This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
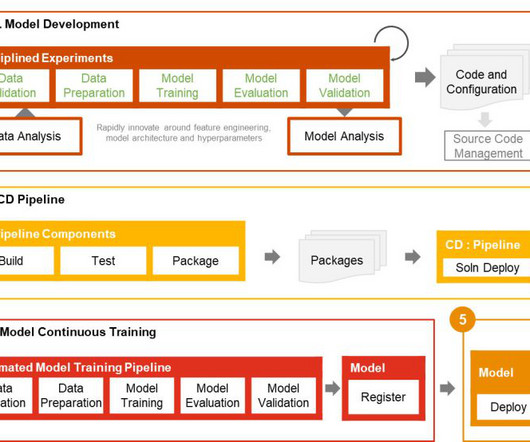
Many businesses already have data scientists and ML engineers who can build state-of-the-art models, but taking models to production and maintaining the models at scale remains a challenge. It involves taking the result of an experiment or prototype and turning it into a production system with standard controls, quality, and feedback loops.
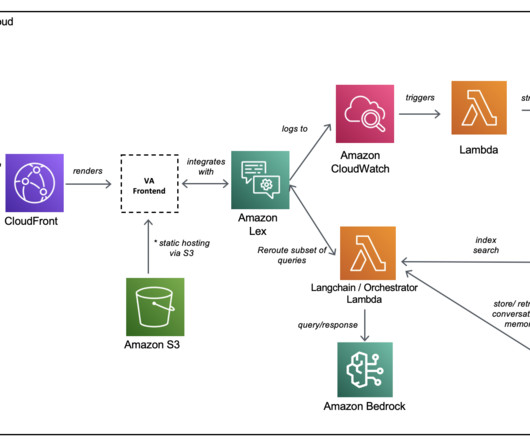
Data is ingested into the platform as a bulk upload on day 0 and then incremental uploads day 1+. The following diagram illustrates the solution architecture. Data source We created an Amazon Kendra index and added a data source using web crawler connectors with a root web URL and directory depth of two levels.
We continue to be customer obsessed, offering important features to customers based on their feedback. Noah Gift, Executive in Residence at Duke MIDS (Data Science). Eda Johnson, Partner IndustrySolutions Manager at Snowflake. Customer success stories. Get started with SageMaker Studio Lab.
And various marketing and research companies use them to conduct surveys and take feedback. As per the latest data , U.S. In later years, STIR/SHAKEN was developed jointly by the SIP Forum and the Alliance for Telecommunications IndustrySolutions (ATIS) to efficiently implement the Internet Engineering Task Force (IETF).
By tailoring recommendations based on individuals preferences, the solution guides customers toward the best vehicle model for them. Simultaneously, it empowers vehicle manufacturers (original equipment manufacturers (OEMs)) by using real customer feedback to drive strategic decisions, boosting sales and company profits.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. The training data must be formatted in a JSON Lines (.jsonl) from sagemaker.s3 from sagemaker.s3
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content