This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Many organizations believe that a simple document holder or database with a search bar is a knowledge management system. Key Features of a KMS Heres what makes a KMS the game-changer in todays contact centers: Speed of Delivery: Unlike traditional document holders, a KMS is designed to deliver answers within seconds.
In this post, we focus on one such complex workflow: document processing. Rule-based systems or specialized machine learning (ML) models often struggle with the variability of real-world documents, especially when dealing with semi-structured and unstructured data.
A large portion of that information is found in text narratives stored in various document formats such as PDFs, Word files, and HTML pages. Some information is also stored in tables (such as price or product specification tables) embedded in those same document types, CSVs, or spreadsheets.
The last thing they want is for your agent to be scrolling through a never-ending document or searching through 10 articles to find the right answer or walking through a 20 page process to complete a customer interaction. Instead of storing more documents, focus on creating an environment where agents can access the right answers quickly.
To find how contact centers are navigating the transition to omnichannel customer service, Calabrio surveyed more than 1,000 marketing and customer experience leaders in the U.S. about their digital customer communication strategies. Read the report to find out what was uncovered.
QA teams should support the contact center by defining, documenting, standardizing, and simplifying all performance expectations. With the backing of senior leadership, the Quality Team is responsible not only for the clarity of these guidelines but also for the training and calibration of all team leaders to meet these standards.
” “Your customers can now know more about your company than you do by using AI to scrape your website and documentation. If you had a magic wand, what would you want to do for your customers that you can’t do today? And, how can AI enable that?”
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
This is the scenario for companies that rely on manual processes for document generationcaught in a cycle of repetitive data entry, missing critical details, non-compliance, and whatnot. Every document you produce is an opportunity to reinforce your brands identity, tone, and professionalism. What is Document Generation Software?
A recent Calabrio research study of more than 1,000 C-Suite executives has revealed leaders are missing a key data stream – voice of the customer data. Download the report to learn how executives can find and use VoC data to make more informed business decisions.
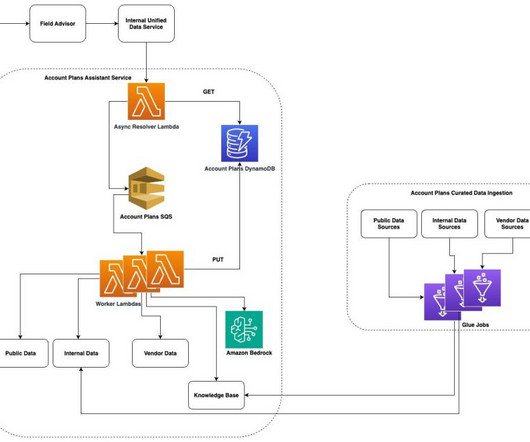
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. For queries earning negative feedback, less than 1% involved answers or documentation deemed irrelevant to the original question.
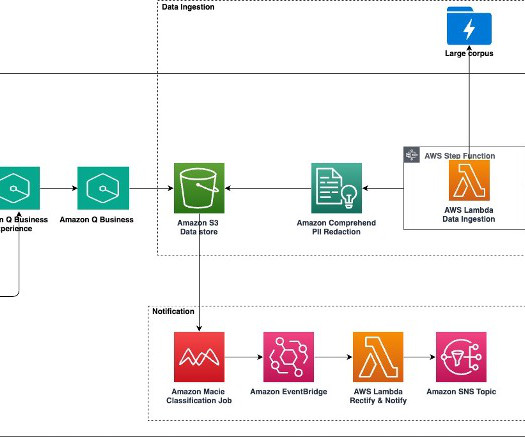
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
Google Drive supports storing documents such as Emails contain a wealth of information found in different places, such as within the subject of an email, the message content, or even attachments. Types of documents Gmail messages can be sorted and stored inside your email inbox using folders and labels.
Compile the most frequently asked questions in a shared document, determine the best possible answers, and distribute the document to your customer service team. . This document will act as a single source of truth your team can reference. Are you finding any patterns in questions or concerns stated over social media?
What does it take to engage agents in this customer-centric era? Download our study of 1,000 contact center agents in the US and UK to find out what major challenges are facing contact center agents today – and what your company can do about it.
When designing a process, use the following steps to build something that is scalable: Create a simple flow chart that documents each step in the process. For each step, identify the following items: Systems needed. What computer systems are required? If there is a limit on how fast something can be processed, what is it?
