This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metrics, Measure, and Monitor – Make sure your metrics and associated goals are clear and concise while aligning with efficiency and effectiveness. Make each metric public and ensure everyone knows why that metric is measured. Interactive agent scripts from Zingtree solve this problem. Bill Dettering.
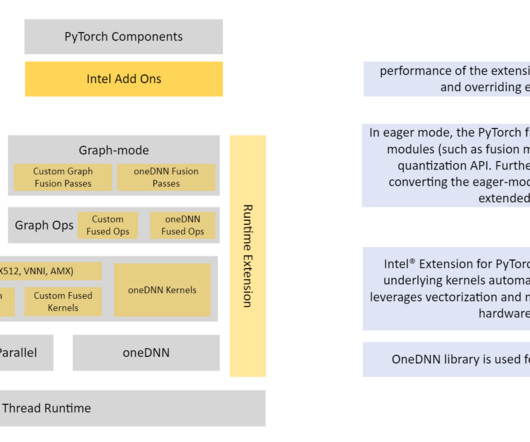
Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions. In this case, you are calibrating the model with the SQuAD dataset: model.eval() conf = ipex.quantization.QuantConf(qscheme=torch.per_tensor_affine) print("Doing calibration.")
You can either have a manual approver or set up an automated approval workflow based on metrics checks in the aforementioned reports. We now explore this script in more detail. Values passed to arguments can be parsed using standard methods like argparse and will be used throughout the script.
Organizations must create performance management and employee development programs that use customer relationship metrics to drive their service delivery. For the last few years Customer Relationship Metrics has been helping clients implement a modern QA model called Impact Quality Assurance (iQA). In the Early Years.
3 Calibrate Quality Evaluations and Metrics. Central to the QM function is the evaluation of contacts for regulatory compliance, adherence to scripting and qualitative features like professionalism, product knowledge and empathy. That doesn’t mean SMB call centers should give up on accurate measurement, though!
Note that the probability returned by this model has not been calibrated. Calibration is a useful property in certain circumstances, but isn’t required in cases where discrimination between cases of churn and non-churn is sufficient. CalibratedClassifierCV from Scikit-learn can be used to calibrate a model. BERT + Random Forest.
AV/ADAS teams need to label several thousand frames from scratch, and rely on techniques like label consolidation, automatic calibration, frame selection, frame sequence interpolation, and active learning to get a single labeled dataset. This includes scripts for model loading, inference handling etc.
Essential Components of a Winning QA Program A comprehensive QA program includes several key elements: Clear Standards and Metrics: Define quality for your organization. Consider both objective and subjective metrics. A financial services company integrated their QA data with customer feedback and operational metrics.
The database was calibrated and validated using data from more than 400 trials in the region. The parent nodes are field-related parameters (including the day of sowing and area planted), and the child nodes are yield, nitrogen uptake, and nitrogen leaching metrics. The following figure illustrates these metrics.
The key metrics you track are objective. Instead, the objective metric is a hard data point you use to quantify pieces of your agent’s performance. Do your agent performance tiles ( like these ) tell you that one agent consistently sits at the bottom of his peer group on important metrics like AHT and FCR? DO calibrate often.
Every step of the process can be calibrated to minimize the agent’s effort, from dialing the number to logging the call in the CRM. Use Case: The Automatic Preview Dialer is highly versatile, adding time efficiency to complex campaigns where agents need to review client data before the call, take notes, personalize scripts, and so on.
Lastly, we compare the classification result with the ground truth labels and compute the evaluation metrics. Because our dataset is imbalanced, we use the evaluation metrics balanced accuracy , Cohen’s Kappa score , F1 score , and ROC AUC , because they take into account the frequency of each class in the data. Balanced accuracy.
When you experiment with different metrics and track improvement over time, you set yourself up for success. Good parameters are measurable and clearly defined (something you can test through calibration sessions with management, supervisors, and reps – post on this coming soon). Did your rep: Follow the greeting script.
You can use Spark UIs or CloudWatch instance metrics and logs to calibrate these values over multiple run iterations. In this example pipeline, the PySpark script spark_process.py (as shown in the following code) loads a CSV file from Amazon S3 into a Spark data frame, and saves the data as Parquet back to Amazon S3.
The project was designed to use the same data collection method with the same survey script for both contact centers. As the study progressed and agent-level feedback was collected by “Contact Center A”, the results for this metric were dramatic. You know what happens when you don’t have their trust.
Furthermore, these data and metrics must be collected to comply with upcoming regulations. They need evaluation metrics generated by model providers to select the right pre-trained model as a starting point. Evaluating these models allows continuous model improvement, calibration and debugging.
Iteratively refine the code by: Reviewing for accuracy and efficiency Adjusting prompts as needed Incorporating developer input for complex scenarios The result is a tailored script that generates synthetic data entries matching your specific requirements and closely mimicking real-world data in your domain.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content