This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At the heart of most technological optimizations implemented within a successful call center are fine-tuned metrics. Keeping tabs on the right metrics can make consistent improvement notably simpler over the long term. However, not all metrics make sense for a growing call center to monitor. Peak Hour Traffic.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
Customer satisfaction and net promoter scores are helpful metrics, but the after-call survey is the most immediate resource. You might have a carefully crafted questionnaire or script for your after-call survey. It offers your call center a well-documented view of response rates, survey answers, and timing information.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics?
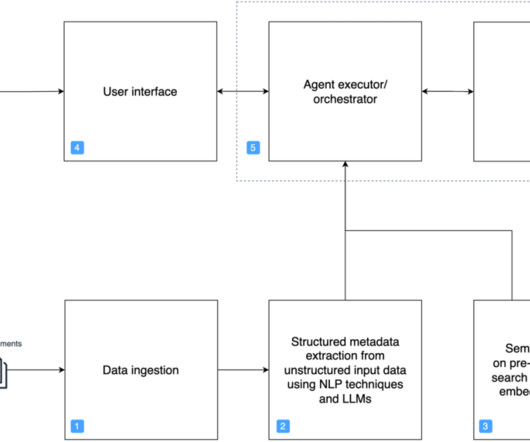
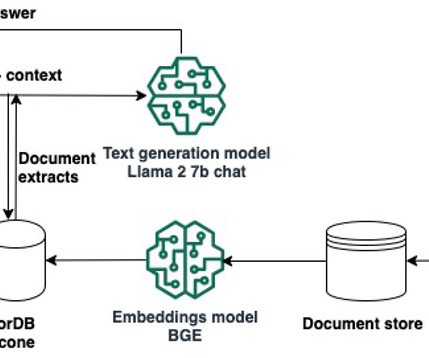
Broadly speaking, a retriever is a module that takes a query as input and outputs relevant documents from one or more knowledge sources relevant to that query. Document ingestion In a RAG architecture, documents are often stored in a vector store. You must use the same embedding model at ingestion time and at search time.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. These metrics provide high precision but are limited to specific use cases due to limited ground truth data.
Encourage agents to cheer up callers with more flexible scripting. “A 2014 survey suggested that 69% of customers feel that their call center experience improves when the customer service agent doesn’t sound as though they are reading from a script. They are an easy way to track metrics and discover trends within your agents.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
Organizations across industries such as retail, banking, finance, healthcare, manufacturing, and lending often have to deal with vast amounts of unstructured text documents coming from various sources, such as news, blogs, product reviews, customer support channels, and social media. Extract and analyze data from documents.
But without numbers or metric data in hand, coming up with any new strategy would only consume your valuable time. For example, you need access to metrics like NPS, average response time and others like it to make sure you come up with relevant strategies that help you retain more customers. So, buckle up. 1: Customer Churn Rate. #2:
For automatic model evaluation jobs, you can either use built-in datasets across three predefined metrics (accuracy, robustness, toxicity) or bring your own datasets. For early detection, implement custom testing scripts that run toxicity evaluations on new data and model outputs continuously.
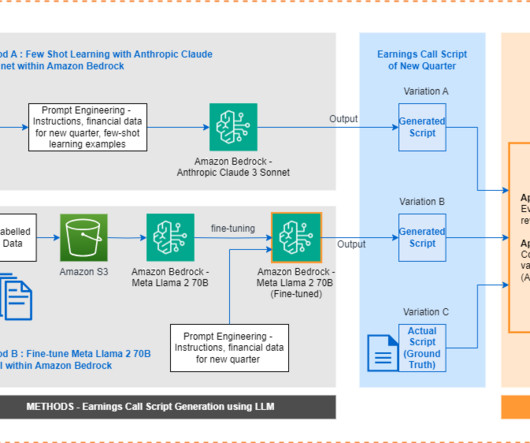
Investors and analysts closely watch key metrics like revenue growth, earnings per share, margins, cash flow, and projections to assess performance against peers and industry trends. Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time.
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. Who are the data stewards for my proprietary database sources?
In addition to HIPAA compliance, training should also cover emergency protocols, medical terminology , and documentation best practices. One of the ways of establishing clear protocols is to provide standardized scripts that can help agents assess the nature of each call accurately.
We also included a data exploration script to analyze the length of input and output tokens. For demonstration purposes, we select 3,000 samples and split them into train, validation, and test sets. You need to run the Load and prepare the dataset section of the medusa_1_train.ipynb to prepare the dataset for fine-tuning.
Call Recording Efficient call center for lawyers integrated automated call recording software to allow teams to document client interactions for compliance, quality assurance , and evidence. With the warm transfer option, the agents can transfer the conversation to the right department even before the potential customer picks up the phone.
Improving your customer service metrics requires a deeper look at which KPIs make sense for your contact center and the strategies you use to achieve them. What Call Center Metrics Should You Measure? You can use this metric to identify peak volume as well. You can use this metric to identify peak volume as well.
