This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
How can businesses move beyond customer satisfaction metrics? When employees or businesses let pride take precedence, they block out constructive feedback and hinder growth. Quotes: “Before you think about customer satisfaction scores and metrics, focus on truly understanding the customer.
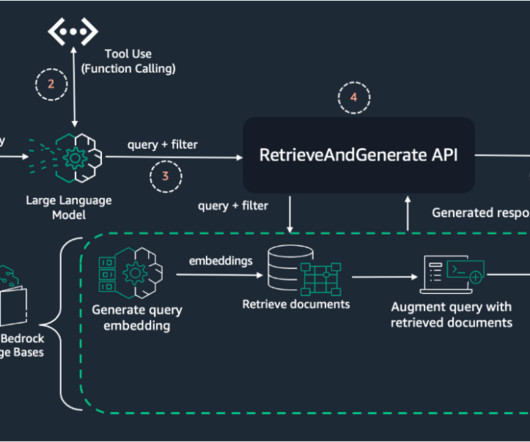
In some use cases, particularly those involving complex user queries or a large number of metadata attributes, manually constructing metadata filters can become challenging and potentially error-prone. By implementing dynamic metadata filtering, you can significantly improve these metrics, leading to more accurate and relevant RAG responses.
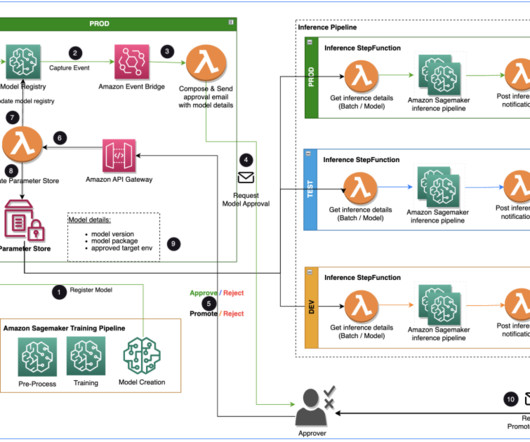
The following diagram depicts an architecture for centralizing model governance using AWS RAM for sharing models using a SageMaker Model Group , a core construct within SageMaker Model Registry where you register your model version. The ML admin sets up this table with the necessary attributes based on their central governance requirements.
So, in other words, when your customers feel these, you can get blips of improvement in your “value” metrics. We did some work with a construction equipment manufacturer. They were dealing with construction people. From our research that we did with London Business School, these emotions drive short-term spend.
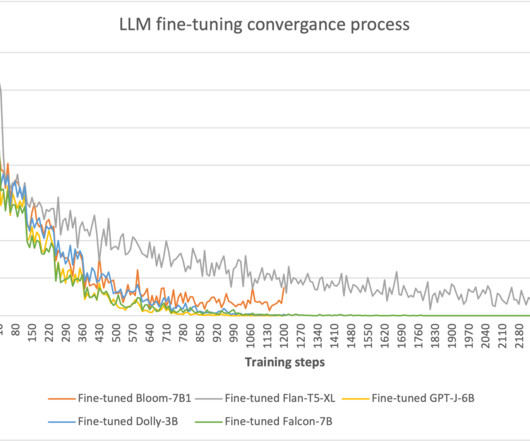
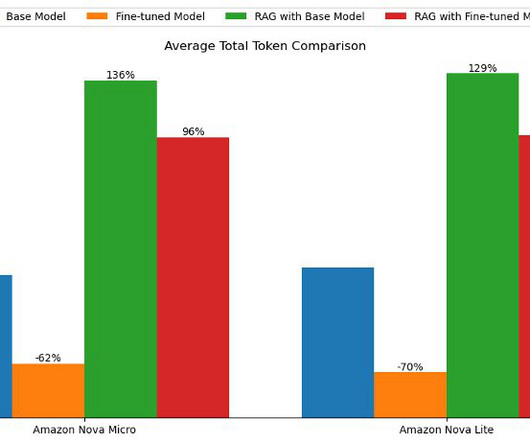
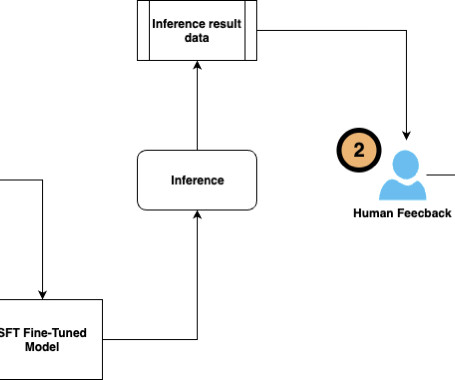
The Amazon EU Design and Construction (Amazon D&C) team is the engineering team designing and constructing Amazon Warehouses across Europe and the MENA region. Fine-tuned LLM – We constructed the training dataset from the documents and contents and conducted fine-tuning on the foundation model.
