This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
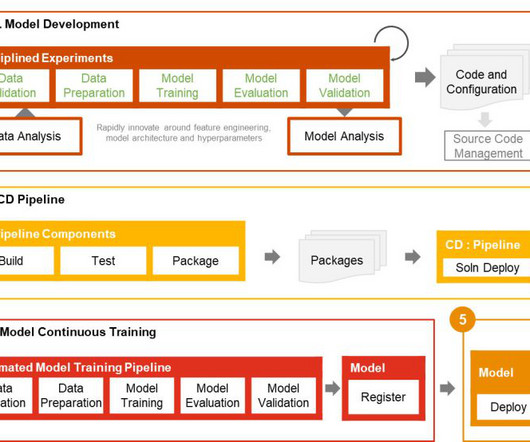
Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models. Data science and DevOps teams may face challenges managing these isolated tool stacks and systems.
Many businesses already have data scientists and ML engineers who can build state-of-the-art models, but taking models to production and maintaining the models at scale remains a challenge. Data and model management provide a central capability that governs ML artifacts throughout their lifecycle.
Bosch is a multinational corporation with entities operating in multiple sectors, including automotive, industrialsolutions, and consumer goods. Because neural forecasters are trained on historical data, the forecasts generated based on out-of-distribution data from the more volatile periods could be inaccurate and unreliable.
Data scientists typically carry out several iterations of experimentation in data processing and training models while working on any ML problem. Data scientists typically carry out several iterations of experimentation in data processing and training models while working on any ML problem.
Inefficient Business Processes: Complex approval chains, inconsistent data, and convoluted system workflows slow down sales. Sales data gets scattered across systems. Different processes and data formats make consolidation difficult. Centralized Pricing Management: Pricing data gets consolidated within CPQ.
Each model has different features, price points, and performance metrics, making it difficult to make a confident choice that fits their needs and budget. These reports contain vast amounts of data, which can be overwhelming and time-consuming to analyze.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. The training data must be formatted in a JSON Lines (.jsonl) from sagemaker.s3 from sagemaker.s3
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















Let's personalize your content