This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Bill Dettering is the CEO and Founder of Zingtree , a SaaS solution for building interactive decision trees and agent scripts for contact centers (and many other industries). Interactive agent scripts from Zingtree solve this problem. Agents can also send feedback directly to script authors to further improve processes.
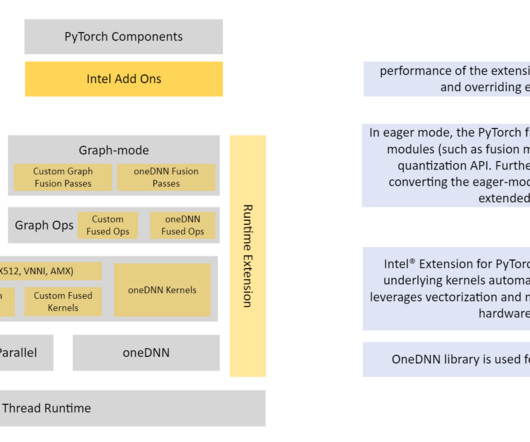
Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions. In this case, you are calibrating the model with the SQuAD dataset: model.eval() conf = ipex.quantization.QuantConf(qscheme=torch.per_tensor_affine) print("Doing calibration.")
Writing a call script is a must for contact centers that want to excel in their prospecting effort. If you write it according to the rules of the game, the script is an observable, cost-effective, and efficient method of attracting and maintaining prospects and clients. What exactly is call scripting? Why do scripts exist?
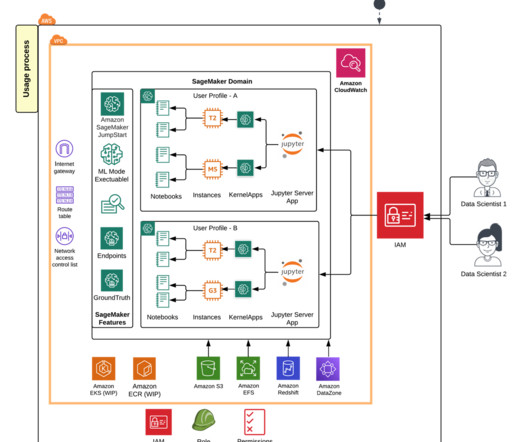
Such a pipeline encompasses the stages involved in building, testing, tuning, and deploying ML models, including but not limited to data preparation, feature engineering, model training, evaluation, deployment, and monitoring. This MLOps accelerator enhances the native capabilities of JumpStart by integrating complementary AWS services.
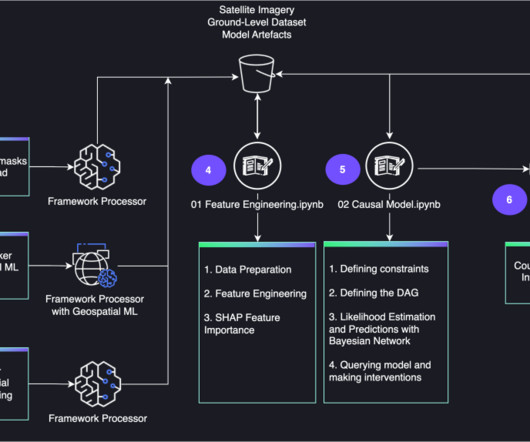
We now carry out feature engineering steps and then fit the model. The model training consists of two components: a feature engineering step that processes numerical, categorical, and text features, and a model fitting step that fits the transformed features into a Scikit-learn random forest classifier.
The causal inference engine is deployed with Amazon SageMaker Asynchronous Inference. The database was calibrated and validated using data from more than 400 trials in the region. For further details, refer to the feature extraction script. Initial nitrogen concentration in the soil was set randomly among a reasonable range.
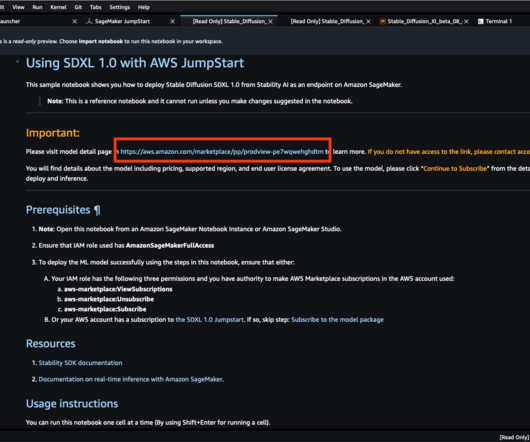
It’s designed for professional use, and calibrated for high-resolution photorealistic images. offers SageMaker optimized scripts and container with faster inference time and can be run on smaller instance compared to the open weight SDXL 1.0. is the latest image generation model from Stability AI. Choose the SDXL 1.0
We also created a Python script that makes HTTP inference requests to the REST API, with our test data as input data. This adds a useful calibration to our model. Prior to joining AWS, she was a tech lead and senior full-stack engineer building data-intensive distributed systems on the cloud. file in the solution’s source code.
When processing large-scale data, data scientists and ML engineers often use PySpark , an interface for Apache Spark in Python. SageMaker provides prebuilt Docker images that include PySpark and other dependencies needed to run distributed data processing jobs, including data transformations and feature engineering using the Spark framework.
Evaluating these models allows continuous model improvement, calibration and debugging. After the selection of the model(s), prompt engineers are responsible for preparing the necessary input data and expected output for evaluation (e.g. input prompts comprising input data and query) and define metrics like similarity and toxicity.
If you dont have an AWS account, follow the instructions to create one, unless you have been provided event engine details. script can run by executing the command chmod 755./deploy.sh. Its important to calibrate Ragas evaluation judgement as Human in the Lopp. You can use prompt engineering to guide the LLM more effectively.
Theres a risk of reverse engineering or data leakage if not properly implemented. It works by injecting calibrated noise into the data generation process, making it virtually impossible to infer anything about a single data point or confidential information in the source dataset.
The steering geometry, the differentials, the lack of engineering precision of the A979, and the corresponding difficulty in calibrating it, causes gap #4. Even if the model wants to go straight, the car still pulls left or right, needing constant correction to stay on track.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content