According to Marketing Metrics , you have a much higher probability to sell your existing customers than a new prospect, at 60 to 70% versus 5 to 20%, respectively. According to their 2014 US Insurance Shopping study, 28% of the Customers who switched auto insurance providers did so because of “poor experience.”.
Thanks to this construct, you can evaluate any LLM by configuring the model runner according to your model. Evaluation algorithm Computes evaluation metrics to model outputs. Different algorithms have different metrics to be specified. For example, spider plots are often used to make visual comparison across multiple metrics.
32) can’t take complaints constructively. Marc Zaragozas , encouraging us not to lose sight of our customers amid all of the metrics adds: 33) if they prioritize internal processes and metrics over customer satisfaction and needs. Rod Mitchell , resetting one of our greatest priorities says: 22) fail to put the employee first.
Constructing and evolving these processes is the second category of capabilities on the ESG Customer Success Maturity Model. Metrics that track your customers’ experience are crucial to the stability and longevity of your CS organization. CX (NPS, CSAT, etc.).
While NPS is beneficial in many ways, people focus too hard on the metric and lose sight of the big picture. For example, our Emotional Signature ® Research process revealed what motivated their customers to work with a construction equipment manufacturing company. We discovered in our conversation that Reichheld feels the same way.
Give constructive feedback. That’s why constructive feedback is critical to your team’s development. Balancing positive and constructive feedback is key — you can find more tips on this here. It can be easy to get caught up in the analytics and metrics of performance. Stop exclusively focusing on numbers.
Companies that are most successful in this area, Triant says, are the ones that implement the technology to track these metrics from the get-go. Using that data to construct a model or predictive theory about what that history tells you about the person’s motives, emotions, and understanding of your organization’s offering.
Unfortunately, Reichheld says too many organizations use NPS as a stick or a metric for earning bonuses. He says that the financial metrics most companies use for valuations point you toward the wrong investments. His new metric concept is called Earned Growth Rate. Several industries use this metric already.
Under Input data , enter the location of the source S3 bucket (training data) and target S3 bucket (model outputs and training metrics), and optionally the location of your validation dataset. To do so, we create a knowledge base. For Job name , enter a name for the fine-tuning job.
Performance Feedback and Coaching Once audits are completed, share results with agents to provide constructive feedback. Improved Agent Performance: Provide targeted training and constructive feedback. Q5: What metrics are essential for call auditing? Highlight strengths while addressing areas needing improvement.
Some Customer Success metrics are considered standard but there’s often more than meets the eye. Sales and marketing professionals that geek out on metrics can find themselves in deep philosophical debates about the best numbers to track. That nuance is derived from three underlying factors: Construct.
These days, there are tons of key performance indicators (KPIs) and call center metrics to evaluate call center performance and call center agent performance. Net promoter score (NPS) is a metric that measures the likelihood of a customer recommending the company to friends, family, and colleagues. Net promoter score (NPS).
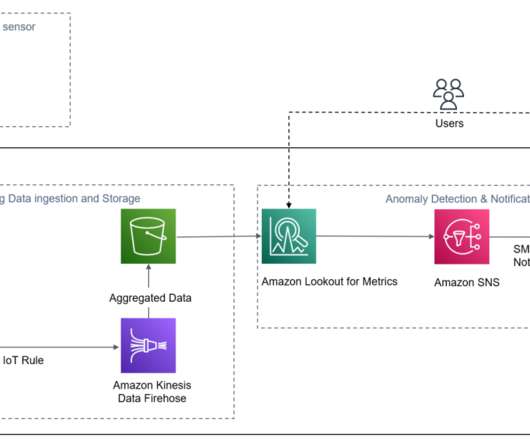
This post shows you how to use an integrated solution with Amazon Lookout for Metrics and Amazon Kinesis Data Firehose to break these barriers by quickly and easily ingesting streaming data, and subsequently detecting anomalies in the key performance indicators of your interest. You don’t need ML experience to use Lookout for Metrics.