Consequently, no other testing solution can provide the range and depth of testing metrics and analytics. And testingRTC offers multiple ways to export these metrics, from direct collection from webhooks, to downloading results in CSV format using the REST API. Happy days! You can check framerate information for video here too.
Training on SageMaker We use PyTorch and Amazon SageMaker script mode to train this model. Script mode’s compatibility with PyTorch was crucial, allowing us to use our existing scripts with minimal modifications. After you have defined your training script, you can configure and submit a SageMaker training job.
Batch transform The batch transform pipeline consists of the following steps: The pipeline implements a data preparation step that retrieves data from a PrestoDB instance (using a data preprocessing script ) and stores the batch data in Amazon Simple Storage Service (Amazon S3). The evaluation step uses the evaluation script as a code entry.
Sell, Sell, Sell in the Contact Center With These Three Customer Care Metrics – Three ways to tactfully sell in the contact center. The Longest Lasting Emotions in Customer Experience – Research shows when you make your customers sad, they remember for a long time. See what other customer emotions linger. Photo Credit: [link].
SageMaker Profiler provides Python modules for annotating PyTorch or TensorFlow training scripts and activating SageMaker Profiler. You can also use optional custom annotations to add markers in the training script to visualize hardware activities during particular operations in each step. For more information, refer to documentation.
For instance, to improve key call center metrics such as first call resolution , business analysts may recommend implementing speech analytics solutions to improve agent performance management. That requires involvement in process design and improvement, workload planning and metric and KPI analysis. Kirk Chewning. kirkchewning.
The Executive Guide to Improving 6 Contact Center Metrics. Keep them up to date on new policies, best customer support practices, adjustments to the call center script, and more. As a contact center leader, it’s easy to get caught up in high-level metrics and reports. Improve the Customer Journey.
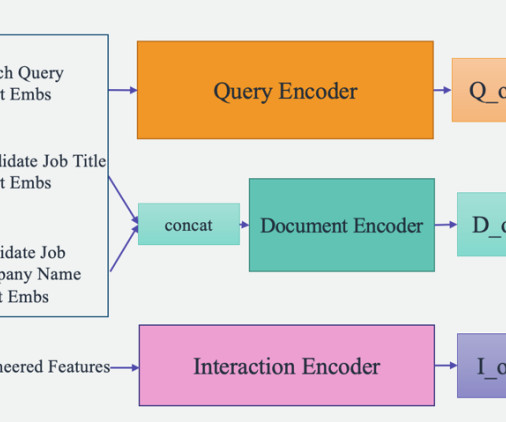
We use the standard engineered features as input into the interaction encoder and feed the SBERT derived embedding into the query encoder and document encoder. Document encoder – The document encoder processes the information of each job listing. This provides a metric of how attractive a particular job or company might be.
It provides a suite of tools for visualizing training metrics, examining model architectures, exploring embeddings, and more. TensorFlow and PyTorch projects both endorse and use TensorBoard in their official documentation and examples. is your training script, and simple_tensorboard.ipynb launches the SageMaker training job.
Solution overview In this section, we present a generic architecture that is similar to the one we use for our own workloads, which allows elastic deployment of models using efficient auto scaling based on custom metrics. The reverse proxy collects metrics about calls to the service and exposes them via a standard metrics API to Prometheus.
Additionally, you need to define which underlying metric fits best for your task and you want to optimize for (such as accuracy, F1 score, or ROC). How does the combination of certain hyperparameter values influence my performance metric? We opted for providing our own Python script and using Scikit-learn as our framework.
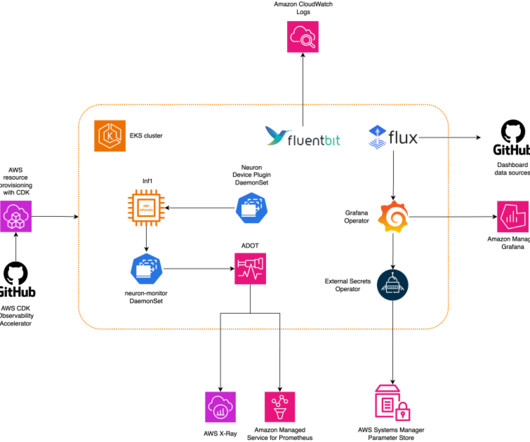
Metrics allow teams to understand workload behavior and optimize resource allocation and utilization, diagnose anomalies, and increase overall infrastructure efficiency. Metrics are exposed to Amazon Managed Service for Prometheus by the neuron-monitor DaemonSet, which deploys a minimal container, with the Neuron tools installed.
Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions. To access the code and documentation, refer to the GitHub repo. py scripts for testing. Create a Docker image to deploy the model in SageMaker using the BYOC approach.