The vision document is critical to set the direction for your team, so you need to make it clear. Also, make it available at all times through your company’s document sharing service. Include an explanation of each touchpoint in a separate document. Make it step-by-step to include every communication touchpoint.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
We changed the line the new policy representatives said from, “You should receive your policy documents in five working days,” to “You will receive your policy documents in five working days.”
This document will help you and your team narrow the field, with detail on the full impact your proposed CCaaS platforms can make on your operations, plus open-ended probing questions that get you better, more insightful responses than a simple “yes”. This guide covers: Omnichannel & Inbound.
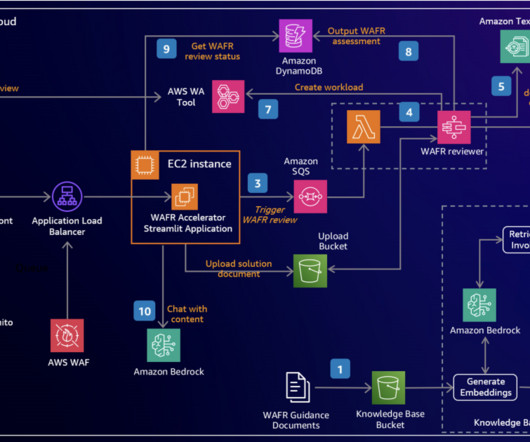
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
The following is an example FlowMultiTurnInputRequestEvent JSON object: { "nodeName": "Trip_planner", "nodeType": "AgentNode", "content": { "document": "Certainly! The following is an example FlowOutputEvent JSON object: { "nodeName": "FlowOutputNode", "content": { "document": "Great news! I've successfully booked your flight to Paris.
Every year, AWS Sales personnel draft in-depth, forward looking strategy documents for established AWS customers. These documents help the AWS Sales team to align with our customer growth strategy and to collaborate with the entire sales team on long-term growth ideas for AWS customers.
Site monitors conduct on-site visits, interview personnel, and verify documentation to assess adherence to protocols and regulatory requirements. However, this process can be time-consuming and prone to errors, particularly when dealing with extensive audio recordings and voluminous documentation.
What to identify, document and share. This webinar will explore 4 strategies that contact center leaders can use to lead and coach their agents and supervisors to stay ahead of the productivity curve. In this webinar, you will know: How to build the necessary interpersonal skills to engender CX behaviors.
We discovered that when customers ordered an insurance policy, the insurance agent would say, “your documentation should be with you within five working days.” ” It turns out the vast majority of people would call back within three days to ask about the documents after this interaction.
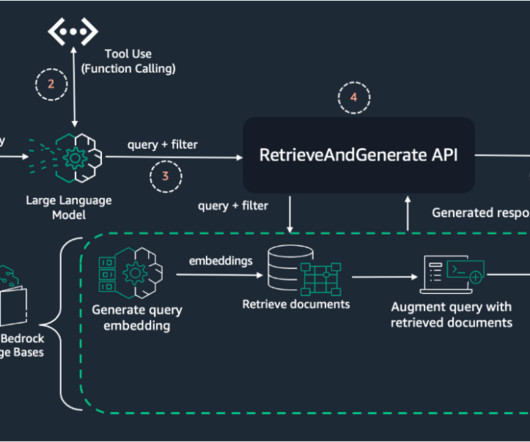
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
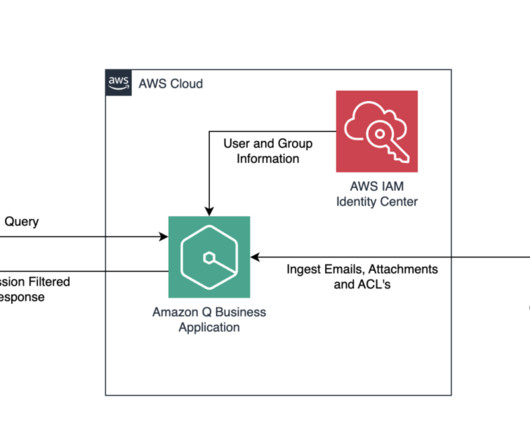
AWS customers and partners innovate using Amazon Q Business in Europe Organizations across the EU are using Amazon Q Business for a wide variety of use cases, including answering questions about company data, summarizing documents, and providing business insights. text, pdf, images, tables).