For enterprises, a well-constructed customer health score isnt just a nice-to-have; its a strategic asset that empowers teams to manage complexity, sustain customer satisfaction, and scale their customer success efforts. Maintain predictable retention metrics while identifying cross-sell or upsell opportunities.
Enhances Call Center Performance Improves key metrics such as average handle time (AHT) and customer satisfaction scores (CSAT). Provide constructive feedback on areas for improvement. How Training Impacts Call Center Performance Metrics 1. Reduces response times and improves problem-solving abilities.
Performance metrics analysis: This involves tracking and benchmarking key performance indicators (KPIs) such as customer satisfaction, average handle time, first-call resolution, and call compliance adherence as indicated on QA scorecards and dashboards.
The Amazon EU Design and Construction (Amazon D&C) team is the engineering team designing and constructing Amazon warehouses. This method was described in A generative AI-powered solution on Amazon SageMaker to help Amazon EU Design and Construction. AI score 4.5 out of 5.
Where discrete outcomes with labeled data exist, standard ML methods such as precision, recall, or other classic ML metrics can be used. These metrics provide high precision but are limited to specific use cases due to limited ground truth data. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
Constructing SQL queries from natural language isn’t a simple task. Figure 2: High level database access using an LLM flow The challenge An LLM can construct SQL queries based on natural language. Figure 2: High level database access using an LLM flow The challenge An LLM can construct SQL queries based on natural language.
This means understanding the metrics that need to be monitored, transcribed, and analyzed in order to glean actionable insights. . Average speed of answer is one of the most important metrics for call centers to measure. Included in this metric is the time a caller waits in a queue. Proper measurement should consider outliers.
It is essential to keep principles of survey design in mind when constructing questionnaires or polls. This means that before you even begin constructing your survey, you should take some time to think through and clearly define what result you want to achieve with this survey. Metric selection. Principles of Survey Design.
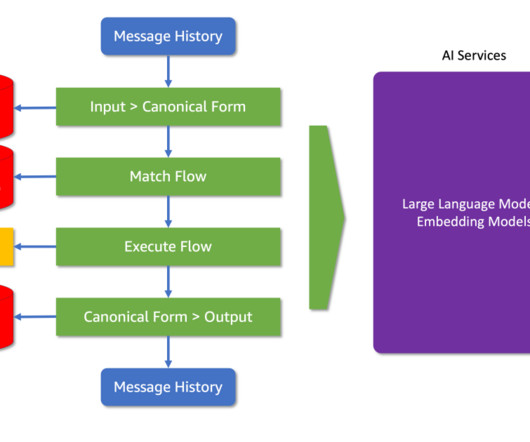
Colang is purpose-built for simplicity and flexibility, featuring fewer constructs than typical programming languages, yet offering remarkable versatility. It leverages natural language constructs to describe dialogue interactions, making it intuitive for developers and simple to maintain. Integrating Llama 3.1
Metrics for Evaluating Contact Center Agent Performance. Most commonly used in call centers, this metric can help you gain insights on the responsiveness and efficiency of your agents. This metric is a great way to track how efficiently your agents are managing their time at work. Where should you begin? Occupancy Rate.
Identify nuanced sentiment: AI detects subtle emotional cues, providing a deeper understanding of customer satisfaction beyond surface-level metrics. Ensure agents fully understand these standards, including the metrics used for evaluation. Transparency and clarity are paramount for agents to perform at their best.
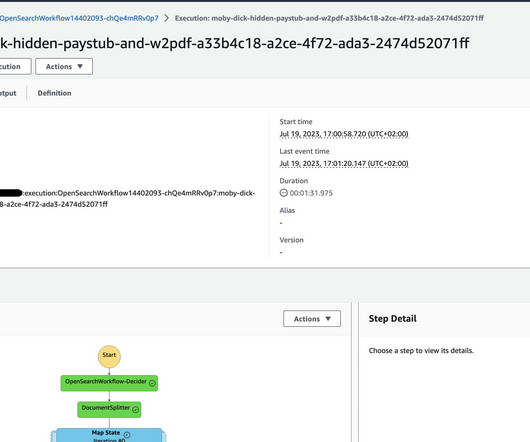
The implementation used in this post utilizes the Amazon Textract IDP CDK constructs – AWS Cloud Development Kit (CDK) components to define infrastructure for Intelligent Document Processing (IDP) workflows – which allow you to build use case specific customizable IDP workflows. The default deployment uses m6g.large.search instances.