From there, we dive into how you can track and understand the metrics and performance of the SageMaker endpoint utilizing Amazon CloudWatch metrics. Metrics to track. Before we can get into load testing, it’s essential to understand what metrics to track to understand the performance breakdown of your SageMaker endpoint.
The digital nature of SaaS customer experience means that success outcomes are defined primarily in terms of digital, measurable key performance indicators, such as product usage metrics. Onboarding metrics, such as average time-to-value. Adoption metrics , such as license utilization. Here are five keys to doing it right.
OpenSearch Service allows you to store vectors and other data types in an index, and offers rich functionality that allows you to search for documents using vectors and measuring the semantical relatedness, which we use in this post. OpenSearch Service is a fully managed service that makes it simple to deploy, scale, and operate OpenSearch.
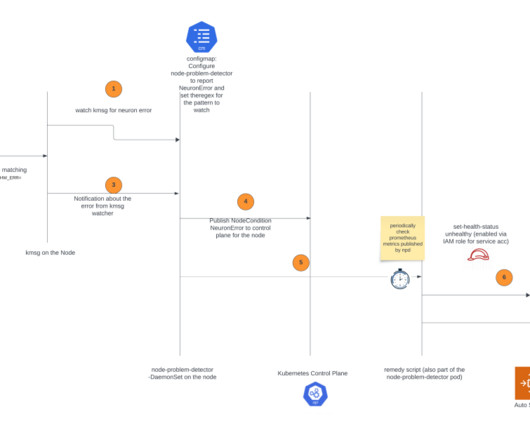
The node recovery agent is a separate component that periodically checks the Prometheus metrics exposed by the node problem detector. Additionally, the node recovery agent will publish Amazon CloudWatch metrics for users to monitor and alert on these events. You can see the CloudWatch NeuronHasError_DMA_ERROR metric has the value 1.
Another example might be a healthcare provider who uses PLM inference endpoints for clinical document classification, named entity recognition from medical reports, medical chatbots, and patient risk stratification. The performance of the architecture is typically measured using metrics such as validation loss. training.py ).
Do agents have access to daily performance metrics? Document important aspects of your call center tech, like what platforms need to be open and key steps to use them, as a reference point for agents when they need help. Update outdated policies, call scripts and processes so your agents have the right resources to help your customers.
Radiology reports are comprehensive, lengthy documents that describe and interpret the results of a radiological imaging examination. For a quantitative analysis of the generated impression, we use ROUGE (Recall-Oriented Understudy for Gisting Evaluation), the most commonly used metric for evaluating summarization.
You can monitor performance metrics such as training and validation loss using Amazon CloudWatch during training. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document. Use Amazon Comprehend to create new products based on understanding the structure of documents.
Amazon Comprehend is a natural-language processing (NLP) service you can use to automatically extract entities, key phrases, language, sentiments, and other insights from documents. All you need to do is load your dataset of documents and annotations, and use the Amazon Comprehend console, AWS CLI, or APIs to create the model.
Customizable environment – SageMaker HyperPod offers the flexibility to customize your cluster environment using lifecycle scripts. These scripts allow you to install additional frameworks, debugging tools, and optimization libraries tailored to your specific needs. accelerate launch train_stage_1.py py --config configs/train/stage1.yaml
Give plenty of tools and resources, like phone scripts and email templates, for a variety of different sales situations and opportunities. However, they also shouldn’t rely too heavily on scripts). This includes documentation they can reference when working independently. Build a Standardized Process .
Performance Optimization – Choosing the appropriate resources, implementing caching strategies, and proactively monitoring performance metrics ensure that applications deliver fast and accurate responses, leading to optimal performance and an enhanced user experience. For latest information, please refer to the documentation above.
A typical RAG solution for knowledge retrieval from documents uses an embeddings model to convert the data from the data sources to embeddings and stores these embeddings in a vector database. When a user asks a question, it searches the vector database and retrieves documents that are most similar to the user’s query.
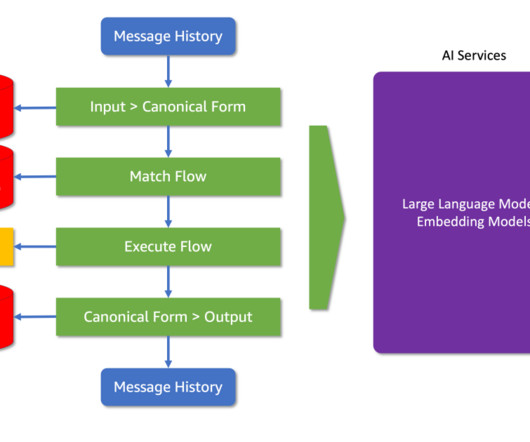
Lets delve into a basic Colang script to see how it works: define user express greeting "hello" "hi" "what's up?" define flow greeting user express greeting bot express greeting bot ask how are you In this script, we see the three fundamental types of blocks in Colang: User Message Blocks (define user ): These define possible user inputs.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content