scripting, SQL, and Scala. times more energy efficient than the median of surveyed US enterprise data centers and up to 5 times more energy efficient than the average European enterprise data center.
You can also find the script on the GitHub repo. He helps organizations in achieving specific business outcomes by using data and AI, and accelerating their AWS Cloud adoption journey. He has extensive experience across bigdata, data science, and IoT, across consulting and industrials.
The second script accepts the AWS RAM invitations to discover and access cross-account feature groups from the owner level. His expertise spans a broad spectrum, encompassing scalable architectures, distributed computing, bigdata analytics, micro services and cloud infrastructures for organizations.
Populate the data Run the following script to populate the DynamoDB tables and Amazon Cognito user pool with the required information: /scripts/setup/fill-data.sh The script performs the required API calls using the AWS Command Line Interface (AWS CLI) and the previously configured parameters and profiles.
During each training iteration, the global data batch is divided into pieces (batch shards) and a piece is distributed to each worker. Each worker then proceeds with the forward and backward pass defined in your training script on each GPU.
TechSee’s technology combines AI with deep machine learning, proprietary algorithms, and BigData to deliver a scalable cognitive system that becomes smarter with every customer support interaction. Customers answer questions in a simple Q&A format, which in many cases leads to a problem solution.
Before you can write scripts that use the Amazon Bedrock API, you’ll need to install the appropriate version of the AWS SDK in your environment. His expertise is in building BigData and AI-powered solutions to customer problems especially in biomedical, life sciences and healthcare domain. Nihir Chadderwala is a Sr.
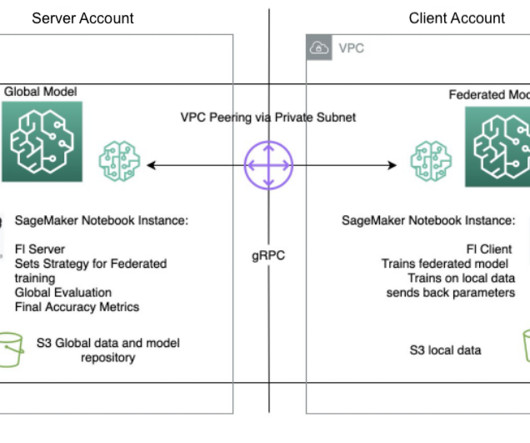
The notebook instance client starts a SageMaker training job that runs a custom script to trigger the instantiation of the Flower client, which deserializes and reads the server configuration, triggers the training job, and sends the parameters response. script and a utils.py The client.py We use utility functions in the utils.py
How to Revolutionize Customer Employee Engagement with BigData and Gamification by Rajat Paharia. focuses on how to use bigdata and gamification to engage your customers more than ever before. Free Download] Live Chat Scripts to Make Stellar Agents. Loyalty 3.0:
We are also seeing the influx of bigdata and the switch to mobile. These are the innate functional limitations of every non-human "system" Namely, no matter how advanced a piece of customer service software is, there are always situations in which its script is not able to make certain leaps that biology is capable of.
Teradata Listener is intelligent, self-service software with real-time “listening ” capabilities to follow multiple streams of sensor and IoT data wherever it exists globally, and then propagate the data into multiple platforms in an analytical ecosystem. Teradata Integrated BigData Platform 1800.
Security is a big-data problem. As soon as a download attempt is made, it triggers the malicious executable script to connect to the attacker’s Command and Control server. With the built-in algorithm for XGBoost , you can do this without any additional custom script.
The Data Analyst Course With the Data Analyst Course, you will be able to become a professional in this area, developing all the necessary skills to succeed in your career. The course also teaches beginner and advanced Python, basics and advanced NumPy and Pandas, and data visualization.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























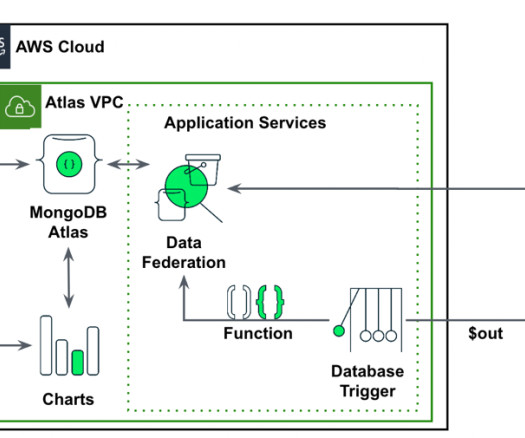
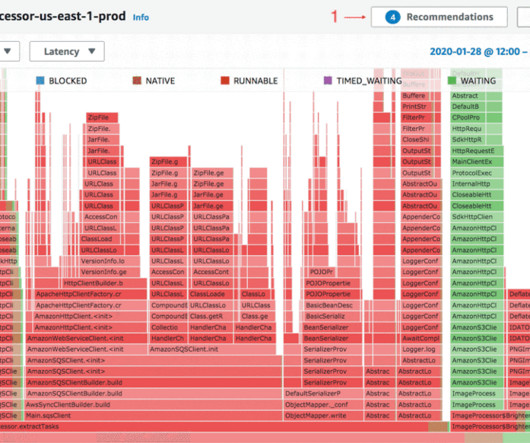

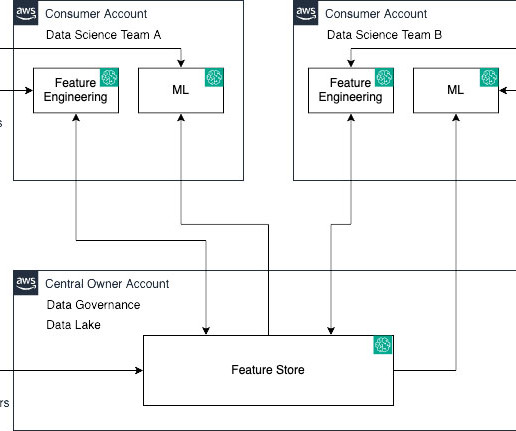

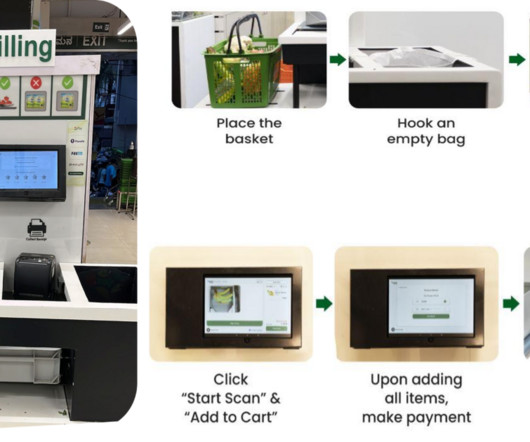
















Let's personalize your content