Take advantage of this phenomenon by constructing your scripts to promote positive responses.” They are an easy way to track metrics and discover trends within your agents. They fall into the same bucket as quality, call control, customer satisfaction, absenteeism and other metrics. This is short-sighted.
The EventBridge model registration event rule invokes a Lambda function that constructs an email with a link to approve or reject the registered model. The post-inference notification Lambda function collects batch inference metrics and sends an email to the approver to promote the model to the next environment.
Graphs and charts benchmark accuracy is based on business reports and presentations constructed internally. Design files benchmark accuracy is based on a product design retrieval dataset constructed internally. Recall@5 is a specific metric used in information retrieval evaluation, including in the BEIR benchmark.
Provide control through transparency of models, guardrails, and costs using metrics, logs, and traces The control pillar of the generative AI framework focuses on observability, cost management, and governance, making sure enterprises can deploy and operate their generative AI solutions securely and efficiently.
Agents today can aspire to develop their careers in areas such as: Team Leadership: Guiding and mentoring teams to meet performance metrics and drive exceptional customer experiences. How to discuss contact center career growth with agents Having open and constructive conversations about career growth is crucial.
Building a business case from an economical standpoint can be a challenge: What metrics should you consider in calculating the true cost of outsourcing? Armed with data that clearly shows the benefits of outsourcing your customer service, the more confident you can be in constructing an airtight business case.
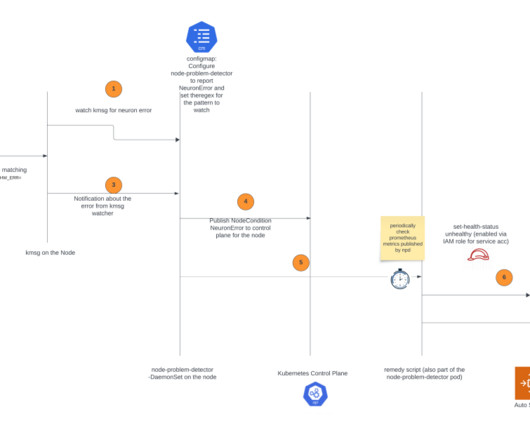
The node recovery agent is a separate component that periodically checks the Prometheus metrics exposed by the node problem detector. Additionally, the node recovery agent will publish Amazon CloudWatch metrics for users to monitor and alert on these events. You can see the CloudWatch NeuronHasError_DMA_ERROR metric has the value 1.
After defining the entities and edges between the entities, you can create mag_bert.json , which defines the graph schema, and invoke the built-in graph construction pipeline construct_graph in GraphStorm to build the graph (see the following code). TB RAM) to construct the OAG graph. on the test set of the constructed graph.
The 4 Most Important Call Center Agent Performance Metrics 1. This call center metric is an essential gauge of customer perception — how they perceive your product and service. As with many of these call center metrics, CES is a good indicator, but rife with nuance. Still, many managers use this back to front.
The sheer number of metrics make it hard to filter down to ones that are truly relevant for their use-cases. Amazon SageMaker Clarify now provides AWS customers with foundation model (FM) evaluations, a set of capabilities designed to evaluate and compare model quality and responsibility metrics for any LLM, in minutes.
Customer support teams work with clients to fix these issues in real-time, helping them to find a solution while documenting the problem in-question—all while providing a friendly, constructive experience. As a result, you can provide offers even before customers realize they have a need for them.
Give them constructive feedback on how they’re performing day-to-day and as a teammate. In-line feedback is incredibly constructive and allows your agents to see the specific phrases they could have edited or what questions they should have asked to get more clarity. For larger contact centers, you may have to make 1:1s monthly.
Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5% on the Massive Multitask Language Understanding (MMLU) reasoning benchmark, surpassing a number of larger models according to Mistral.
Constructive feedback can both encourage and engage agents to perform with higher scores and furnish more adorable customer service with improving customer satisfaction. Employee performance depends on the contact center performance management, and providing constructive feedback is one of the essential tools on the path to increasing it.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content