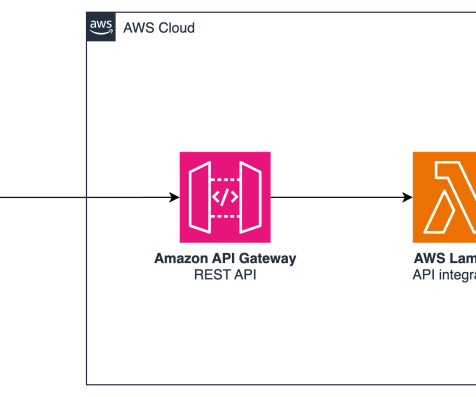
operation.font.set({ name: 'Arial' }); // flush changes to the Word document await context.sync(); }); Generative AI backend infrastructure The AWS Cloud backend consists of three components: Amazon API Gateway acts as an entry point, receiving requests from the Office applications Add-in. Here, we use Anthropics Claude 3.5
Speaker: Peter Armaly - Senior Director and Advisor of Customer Success at Oracle
Customer success is a well-established practice in the enterprise business world (70% of companies have a dedicated team, according to TSIA) and the benefits it delivers to customers are real and well-documented. So why is there still ongoing debate and angst about customer success not being treated as an equal partner to its sales peers?
Amazon Bedrock Knowledge Bases has a metadata filtering capability that allows you to refine search results based on specific attributes of the documents, improving retrieval accuracy and the relevance of responses. Improving document retrieval results helps personalize the responses generated for each user.
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
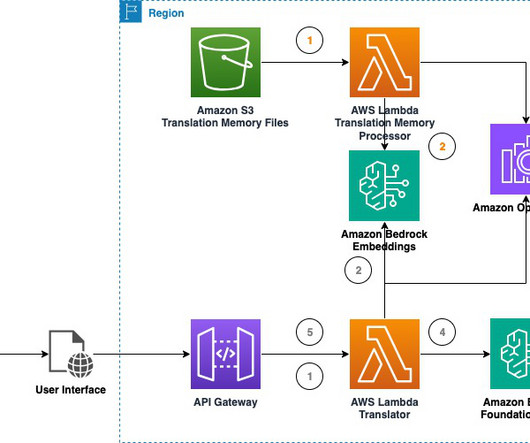
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. For this post, we use a document store. Choose With Document Store.
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. This solution uses the powerful capabilities of Amazon Q Business.
A survey of 1,000 contact center professionals reveals what it takes to improve agent well-being in a customer-centric era. This report is a must-read for contact center leaders preparing to engage agents and improve customer experience in 2019.
Your task is to understand a system that takes in a list of documents, and based on that, answers a question by providing citations for the documents that it referred the answer from. Our dataset includes Q&A pairs with reference documents regarding AWS services. The following table shows an example.
Broadly speaking, a retriever is a module that takes a query as input and outputs relevant documents from one or more knowledge sources relevant to that query. Document ingestion In a RAG architecture, documents are often stored in a vector store. You must use the same embedding model at ingestion time and at search time.
Use Customer Science to document how your efforts work or don’t. The pandemic accelerated changes for all businesses over the past few months, including increased cloud computing use, digital transformations, and the impending rollout of 5G. Without science, you can’t be sure what causes the needle to move in either direction.
Optimized for search and retrieval, it streamlines querying LLMs and retrieving documents. Build sample RAG Documents are segmented into chunks and stored in an Amazon Bedrock Knowledge Bases (Steps 24). For this purpose, LangChain provides a WebBaseLoader object to load text from HTML webpages into a document format.
Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB. Key components include: Orchestrated document processing with AWS Step Functions – The document processing workflow begins with AWS Step Functions , which orchestrates each step in the process.
Document those examples for others to follow. If an employee asks permission for something they weren’t sure they could say yes to, then that should be the last time the employee should ever have to ask permission for anything similar. Train by citing examples of actual interactions between employees and customers.
To use Automated Reasoning checks, you first create an Automated Reasoning policy by encoding a set of logical rules and variables from available source documentation. Automated Reasoning checks deliver deterministic verification of model outputs against documented rules, complete with audit trails and mathematical proof of policy adherence.
Document them, and determine if they are an anomaly or brewing bigger issues. Look at the entire customer journey to determine the possible friction points and proactively make it better behind the scenes to create a seamless customer experience. Make a note of the issues that happen often. Treat your customers as partners.
Here’s how it significantly elevates healthcare faxing: HIPAA-Compliant Storage: Using Microsoft SharePoint, Momentum securely stores faxed documents with end-to-end encryption, fully meeting HIPAA standards for PHI. This ensures critical patient information is accessible anytime, anywhere, enabling seamless continuity of care.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content